Problem wyszukiwania online jest rozwiązywany przez przeplatanie obliczeń, wykrywania i działania. Zaczniemy od założenia deterministycznego i w pełni obserwowalnego środowiska (rozdział 17 rozluźnia te założenia) i zastrzeżemy, że agent wie tylko:
* DZIAŁANIA, czynności prawne w stanie;
* c(s,a,s’) , koszt zastosowania akcji w stanie s, aby dojść s’ do stanu . Zauważ, że nie można tego użyć, dopóki agent nie wie, że wynikiem jest s’.
* Is-GOAL(s), test celu.
W szczególności należy zauważyć, że agent nie może określić WYNIKU(ów, a) z wyjątkiem faktycznego przebywania i wykonywania . Na przykład w problemie labiryntu pokazanym na rysunku , agent nie wie, że przejście w górę z (1,1) prowadzi do (1,2); ani po zrobieniu tego nie wie, że zejście w dół spowoduje powrót do (1,1). Ten stopień ignorancji można zmniejszyć w niektórych zastosowaniach – na przykład eksplorator robota może wiedzieć, jak działają jego ruchy i nie znać tylko lokalizacji przeszkód.
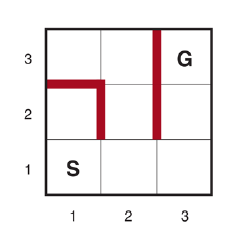
Wreszcie agent może mieć dostęp do dopuszczalnej funkcji heurystycznej h(s), która szacuje odległość od stanu bieżącego do stanu docelowego. Na przykład na rysunku powyżej agent może znać lokalizację celu i być w stanie użyć heurystyki odległości Manhattan . Zazwyczaj celem agenta jest osiągnięcie stanu docelowego przy minimalizacji kosztów. (Innym możliwym celem jest po prostu zbadanie całego środowiska). Koszt to całkowity koszt ścieżki, który agent ponosi podczas podróży. Często porównuje się ten koszt z kosztem ścieżki, jaki poniósłby agent, gdyby znał z góry przestrzeń wyszukiwania — to znaczy optymalną ścieżkę w znanym środowisku. W języku algorytmów internetowych porównanie to nazywa się współczynnikiem konkurencyjności; chcielibyśmy, aby był jak najmniejszy. Odkrywcy online są narażeni na ślepe zaułki: stany, z których żaden stan docelowy nie jest osiągalny. Jeśli agent nie wie, co robi każda akcja, może wykonać akcję „skoku w bezdenną otchłań”, a tym samym nigdy nie osiągnąć celu. Ogólnie rzecz biorąc, żaden algorytm nie może uniknąć ślepych zaułków we wszystkich przestrzeniach stanów. Rozważmy dwie martwe przestrzenie stanów na rysunku (a) . Algorytm wyszukiwania online, który odwiedził stany A i S, nie może stwierdzić, czy jest w stanie górnym, czy dolnym; oba wyglądają identycznie w zależności od tego, co widział agent. Dlatego nie może wiedzieć, jak wybrać właściwą akcję w obu przestrzeniach stanów. Jest to przykład argumentu adwersarza — możemy sobie wyobrazić przeciwnika konstruującego przestrzeń stanów, podczas gdy agent ją bada i umieszcza cele i ślepe zaułki, gdziekolwiek chce, jak na rysunku (b).
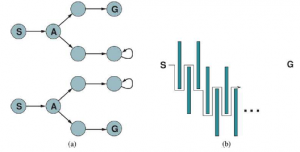
Ślepe zaułki są prawdziwym utrudnieniem dla eksploracji robotów – klatki schodowe, rampy, klify, ulice jednokierunkowe, a nawet naturalny teren – wszystkie obecne stany, z których niektóre działania są nieodwracalne – nie ma możliwości powrotu do poprzedniego stanu. Algorytm eksploracji, który przedstawimy, gwarantuje działanie tylko w przestrzeniach stanów, które można bezpiecznie eksplorować — to znaczy, że pewien stan docelowy jest osiągalny z każdego stanu osiągalnego. Przestrzenie stanów, w których występują tylko akcje odwracalne, takie jak labirynty i 8 zagadek, są wyraźnie bezpiecznie eksplorowane (jeśli w ogóle mają jakieś rozwiązanie). Temat bezpiecznej eksploracji omówimy bardziej szczegółowo w sekcji 22.3.2. Nawet w środowiskach, w których można bezpiecznie eksplorować, nie można zagwarantować żadnego ograniczonego współczynnika konkurencyjności, jeśli istnieją ścieżki o nieograniczonych kosztach. Łatwo to pokazać w środowiskach z nieodwracalnymi działaniami, ale w rzeczywistości pozostaje to również prawdziwe w przypadku odwracalnym, jak pokazuje Rysunek 4.20(b). Z tego powodu często charakteryzuje się wydajność algorytmów wyszukiwania online pod kątem rozmiaru całej przestrzeni stanów, a nie tylko głębokości najpłytszego celu.