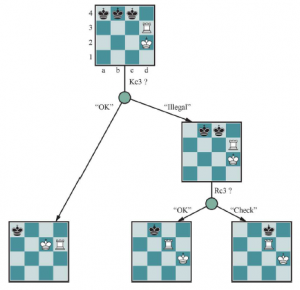
Najprostszy rodzaj CSP obejmuje zmienne, które mają dyskretne, skończone domeny. Problemy z kolorowaniem map i planowanie z ograniczeniami czasowymi są tego rodzaju. Problem 8 hetmanów (rysunek 4.3 ) można również postrzegać jako CSP o skończonej dziedzinie, w którym zmienne Q1,…,Qs odpowiadają królowym w kolumnach od 1 do 8, a dziedzina każdej zmiennej określa możliwy wiersz liczby dla hetmana w tej kolumnie, D1={1,2,3,4,5,6,7,8} . Ograniczenia mówią, że żadne dwie hetmany nie mogą znajdować się w tym samym rzędzie lub po przekątnej. Dyskretna domena może być nieskończona, na przykład zbiór liczb całkowitych lub łańcuchów. (Gdybyśmy nie określili ostatecznego terminu problemu planowania zadań, byłaby nieskończona liczba czasów rozpoczęcia dla każdej zmiennej.) W przypadku nieskończonych dziedzin musimy użyć niejawnych ograniczeń, takich jak T1 + d1 ≤ T2, zamiast jawnych krotek wartości. Specjalne algorytmy rozwiązań (których nie omawiamy tutaj) istnieją dla więzów liniowych na zmiennych całkowitych — to znaczy takich, jak to właśnie podane, w którym każda zmienna występuje tylko w postaci liniowej. Można wykazać, że nie istnieje żaden algorytm rozwiązywania ogólnych nieliniowych ograniczeń na zmienne całkowite – problem jest nierozstrzygalny
Problemy z satysfakcją z ograniczeń z domenami ciągłymi są powszechne w świecie rzeczywistym i są szeroko badane w dziedzinie badań operacyjnych. Na przykład planowanie eksperymentów na Kosmicznym Teleskopie Hubble’a wymaga bardzo precyzyjnego czasu obserwacji; początek i koniec każdej obserwacji i manewru są zmiennymi o wartości ciągłej, które muszą być zgodne z różnymi ograniczeniami astronomicznymi, pierwszeństwa i mocy. Najbardziej znaną kategorią CSP w dziedzinie ciągłej jest problem programowania liniowego, gdzie ograniczenia muszą być liniowymi równościami lub nierównościami. Zadania programowania liniowego mogą być rozwiązywane wielomianem czasu w liczbie zmiennych. Badano również problemy z różnymi typami ograniczeń i funkcjami celu — programowanie kwadratowe, programowanie stożkowe drugiego rzędu i tak dalej. Problemy te stanowią ważny obszar matematyki stosowanej. Oprócz badania typów zmiennych, które mogą pojawiać się w CSP, warto przyjrzeć się typom ograniczeń. Najprostszym typem jest ograniczenie jednoargumentowe, które ogranicza wartość pojedynczej zmiennej. Na przykład w problemie kolorowania mapy może być tak, że mieszkańcy Australii Południowej nie będą tolerować koloru zielonego; możemy to wyrazić za pomocą jednoargumentowego ograniczenia . <(SA),SA ≠ green.(Początkowa specyfikacja dziedziny zmiennej może być również postrzegana jako jednoargumentowe ograniczenie). Ograniczenie binarne dotyczy dwóch zmiennych. Na przykład SA ≠ NSW jest ograniczeniem binarnym. Binarny CSP to taki, który ma tylko jednoargumentowe i binarne ograniczenia; może być reprezentowany jako graf ograniczeń. Możemy również zdefiniować ograniczenia wyższego rzędu. Na przykład ograniczenie trójskładnikowe Beetwen(X,Y,Z) można zdefiniować jako <(X,Y,Z), X < Y < Z lub X > Y > Z . Ograniczenie obejmujące dowolną liczbę zmiennych nazywa się ograniczeniem globalnym. (Nazwa jest tradycyjna, ale myląca, ponieważ globalne ograniczenie nie musi obejmować wszystkich zmiennych w problemie). Jednym z najczęstszych globalnych ograniczeń jest All di f f , które mówi, że wszystkie zmienne objęte ograniczeniem muszą mieć różne wartości. W zadaniach Sudoku wszystkie zmienne w rzędzie, kolumnie lub polu 3 x 3 muszą spełniać warunek All diff
