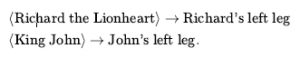Możemy przyjąć fundament logiki zdaniowej – deklaratywnej, kompozycyjnej semantyki niezależnej od kontekstu i jednoznacznej – i zbudować na tym fundamencie bardziej ekspresyjną logikę, zapożyczając idee reprezentacyjne z języka naturalnego, unikając jego wad. Kiedy patrzymy na składnię języka naturalnego, najbardziej oczywistymi elementami są rzeczowniki i wyrażenia rzeczownikowe, które odnoszą się do przedmiotów (kwadraty, doły, wumpuses) oraz czasowniki i frazy czasownikowe wraz z przymiotnikami i przysłówkami, które odnoszą się do relacji między przedmiotami (jest przewiewny, sąsiaduje z pędami). Niektóre z tych relacji są funkcjami – relacjami, w których istnieje tylko jedna „wartość” dla danego „dane wejściowego”. Łatwo jest zacząć wymieniać przykłady obiektów, relacji i funkcji:
* Przedmioty: ludzie, domy, liczby, teorie, Ronald McDonald, kolory, gry w baseball, wojny, wieki…
* Relacje: mogą to być relacje jednoargumentowe lub właściwości, takie jak czerwony, okrągły, fałszywy, pierwszy, wielopiętrowy … lub bardziej ogólne relacje -arne, takie jak brat, większy niż, wewnątrz, część, ma kolor, wystąpił po, posiada, wchodzi pomiędzy, …
* Funkcje: ojciec, najlepszy przyjaciel, trzecia runda, jeszcze jedna, początek …
Rzeczywiście, prawie każde stwierdzenie może być traktowane jako odnoszące się do przedmiotów i właściwości lub relacji. Oto kilka przykładów:
* „Jeden plus dwa równa się trzy”. Przedmioty: jeden, dwa, trzy, jeden plus dwa; Relacja: równa się; Funkcja: plus. („Jeden plus dwa” to nazwa obiektu otrzymywana przez zastosowanie funkcji „plus” do obiektów „jeden” i „dwa”. „Trzy” to inna nazwa tego obiektu.)
* „Kwadraty sąsiadujące z wumpusem śmierdzą”. Obiekty: wumpusy, kwadraty; Właściwość: śmierdząca; Relacja: sąsiedztwo.
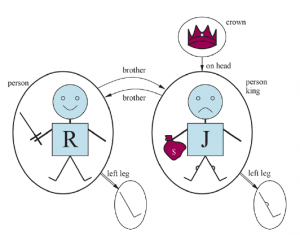
* „Zły król Jan rządził Anglią w 1200 roku”. Obiekty: Jan, Anglia, 1200; Relacja: rządził podczas; Właściwości: zło, król.
Język logiki pierwszego rzędu, którego składnię i semantykę zdefiniujemy w następnym podrozdziale, zbudowany jest wokół obiektów i relacji. Było to ważne dla matematyki, filozofii i sztucznej inteligencji właśnie dlatego, że te dziedziny – a nawet większość codziennej ludzkiej egzystencji – można pożytecznie traktować jako zajmujące się przedmiotami i relacjami między nimi. Logika pierwszego rzędu może również wyrażać fakty dotyczące niektórych lub wszystkich obiektów we wszechświecie. Umożliwia to reprezentowanie ogólnych praw lub zasad, takich jak stwierdzenie „Kwadraty sąsiadujące z wumpusem są śmierdzące”. Podstawowa różnica między logiką zdaniową a logiką pierwszego rzędu leży w ontologicznym zobowiązaniu każdego języka — to znaczy w tym, co on zakłada na temat natury rzeczywistości. Matematycznie to zobowiązanie wyraża się w naturze modeli formalnych, w odniesieniu do których określa się prawdziwość zdań. Na przykład logika zdań zakłada, że istnieją fakty, które albo obowiązują w świecie, albo nie. Każdy fakt może być w jednym z dwóch stanów – prawda lub fałsz – i każdy model przypisuje prawdę lub fałsz każdemu symbolowi zdania . Logika pierwszego rzędu zakłada więcej; mianowicie, że świat składa się z przedmiotów, które mają między sobą pewne relacje, które utrzymują się lub nie. Modele formalne są odpowiednio bardziej skomplikowane niż te dla logiki zdań. To ontologiczne zobowiązanie jest wielką siłą logiki (zarówno propozycjonalnej, jak i pierwszego rzędu), ponieważ pozwala nam zacząć