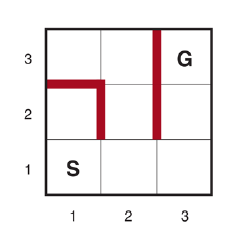
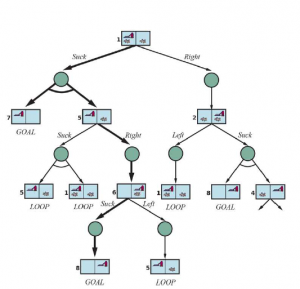
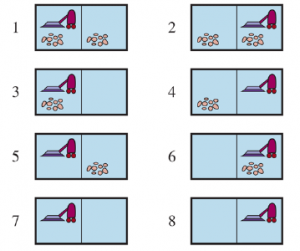
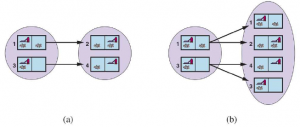
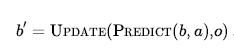Kiedy percepcje agenta nie dostarczają żadnych informacji, mamy coś, co nazywamy problemem bezczujnikowym (lub problemem zgodnym). Na początku możesz pomyśleć, że agent bezczujnikowy nie ma nadziei na rozwiązanie problemu, jeśli nie ma pojęcia, w jakim stanie zaczyna, ale rozwiązania bezczujnikowe są zaskakująco powszechne i przydatne, głównie dlatego, że nie opierają się na prawidłowym działaniu czujników. Na przykład w systemach produkcyjnych opracowano wiele pomysłowych metod prawidłowego orientowania części z nieznanej pozycji początkowej za pomocą sekwencji działań bez żadnego wykrywania. Czasami plan bezczujnikowy jest lepszy, nawet jeśli dostępny jest plan warunkowy z wykrywaniem. Na przykład lekarze często przepisują antybiotyk o szerokim spektrum działania, zamiast stosować warunkowy plan wykonania badania krwi, a następnie czekania na powrót wyników, a następnie przepisywania bardziej specyficznego antybiotyku. Plan bezczujnikowy oszczędza czas i pieniądze oraz zapobiega ryzyku pogorszenia infekcji przed udostępnieniem wyników testu. Rozważmy bezczujnikową wersję (deterministycznego) świata próżni. Załóż, że agent zna geografię swojego świata, ale nie zna własnego położenia czy rozmieszczenia brudu. W takim przypadku początkowy stan przekonania to {1,2,3,4,5,6,7,8} (patrz Rysunek 4.9 ). Teraz, jeśli agent poruszy się w prawo, będzie w jednym ze stanów {2,4,6,8} — agent uzyskał informacje, nie dostrzegając czegokolwiek! Po [Right,Suck] agent zawsze znajdzie się w jednym ze stanów {4,8}. Wreszcie, po [Right,Suck,Left,Suck] agent ma zagwarantowane osiągnięcie stanu docelowego 7, bez względu na stan początkowy. Mówimy, że agent może zmusić świat do stanu 7.
Rozwiązaniem problemu bezczujnikowego jest sekwencja działań, a nie plan warunkowy (bo nie ma percepcji). Ale szukamy raczej w przestrzeni stanów przekonań niż stanów fizycznych. W przestrzeni stanów przekonań problem jest w pełni obserwowalny, ponieważ podmiot zawsze zna swój stan przekonań. Co więcej, rozwiązaniem (jeśli istnieje) problemu bezczujnikowego jest zawsze sekwencja działań. Dzieje się tak, ponieważ, jak w zwykłych problemach z rozdziału 3, percepcje otrzymywane po każdym działaniu są całkowicie przewidywalne — zawsze są puste! Nie ma więc żadnych nieprzewidzianych okoliczności do planowania. Dzieje się tak, nawet jeśli środowisko jest niedeterministyczne. Moglibyśmy wprowadzić nowe algorytmy rozwiązywania problemów wyszukiwania bezczujnikowego. Ale zamiast tego możemy użyć istniejącego algorytmy, jeśli przekształcimy leżący u jego podstaw problem fizyczny w problem stanu przekonań, w którym poszukujemy raczej stanów przekonań niż stanów fizycznych. Pierwotny problem P ma komponenty ActionsP, ResultP itd., a problem stanu przekonań składa się z następujących komponentów:
* STATES: Przestrzeń stanów przekonań zawiera każdy możliwy podzbiór stanów fizycznych. Jeśli P ma N stanów, to problem stanów przekonań ma 2N stanów przekonań, chociaż wiele z nich może być nieosiągalnych ze stanu początkowego.
