Widzieliśmy, jak AC-3 może zredukować domeny zmiennych przed rozpoczęciem wyszukiwania. Ale wnioskowanie może być jeszcze silniejsze w trakcie wyszukiwania: za każdym razem, gdy dokonujemy wyboru wartości zmiennej, mamy zupełnie nową możliwość wnioskowania o nowe redukcje domen na sąsiednich zmiennych. Jedną z najprostszych form wnioskowania jest sprawdzanie w przód. Za każdym razem, gdy zmienna X jest przypisana, proces sprawdzania w przód ustala dla niej spójność łukową: dla każdej nieprzypisanej zmiennej Y, która jest połączona z X przez ograniczenie, usuń z domeny Y każdą wartość, która jest niezgodna z wartością wybraną dla X. Rysunek przedstawia postęp wyszukiwania z wycofywaniem w australijskim CSP ze sprawdzaniem w przód.
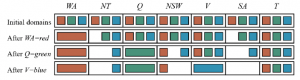
W tym przykładzie należy zwrócić uwagę na dwie ważne kwestie. Po pierwsze, zauważ, że po przypisaniu WA = czerwony i Q = zielony, domeny NT i SA są zredukowane do jednej wartości; całkowicie wyeliminowaliśmy rozgałęzienia na tych zmiennych poprzez propagowanie informacji z WA i Q. Drugą kwestią, na którą należy zwrócić uwagę, jest to, że po V = blue domena SA jest pusta. Zatem sprawdzanie w przód wykryło, że przypisanie częściowe {WA = czerwony, Q = zielony, V= niebieski} jest niezgodne z ograniczeniami problemu i algorytm natychmiast się cofa.
W przypadku wielu problemów wyszukiwanie będzie skuteczniejsze, jeśli połączymy heurystykę MRV ze sprawdzanie, w przód. Rozważ rysunek po przypisaniu {WA= red}. Intuicyjnie wydaje się, że to przypisanie ogranicza sąsiadów NT i SA , więc powinniśmy teraz zająć się tymi zmiennymi, a wtedy wszystkie inne zmienne będą się układać. To jest dokładnie to, co dzieje się z MRV: NT i SA mają dwie wartości, więc jedna z nich jest wybierana jako pierwsza, potem druga, a następnie Q, NSW i V w kolejności. Wreszcie T nadal ma trzy wartości i każda z nich działa. Możemy postrzegać sprawdzanie w przód jako skuteczny sposób na przyrostowe obliczanie informacji, których heurystyka MRV potrzebuje do wykonania swojej pracy.
Chociaż sprawdzanie w przód wykrywa wiele niespójności, nie wykrywa ich wszystkich. Problem polega na tym, że nie wybiega wystarczająco daleko w przyszłość. Rozważmy na przykład Q = zielony rząd na Rysunku 6.7 . Uczyniliśmy łuki WA i Q spójnymi, ale zostawiliśmy zarówno NT, jak i SA z kolorem niebieskim jako jedyną możliwą wartością, co jest niespójnością, ponieważ są sąsiadami.
Algorytm o nazwie MAC (for Maintaining Arc Consistency) wykrywa takie niespójności. Po przypisaniu wartości zmiennej Xi procedura INFERENCE wywołuje AC-3, ale zamiast kolejki wszystkich łuków w CSP, zaczynamy tylko od łuków (Xj,Xi) dla wszystkich Xj, które są nieprzypisanymi zmiennymi, które są sąsiadami z . Stamtąd AC-3 propaguje ograniczenia w zwykły sposób, a jeśli jakakolwiek zmienna ma swoją domenę zredukowaną do pustego zestawu, wywołanie AC-3 kończy się niepowodzeniem i wiemy, że należy natychmiast się wycofać. Widzimy, że MAC jest ściślej potężniejszy niż sprawdzanie w przód, ponieważ sprawdzanie w przód robi to samo, co MAC na początkowych łukach w kolejce MAC; ale w przeciwieństwie do MAC, sprawdzanie w przód nie propaguje rekursywnie ograniczeń, gdy wprowadzane są zmiany w domenach zmiennych.