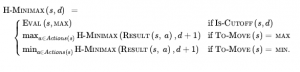Gra w Go ilustruje dwie główne słabości wyszukiwania heurystycznego w drzewie alfa-beta: Po pierwsze, Go ma współczynnik rozgałęzienia, który zaczyna się od 361, co oznacza, że wyszukiwanie w alfabecie alfa będzie ograniczone tylko do 4 lub 5 warstw. Po drugie, trudno jest zdefiniować dobrą funkcję oceny dla Go, ponieważ wartość materialna nie jest silnym wskaźnikiem, a większość pozycji zmienia się aż do końca gry. W odpowiedzi na te dwa wyzwania, współczesne programy Go zrezygnowały z wyszukiwania alfa-beta i zamiast tego używają strategii zwanej przeszukiwaniem drzewa Monte Carlo (MCTS). Podstawowa strategia MCTS nie wykorzystuje funkcji oceny heurystycznej. Zamiast tego wartość stanu jest szacowana jako średnia użyteczność w wielu symulacjach pełnych gier, zaczynając od stanu. Symulacja (zwana również playout lub rollout) wybiera ruchy najpierw dla jednego gracza, a następnie dla drugiego, powtarzając aż do osiągnięcia końcowej pozycji. W tym momencie reguły gry (nie omylna heurystyka) określają, kto wygrał lub przegrał, i jaki jest wynik. W przypadku gier, w których jedynymi wynikami są wygrana lub przegrana, „średnia użyteczność” jest taka sama, jak „procent wygranych”. Jak wybieramy ruchy do wykonania podczas rozgrywki? Jeśli wybieramy po prostu losowo, to po wielu symulacjach otrzymujemy odpowiedź na pytanie „jaki jest najlepszy ruch, jeśli obaj gracze grają losowo?” W przypadku niektórych prostych gier jest to ta sama odpowiedź, co „jaki jest najlepszy ruch, jeśli obaj gracze grają dobrze?”, ale w większości gier tak nie jest. Aby uzyskać przydatne informacje z rozgrywek, potrzebujemy polityki rozgrywek, która skłania ruchy do dobrych. W przypadku Go i innych gier zasady dotyczące odtwarzania zostały z powodzeniem nauczone podczas samodzielnej gry przy użyciu sieci neuronowych. Czasami używane są heurystyki specyficzne dla gry, takie jak „rozważ ruchy bicia” w szachach lub „zajmij kwadrat narożny” w Othello. Biorąc pod uwagę zasady dotyczące rozgrywania, musimy następnie zdecydować o dwóch rzeczach: od jakich pozycji rozpoczynamy playouty i ile playoutów przydzielimy do każdej pozycji? Najprostszą odpowiedzią, nazywaną czystym wyszukiwaniem Monte Carlo, jest wykonanie N symulacji, zaczynając od aktualnego stanu gry i śledzenie, który z możliwych ruchów z aktualnej pozycji ma najwyższy procent wygranych. W przypadku niektórych gier stochastycznych to zbiega się do optymalnej rozgrywki wraz ze wzrostem liczby N, ale w przypadku większości gier jest to niewystarczające — potrzebujemy polityki selekcji, która selektywnie skupia zasoby obliczeniowe na ważnych częściach drzewa gry. Równoważy dwa czynniki: eksplorację stanów, które miały niewiele playoutów, oraz eksploatację stanów, które radziły sobie dobrze w poprzednich playoutach, aby uzyskać dokładniejsze oszacowanie ich wartości. Wyszukiwanie drzewa metodą Monte Carlo robi to, utrzymując drzewo wyszukiwania i rozwijając je w każdej iteracji następujących czterech kroków
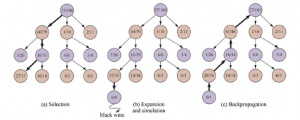
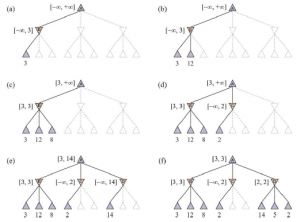
SELEKCJA: Zaczynając od korzenia drzewa wyszukiwania, wybieramy ruch (kierując się polityką selekcji), prowadzący do węzła następnika i powtarzamy ten proces, przechodząc w dół drzewa do liścia. Rysunek 5.10(a) pokazuje drzewo wyszukiwania z korzeniem reprezentującym stan, w którym biały właśnie się przeniósł, a biały wygrał 37 ze 100 rozegranych do tej pory. Gruba strzałka pokazuje wybór ruchu przez czarne, który prowadzi do węzła, w którym czarne wygrały 60/79 playoutów. Jest to najlepszy procent wygranych spośród trzech ruchów, więc wybranie go jest przykładem wyzysku. Ale rozsądne byłoby również wybranie węzła 2/11 ze względu na eksplorację – mając tylko 11 playoutów, węzeł nadal ma dużą niepewność w swojej wycenie i może okazać się najlepszy, jeśli zdobędziemy więcej informacji na jego temat. Zaznaczanie jest kontynuowane do węzła liścia oznaczonego 27/35.
