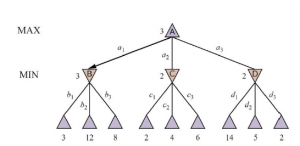
Wiele popularnych gier pozwala na więcej niż dwóch graczy. Przyjrzyjmy się, jak rozszerzyć ideę minimaxa na gry wieloosobowe. Jest to proste z technicznego punktu widzenia, ale rodzi kilka interesujących nowych kwestii koncepcyjnych. Najpierw musimy zastąpić pojedynczą wartość dla każdego węzła wektorem wartości. Na przykład w grze trzyosobowej z graczami A, B i C, wektor (vA.vB,vC) jest powiązany z każdym węzłem. W przypadku stanów końcowych wektor ten podaje użyteczność stanu z punktu widzenia każdego gracza. (W grach dla dwóch graczy o sumie zerowej dwuelementowy wektor można zredukować do pojedynczej wartości, ponieważ wartości są zawsze przeciwne). Najprostszym sposobem na zaimplementowanie tego jest zwrócenie przez funkcję UTILITY wektora narzędzi. Teraz musimy rozważyć stany nieterminalne. Rozważ węzeł zaznaczony X w drzewie gry pokazanym na rysunku.
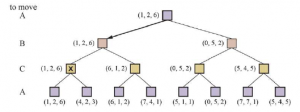
W tym stanie gracz C decyduje, co robić. Te dwie opcje prowadzą do stanów końcowych z wektorami użyteczności (vA = 1.vB = 2 ,vC = 6) i (vA = 4 .vB = 2,vC = 3) . Ponieważ 6 jest większe niż 3, C powinien wybrać pierwszy ruch. Oznacza to, że jeśli stan X zostanie osiągnięty, kolejne odtwarzanie doprowadzi do stanu końcowego z narzędziami (vA = 1.vB = 2 ,vC = 6) . Dlatego wartością kopii zapasowej X jest ten wektor. Ogólnie rzecz biorąc, wartość węzła n w kopii zapasowej jest wektorem użyteczności stanu następcy z najwyższą wartością dla gracza wybierającego w n.
Każdy, kto gra w gry wieloosobowe, takie jak Dyplomacja czy Osadnicy z Catanu, szybko uświadamia sobie, że dzieje się o wiele więcej niż w grach dwuosobowych. Gry wieloosobowe zwykle obejmują sojusze, formalne lub nieformalne, między graczami. Sojusze są zawierane i łamane w miarę postępu gry. Jak mamy rozumieć takie zachowanie? Czy sojusze są naturalną konsekwencją optymalnych strategii dla każdego gracza w grze wieloosobowej? Okazuje się, że mogą.
Załóżmy na przykład, że A i B są na słabych pozycjach, a C na silniejszej pozycji. Wtedy często optymalne jest, aby zarówno A, jak i B atakowały C, a nie siebie nawzajem, aby C nie zniszczyło każdego z nich z osobna. W ten sposób współpraca wyłania się z czysto egoistycznego zachowania.
Oczywiście, gdy tylko C słabnie pod wspólnym natarciem, sojusz traci swoją wartość, a A lub B mogą naruszyć porozumienie. W niektórych przypadkach jawne sojusze jedynie konkretyzują to, co i tak by się wydarzyło. W innych przypadkach zerwanie sojuszu wiąże się z piętnem społecznym, więc gracze muszą zrównoważyć bezpośrednią przewagę zerwania sojuszu z długoterminową wadą bycia postrzeganym jako niegodny zaufania. Jeśli gra nie ma sumy zerowej, współpraca może również mieć miejsce tylko z dwoma graczami. Załóżmy na przykład, że istnieje stan terminala z narzędziami (vA = 1000 i vB = 1000), że 1000 jest najwyższą możliwą użytecznością dla każdego gracza. Wtedy optymalna strategia polega na tym, aby obaj gracze zrobili wszystko, co możliwe, aby osiągnąć ten stan – to znaczy, że gracze będą automatycznie współpracować, aby osiągnąć wspólnie pożądany cel.