* INITIAL STATE: Zazwyczaj stan przekonań składający się ze wszystkich stanów w P , chociaż w niektórych przypadkach agent będzie miał więcej wiedzy niż ta.
* ACTIONS: Jest to nieco trudne. Załóżmy, że agent jest w stanie przekonania b = {s1,s2}, ale 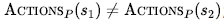 wtedy agent nie jest pewien, które działania są legalne. Jeśli założymy, że nielegalne działania nie mają wpływu na środowisko, można bezpiecznie połączyć wszystkie działania w dowolnym stanie fizycznym w obecnym stanie przekonań b:
wtedy agent nie jest pewien, które działania są legalne. Jeśli założymy, że nielegalne działania nie mają wpływu na środowisko, można bezpiecznie połączyć wszystkie działania w dowolnym stanie fizycznym w obecnym stanie przekonań b:
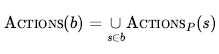
Z drugiej strony, jeśli nielegalne działanie może prowadzić do katastrofy, bezpieczniej jest dopuścić tylko skrzyżowanie, czyli zestaw działań legalnych we wszystkich stanach. W świecie próżni każde państwo ma takie same działania prawne, więc obie metody dają ten sam wynik.
* TRANSITION MODEL: W przypadku działań deterministycznych nowy stan przekonań ma jeden stan wynikowy dla każdego z obecnych możliwych stanów (chociaż niektóre stany wynikowe mogą być takie same):

W przypadku niedeterminizmu nowy stan przekonań składa się ze wszystkich możliwych wyników zastosowania działania do dowolnego ze stanów obecnego stanu przekonań:
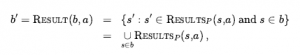
Rozmiar b’ będzie taki sam lub mniejszy niż w przypadku działań deterministycznych, ale może być większy niż w przypadku działań niedeterministycznych
* GOAL TEST: Agent prawdopodobnie osiąga cel, jeśli jakikolwiek stan w stanie przekonań spełnia test celu leżącego u podstaw problemu, IS-GOALP(s) . Agent koniecznie osiąga cel, jeśli każdy stan spełnia IS-GOALP(s). Naszym celem jest koniecznie osiągnięcie celu.
* ACTION COST: To też jest trudne. Jeśli to samo działanie może mieć różne koszty w różnych stanach, to koszt podjęcia działania w danym stanie przekonań może być jedną z kilku wartości. Na razie zakładamy, że koszt działania jest taki sam we wszystkich stanach, a więc może być przeniesiony bezpośrednio z podstawowego problemu fizycznego.
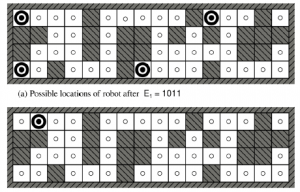
Rysunek przedstawia osiągalną przestrzeń stanów przekonań dla deterministycznego, bezczujnikowego świata próżni. Jest tylko 12 osiągalnych stanów przekonań spośród 28 = 256 możliwych stanów przekonań.
