Algorytm łańcuchowania w przód PL-FC-ENTAILS?(KB,q) określa, czy pojedynczy symbol zdania q – zapytanie – jest związany z bazą wiedzy o określonych klauzulach. Zaczyna się od znanych faktów (dosłownych literałów) w bazie wiedzy. Jeżeli znane są wszystkie przesłanki implikacji, to jej wniosek dodaje się do zbioru znanych faktów. Na przykład, L1,1jeśli i Breeze są znane, a (L11 Λ Breeze) =>B1,1 znajduje się w bazie wiedzy, wtedy można dodać B1,1. Proces ten trwa do momentu dodania zapytania q lub do momentu, gdy nie będzie można wykonać dalszych wnioskowań. Algorytm pokazano na rysunku ; głównym punktem do zapamiętania jest to, że biegnie w czasie liniowym.
Najlepszym sposobem zrozumienia algorytmu jest przykład i obraz. Rysunek (a) przedstawia prostą bazę wiedzy o klauzulach Horna ze znanymi faktami A i B . Rysunek (b) pokazuje tę samą bazę wiedzy narysowaną jako wykres AND–OR.
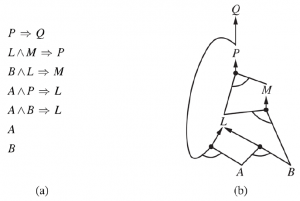
Na wykresach AND–OR wiele krawędzi połączonych łukiem wskazuje na koniunkcję – każda krawędź musi zostać udowodniona — podczas gdy wiele krawędzi bez łuku wskazuje na alternatywę – można udowodnić dowolną krawędź. Na wykresie łatwo jest zobaczyć, jak działa łańcuchowanie w przód. Znane liście (tutaj A i B ) są ustawiane, a wnioskowanie propaguje wykres tak daleko, jak to możliwe. Gdziekolwiek pojawia się koniunkcja, propagacja czeka na poznanie wszystkich koniunkcji przed kontynuowaniem. Zachęcamy czytelnika do szczegółowego przeanalizowania przykładu. Łatwo zauważyć, że łańcuchowanie w przód jest słuszne: każde wnioskowanie jest zasadniczo zastosowaniem Modus Ponens. Łączenie w przód jest również kompletne: każde zdanie atomowe entailed zostanie wyprowadzone. Najprostszym sposobem, aby to zobaczyć, jest rozważenie końcowego stanu wnioskowanej tabeli (po osiągnięciu przez algorytm ustalonego punktu, w którym nie są możliwe nowe wnioskowania). Tabela zawiera prawdę dla każdego symbolu wywnioskowanego podczas procesu i fałsz dla wszystkich innych symboli. Możemy zobaczyć tabelę jako model logiczny; co więcej, w tym modelu prawdziwe są wszystkie określone klauzule w oryginalnym KB. Aby to zobaczyć, załóż coś przeciwnego, a mianowicie, że w modelu jakieś zdanie a1 Λ … Λ ak => b jest fałszywe. Wtedy a1 Λ … Λ ak musi być prawdą w modelu a b musi być fałszem w modelu. Ale to jest sprzeczne z naszym założeniem, że algorytm osiągnął ustalony punkt, ponieważ mielibyśmy teraz licencję na dodawanie b do KB. Możemy zatem wnioskować, że zbiór zdań atomowych wywnioskowanych w punkcie stałym definiuje model oryginalnego KB. Co więcej, każde zdanie atomowe q, które pociąga za sobą KB, musi być prawdziwe we wszystkich jego modelach, a w szczególności w tym modelu. Dlatego każde zdanie atomowe q musi być wywnioskowane przez algorytm.
Forward chaining jest przykładem ogólnej koncepcji wnioskowania opartego na danych – to znaczy wnioskowania, w którym uwaga zaczyna się od znanych danych. Może być używany w agencie do wyciągania wniosków z nadchodzących percepcji, często bez konieczności kierowania konkretnym zapytaniem. Na przykład agent wumpus może PRZEKAZYWAĆ swoje spostrzeżenia do bazy wiedzy za pomocą przyrostowego algorytmu łańcucha do przodu, w którym nowe fakty mogą być dodawane do programu, aby zainicjować nowe wnioskowania. U ludzi pewna ilość rozumowania opartego na danych pojawia się, gdy pojawiają się nowe informacje. Na przykład, jeśli jestem w domu i słyszę, że zaczyna padać deszcz, może mi się wydawać, że piknik zostanie odwołany. Ale chyba nie przyjdzie mi do głowy, że siedemnasty płatek największej róży w ogrodzie sąsiada zmoknie; ludzie trzymają łańcuchy naprzód pod ścisłą kontrolą, aby nie pogrążyć ich w nieistotnych konsekwencjach.
Algorytm wstecznego łańcucha, jak sama nazwa wskazuje, działa wstecz od zapytania. Jeśli wiadomo, że zapytanie q jest prawdziwe, nie jest wymagana żadna praca. W przeciwnym razie algorytm znajduje te implikacje w bazie wiedzy, której wnioskiem jest q . Jeśli wszystkie przesłanki jednej z tych implikacji można udowodnić (poprzez łańcuchowanie wstecz), to q jest prawdziwe. Po zastosowaniu do zapytania Q na powyższym rysunku, działa ono w dół wykresu, aż dotrze do zbioru znanych faktów, A i B, które stanowią podstawę dowodu. Algorytm jest zasadniczo identyczny z algorytmem AND-LUB-GRAPH-SEARCH . Podobnie jak w przypadku łączenia w przód, wydajna implementacja przebiega w czasie liniowym. Łańcuchy wsteczne to forma rozumowania ukierunkowanego na cel. Przydaje się do odpowiadania na konkretne pytania, takie jak „Co mam teraz zrobić?” i „Gdzie są moje klucze?” Często koszt tworzenia łańcucha wstecznego jest znacznie mniejszy niż liniowy w odniesieniu do rozmiaru bazy wiedzy, ponieważ proces dotyczy tylko istotnych faktów.