Agent dla środowisk częściowo obserwowalnych formułuje problem, wywołuje algorytm wyszukiwania (taki jak AND-LUB-SEARCH) w celu jego rozwiązania i wykonuje rozwiązanie. Istnieją dwie główne różnice między tym agentem a tym dla w pełni obserwowalnych środowisk deterministycznych. Po pierwsze, rozwiązaniem będzie plan warunkowy, a nie sekwencja; aby wykonać wyrażenie if-then-else, agent będzie musiał przetestować warunek i wykonać odpowiednią gałąź warunku. Po drugie, agent będzie musiał utrzymać swój stan wiary podczas wykonywania działań i odbierania percepcji. Proces ten przypomina proces przewidywania-obserwacji-aktualizacji w równaniu ), ale w rzeczywistości jest prostszy, ponieważ percepcja jest przekazywana przez środowisko, a nie obliczana przez agenta. Biorąc pod uwagę początkowy stan przekonań , działanie i percepcję , nowy stan przekonań to:
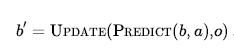
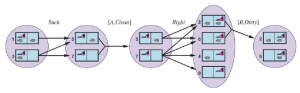
Rozważmy przedszkolny świat próżni, w którym agenci wyczuwają tylko stan swojego obecnego placu, a każdy plac może się zabrudzić w dowolnym momencie, chyba że agent aktywnie go czyści w danym momencie. Rysunek przedstawia stan przekonania utrzymywany w tym środowisku.
W środowiskach częściowo obserwowalnych – które obejmują zdecydowaną większość środowisk świata rzeczywistego – utrzymywanie własnego stanu wiary jest podstawową funkcją każdego inteligentnego systemu. Ta funkcja nosi różne nazwy, w tym monitorowanie, filtrowanie i estymację stanu. Równanie powyższe nazywa się rekurencyjnym estymatorem stanu, ponieważ oblicza nowy stan przekonania z poprzedniego, a nie przez badanie całej sekwencji percepcji. Jeśli agent nie ma „zostać w tyle”, obliczenia muszą odbywać się tak szybko, jak pojawiają się spostrzeżenia. Gdy środowisko staje się bardziej złożone, agent będzie miał tylko czas na obliczenie przybliżonego stanu przekonań, być może skupiając się na implikacjach postrzeganie aspektów środowiska będących przedmiotem bieżącego zainteresowania. Większość prac nad tym problemem została wykonana dla stochastycznych środowisk o stanie ciągłym za pomocą narzędzi teorii prawdopodobieństwa
W częściowo obserwowalnych środowiskach — które obejmują zdecydowaną większość rzeczywistych środowisk — utrzymywanie własnego stanu wiary jest podstawową funkcją każdego inteligentnego systemu. Ta funkcja nosi różne nazwy, w tym monitorowanie, filtrowanie i estymację stanu. Równanie powyższe jest nazywane rekurencyjnym estymatorem stanu, ponieważ oblicza nowy stan przekonania z poprzedniego, a nie przez badanie całej sekwencji percepcji. Jeśli agent nie ma „zostać w tyle”, obliczenia muszą odbywać się tak szybko, jak pojawiają się spostrzeżenia. Gdy środowisko staje się bardziej złożone, agent będzie miał tylko czas na obliczenie przybliżonego stanu przekonań, być może skupiając się na implikacjach postrzeganie aspektów środowiska będących przedmiotem aktualnego zainteresowania. Większość prac nad tym problemem została wykonana dla stochastycznych środowisk o stanie ciągłym za pomocą narzędzi teorii prawdopodobieństwa. W tej sekcji pokażemy przykład w dyskretnym środowisku z czujnikami deterministycznymi i działaniami niedeterministycznymi. Przykład dotyczy robota z konkretnym zadaniem oceny stanu zwanym lokalizacją: ustaleniem, gdzie się znajduje, mając do dyspozycji mapę świata oraz sekwencję percepcji i działań. Nasz robot znajduje się w podobnym do labiryntu środowisku z rysunku 4.18. Robot jest wyposażony w cztery czujniki sonaru, które informują, czy w każdym z czterech kierunków kompasu znajduje się przeszkoda — zewnętrzna ściana czy ciemny kwadrat na figurze. Percept ma postać wektora bitowego, po jednym bitu dla każdego kierunku północ, wschód, południe i zachód w tej kolejności, więc 1011 oznacza, że istnieją przeszkody na północy, południu i zachodzie, ale nie na wschodzie.
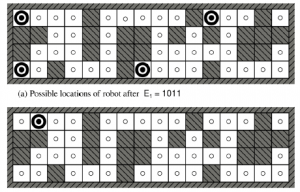
Zakładamy, że czujniki podają idealnie poprawne dane, a robot ma poprawną mapę otoczenia. Niestety, system nawigacyjny robota jest zepsuty, więc wykonując akcję Właściwą, porusza się on losowo na jedno z sąsiednich pól. Zadaniem robota jest określenie jego aktualnej lokalizacji. Załóżmy, że robot został właśnie włączony i nie wie, gdzie jest – jego inicjał to stan przekonania składa się ze zbioru wszystkich lokalizacji. Następnie robot odbiera percept 1011 i dokonuje aktualizacji przy użyciu równania b0 = UPDATE(1011) , dając 4 lokalizacje pokazane na rysunku 4.18(a) . Możesz zbadać labirynt, aby zobaczyć, że są to jedyne cztery lokalizacje, które dają percepcję 1011. Następnie robot wykonuje akcję Właściwą, ale wynik jest niedeterministyczny. Nowy stan przekonania, ba = PREDICT(b0,RIGHT) , zawiera wszystkie lokalizacje, które są o jeden krok od lokalizacji w . Kiedy pojawia się drugi percept, 1010, robot wykonuje UPDATE(1010) i stwierdza, że stan przekonania zapadł się do pojedynczej lokalizacji pokazanej na rysunku 4.18(b). To jedyna lokalizacja, która może być wynikiem
![]()
W przypadku działań niedeterministycznych krok PREDICT zwiększa stan przekonania, ale krok UPDATE zmniejsza go z powrotem, o ile spostrzeżenia dostarczają użytecznych informacji identyfikacyjnych. Czasami percepcje nie pomagają zbytnio w lokalizacji: gdyby istniał jeden lub więcej długich korytarzy wschód-zachód, robot mógłby otrzymać długą sekwencję 1010 percepcji, ale nigdy nie wiedział, gdzie w korytarzu (korytarzach) się znajdował. Jednak w środowiskach o rozsądnej zmienności geograficznej lokalizacja często szybko zbliża się do jednego punktu, nawet jeśli działania nie są deterministyczne. Co się stanie, jeśli czujniki są uszkodzone? Jeśli możemy rozumować tylko za pomocą logiki Boole’a, to musimy traktować każdy bit czujnika jako poprawny lub niepoprawny, co jest równoznaczne z brakiem jakichkolwiek informacji percepcyjnych. Zobaczymy jednak, że rozumowanie probabilistyczne (rozdział 12) pozwala nam wydobyć użyteczne informacje z wadliwego czujnika, o ile jest on błędny przez mniej niż połowę czasu.