Innym przykładem są łamigłówki kryptarytmetyczne (a). Każda litera w łamigłówce (a) byłoby to reprezentowane jako globalne ograniczenie All diff(F,T,U,W,R,O) . Ograniczenia dodawania na czterech kolumnach łamigłówki można zapisać jako następujące ograniczenia n-argumentowe:
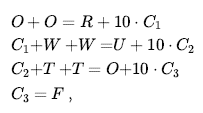
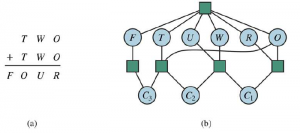
gdzie C1,C2 i C3 są zmiennymi pomocniczymi reprezentującymi cyfrę przeniesioną do kolumny dziesiątek, setek lub tysięcy. Te ograniczenia można przedstawić na hipergrafie ograniczeń, takim jak ten pokazany na rysunku 6.2(b). Hipergraf składa się ze zwykłych węzłów (kół na rysunku) i hiperwęzłów (kwadratów), które reprezentują ograniczenia -arne — ograniczenia obejmujące n zmiennych.
Alternatywnie NARY prosi o udowodnienie, że każde ograniczenie domeny skończonej można zredukować do zestawu ograniczeń binarnych, jeśli wprowadzi się wystarczającą liczbę zmiennych pomocniczych. Oznacza to, że możemy przekształcić dowolny CSP w taki, który ma tylko ograniczenia binarne — co z pewnością upraszcza życie projektanta algorytmu. Innym sposobem konwersji -arnego CSP na binarny jest transformacja grafu dualnego: utwórz nowy graf, w którym będzie jedna zmienna dla każdego ograniczenia w oryginalnym grafie i jedno ograniczenie binarne dla każdej pary ograniczeń w oryginalnym grafie które dzielą zmienne. Rozważmy na przykład CSP ze zmiennymi X = {X,Y,Z}, każda z dziedziną {1,2,3,4,5} i dwoma ograniczeniami C1 : <(X,Y,Z) ,X + Y=Z> i C2 : <(X,Y),X +1 = Y .Wtedy graf dualny miałby zmienne X = {C1,C2} , gdzie domena C1 zmienna w grafie dualnym jest zbiorem {(xi,yj,zk)} krotek z ograniczenia C1 w pierwotnym problemie i podobnie dziedzina C2 jest zbiorem krotek {(xi,yj)}. Wykres dualny ma ograniczenie binarne <(C1,C2), R1), gdzie R1 jest nową relacją, która definiuje ograniczenie między C1 i C2 ; w tym przypadku byłoby to
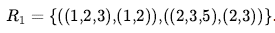
Istnieją jednak dwa powody, dla których możemy preferować globalne ograniczenie, takie jak Alldiff, zamiast zestawu ograniczeń binarnych. Po pierwsze, łatwiej i mniej podatne na błędy jest napisanie opisu problemu za pomocą Alldiff . Po drugie, możliwe jest zaprojektowanie algorytmów wnioskowania specjalnego przeznaczenia dla globalnych ograniczeń, które są bardziej wydajne niż działanie z ograniczeniami pierwotnymi.
Wszystkie opisane przez nas dotychczas ograniczenia były ograniczeniami bezwzględnymi, których naruszenie wyklucza potencjalne rozwiązanie. Wiele rzeczywistych dostawców CSP zawiera ograniczenia preferencji wskazujące, które rozwiązania są preferowane. Na przykład, w uniwersyteckim problemie planowania zajęć istnieją bezwzględne ograniczenia, że żaden profesor nie może uczyć dwóch klas jednocześnie. Ale możemy również dopuścić ograniczenia preferencji: prof. R może preferować nauczanie rano, podczas gdy prof. N woli nauczać po południu. Harmonogram, w którym prof. R naucza o godz. nadal byłoby rozwiązaniem dopuszczalnym (chyba że prof. R jest przewodniczącym wydziału), ale nie optymalnym.