od prawdziwych stwierdzeń i wywnioskować inne prawdziwe. Jest szczególnie skuteczny w dziedzinach, w których każde twierdzenie ma wyraźne granice, takich jak matematyka lub świat wumpusów, gdzie kwadrat albo ma wgłębienie, albo nie; nie ma możliwości kwadratu z niejasnym wcięciem przypominającym wgłębienie. Ale w prawdziwym świecie wiele propozycji ma niejasne granice: Czy Wiedeń jest dużym miastem? Czy ta restauracja służy pysznym jedzeniem? Czy ta osoba jest wysoka? To zależy, kogo zapytasz, a ich odpowiedź może być „w pewnym sensie”. Jedną z odpowiedzi jest udoskonalenie reprezentacji: jeśli prymitywna linia dzieląca miasta na „duże” i „niewielkie” pozostawia zbyt wiele informacji dla danej aplikacji, można zwiększyć liczbę kategorii rozmiaru lub użyć symbolu funkcji populacji. Inne proponowane rozwiązanie pochodzi z logiki rozmytej, która zakłada ontologiczne zobowiązanie, że zdania mają stopień prawdziwości od 0 do 1. Na przykład zdanie „Wiedeń to duże miasto” może być prawdziwe w stopniu 0,8 w logice rozmytej, podczas gdy „Paryż to duże miasto” może mieć wartość 0,9. Odpowiada to lepiej naszej intuicyjnej koncepcji świata, ale utrudnia wnioskowanie: zamiast jednej reguły do ustalenia prawdziwości A Λ B , logika rozmyta potrzebuje różnych reguł w zależności od dziedziny. Inną możliwością, opisaną , jest przypisanie każdej koncepcji do punktu w przestrzeni wielowymiarowej, a następnie zmierzenie odległości między pojęciem „duże miasto” a pojęciem „Wiedeń” lub „Paryż”. Różne logiki specjalnego przeznaczenia czynią jeszcze dalsze zobowiązania ontologiczne; na przykład logika temporalna zakłada, że fakty zachodzą w określonych czasach i że te czasy (które mogą być punktami lub odstępami) są uporządkowane. Zatem logiki specjalnego przeznaczenia nadają pewnym rodzajom obiektów (i aksjomatów na ich temat) status „pierwszej klasy” w logice, zamiast po prostu definiować je w bazie wiedzy. Logika wyższego rzędu postrzega relacje i funkcje, do których odwołuje się logika pierwszego rzędu, jako same w sobie obiekty. Pozwala to na wysuwanie twierdzeń o wszystkich relacjach – na przykład można by chcieć zdefiniować, co to znaczy, że relacja jest przechodnia. W przeciwieństwie do większości logik specjalnego przeznaczenia, logika wyższego rzędu jest ściślej bardziej ekspresyjna niż logika pierwszego rzędu, w tym sensie, że niektóre zdania logiki wyższego rzędu nie mogą być wyrażone przez dowolną skończoną liczbę zdań logicznych pierwszego rzędu. Logikę można też scharakteryzować przez jej epistemologiczne zobowiązania – możliwe stany wiedzy, na które pozwala w odniesieniu do każdego faktu. Zarówno w logice zdaniowej, jak i pierwszego rzędu, zdanie reprezentuje fakt, a podmiot albo wierzy, że zdanie jest prawdziwe, wierzy, że jest fałszywe, albo nie ma opinii. Logiki te mają zatem trzy możliwe stany wiedzy o każdym zdaniu. Z drugiej strony systemy wykorzystujące teorię prawdopodobieństwa mogą mieć dowolny stopień przekonania lub subiektywnego prawdopodobieństwa, od 0 (całkowite niewiara) do 1 (całkowite przekonanie). Ważne jest, aby nie mylić stopnia wiary w teorię prawdopodobieństwa ze stopniem prawdziwości logiki rozmytej. Rzeczywiście, niektóre systemy rozmyte dopuszczają niepewność (stopień wiary) co do stopni prawdy. Na przykład, probabilistyczny agent świata wumpusa może sądzić, że wumpus jest w [1,3] z prawdopodobieństwem 0,75 i w [2, 3] z prawdopodobieństwem 0,25 (chociaż wumpus jest zdecydowanie w jednym konkretnym kwadracie).