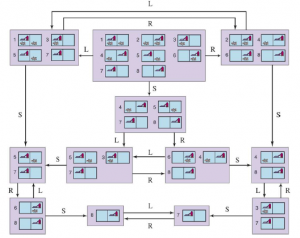
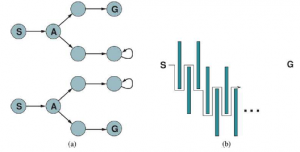
Powyższe definicje umożliwiają automatyczne skonstruowanie sformułowania problemu stanu przekonań na podstawie definicji leżącego u jego podstaw problemu fizycznego. Gdy to zrobimy, możemy rozwiązać problemy bezczujnikowe za pomocą dowolnego zwykłego algorytmu wyszukiwania z rozdziału 3 . W zwykłym przeszukiwaniu wykresów nowo osiągnięte stany są testowane, aby sprawdzić, czy zostały wcześniej osiągnięte. Działa to również w przypadku stanów przekonań; na przykład na rysunku sekwencja działań [Ssanie,Lewo,Ssanie] rozpoczynająca się w stanie początkowym osiąga ten sam stan przekonania co [Prawo,Lewo,Ssanie], a mianowicie {5,7} . Rozważmy teraz stan wiary osiągnięty przez [Z lewej], a mianowicie {1,3,5,7}. Oczywiście nie jest to identyczne z {5,7} , ale jest to nadzbiór. Możemy odrzucić (przyciąć) każdy taki superzbiór stanów przekonań. Czemu? Ponieważ rozwiązanie z {1,3,5,7} musi być rozwiązaniem dla każdego z poszczególnych stanów 1, 3, 5 i 7, a więc jest rozwiązaniem dla dowolnej kombinacji tych poszczególnych stanów, np. {5 ,7}; dlatego nie musimy próbować rozwiązać {1,3,5,7}, możemy skoncentrować się na próbie rozwiązania ściśle łatwiejszego stanu wiary {5,7}. I odwrotnie, jeśli {1,3,5,7} zostało już wygenerowane i uznane za możliwe do rozwiązania, to każdy podzbiór, taki jak {5,7} , jest gwarantowany. (Jeśli mam rozwiązanie, które działa, gdy jestem bardzo zdezorientowany co do tego, w jakim się jestem stanie, będzie nadal działać, gdy jestem mniej zdezorientowany.) Ten dodatkowy poziom przycinania może znacznie poprawić skuteczność rozwiązywania problemów bezczujnikowych. Jednak nawet przy tym ulepszeniu, bezczujnikowe rozwiązywanie problemów, jak to opisaliśmy, rzadko jest możliwe w praktyce. Jedną z kwestii jest ogrom przestrzeni stanów przekonań — widzieliśmy w poprzednim rozdziale, że często przestrzeń poszukiwań o rozmiarze N jest zbyt duża, a teraz mamy przestrzenie poszukiwań o rozmiarze 2N . Ponadto każdy element przestrzeni wyszukiwania to zestaw do N elementów. W przypadku dużego N nie będziemy w stanie przedstawić nawet jednego stanu przekonań bez wyczerpania pamięci. Jednym z rozwiązań jest przedstawienie stanu przekonań za pomocą bardziej zwięzłego opisu. W języku angielskim moglibyśmy powiedzieć, że agent nie wie „Nic” w stanie początkowym; po przesunięciu w lewo możemy powiedzieć „Nie w skrajnej prawej kolumnie” i tak dalej. Rozdział 7 wyjaśnia, jak to zrobić w formalnym schemacie reprezentacji. Innym podejściem jest unikanie standardowych algorytmów wyszukiwania, które traktują stany przekonań jako czarne skrzynki, tak jak każdy inny stan problemowy. Zamiast tego możemy zajrzeć do wnętrza stanów przekonań i opracować przyrostowe algorytmy wyszukiwania stanów przekonań, które budują rozwiązanie ol_lowerromann świat próżni bezczujnikowej, początkowy stan przekonań to {1,2,3,4,5,6,7,8} i musimy znaleźć sekwencję akcji, która działa we wszystkich 8 stanach. Możemy to zrobić, najpierw znajdując rozwiązanie, które działa dla stanu 1; następnie sprawdzamy, czy działa dla stanu 2; jeśli nie, wróć i znajdź inne rozwiązanie dla stanu 1 i tak dalej. Podobnie jak wyszukiwanie AND–OR musi znaleźć rozwiązanie dla każdej gałęzi w węźle AND, ten algorytm musi znaleźć rozwiązanie dla każdego stanu w stanie przekonania; różnica polega na tym, że wyszukiwanie AND–OR może znaleźć inne rozwiązanie dla każdej gałęzi, podczas gdy przyrostowe wyszukiwanie stanów przekonań musi znaleźć jedno rozwiązanie, które działa dla wszystkich stanów. Główną zaletą podejścia przyrostowego jest to, że zazwyczaj jest ono w stanie szybko wykryć niepowodzenie – gdy stan przekonania jest nierozwiązywalny, zwykle jest tak, że mały podzbiór stanu przekonania, składający się z kilku pierwszych zbadanych stanów, jest również nierozwiązywalny. . W niektórych przypadkach prowadzi to do przyspieszenia proporcjonalnego do wielkości stanów przekonań, które same mogą być tak duże, jak sama przestrzeń stanów fizycznych.