ROZSZERZENIE: Rozwijamy drzewo wyszukiwania, generując nowe dziecko wybranego węzła; Rysunek (b) przedstawia nowy węzeł oznaczony cyfrą 0/0. (Niektóre wersje generują w tym kroku więcej niż jedno dziecko).
SYMULACJA: Wykonujemy playout z nowo wygenerowanego węzła podrzędnego, wybierając ruchy dla obu graczy zgodnie z polityką playout. Te ruchy nie są rejestrowane w drzewie wyszukiwania. Na rysunku symulacja skutkuje wygraną czarnych.
PROPAGACJA WSTECZNA: Używamy teraz wyniku symulacji, aby zaktualizować wszystkie węzły drzewa wyszukiwania, aż do korzenia. Ponieważ czarny wygrał rozgrywkę, czarne węzły są zwiększane zarówno pod względem liczby wygranych, jak i liczby playoutów, więc 27/35 staje się 28/26, a 60/79 staje się 61/80. Ponieważ białe węzły zostały utracone, liczba białych węzłów zwiększa się tylko pod względem liczby odtworzeń, więc 16/53 staje się 16/54, a pierwiastek 37/100 staje się 37/101.
Powtarzamy te cztery kroki albo przez określoną liczbę iteracji, albo do upłynięcia wyznaczonego czasu, a następnie zwracamy ruch z największą liczbą odtworzeń. Jedna bardzo skuteczna polityka selekcji nazywa się „górnymi granicami ufności stosowanymi do drzew” lub UCT. Polityka klasyfikuje każdy możliwy ruch w oparciu o formułę górnej granicy ufności o nazwie UCB1. Dla węzła n wzór jest następujący:
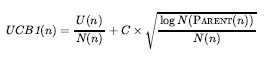
gdzie to całkowita użyteczność wszystkich playoutów, które przeszły przez węzeł n, N(n) to liczba playoutów przez węzeł n , a PARENT(n) to węzeł nadrzędny n w drzewie. Zatem U(n)/N(n) jest terminem eksploatacyjnym: średnia użyteczność . Termin z pierwiastkiem kwadratowym to termin eksploracji: ma liczbę N(n) w mianowniku, co oznacza, że termin będzie wysoki dla węzłów, które zostały zbadane tylko kilka razy. W liczniku znajduje się dziennik, ile razy badaliśmy rodzica . Oznacza to, że jeśli wybieramy n jakiś niezerowy procent czasu, termin eksploracji schodzi do zera wraz ze wzrostem liczebności, a ostatecznie odtworzenia są przekazywane do węzła o najwyższej średniej użyteczności. C jest stałą, która równoważy eksploatację i eksplorację. Istnieje teoretyczny argument, że C powinien być piewisatek z 2 , ale w praktyce programiści gier próbują wielu wartości dla C i wybierają tę, która działa najlepiej. (Niektóre programy używają nieco innych wzorów; na przykład ALPHAZERO dodaje termin określający prawdopodobieństwo ruchu, który jest obliczany przez sieć neuronową wytrenowaną na podstawie wcześniejszej samoodgrywania.) Przy C=1,4 węzeł 60/79 na rysunku powyżej ma najwyższy wynik UCB1, ale przy C=1.5 byłby to węzeł 2/11.
Poniższy rysunek przedstawia kompletny algorytm UCT MCTS. Po zakończeniu iteracji ruch z największą liczbą odtworzeń zostaje zwrócony. Możesz pomyśleć, że lepiej byłoby zwrócić węzeł z najwyższą średnią użytecznością, ale pomysł jest taki, że węzeł z wygranymi 65/100 jest lepszy niż ten z wygranymi 2/3, ponieważ ten drugi ma dużą niepewność. W każdym razie formuła UCB1 zapewnia, że węzeł z największą liczbą playoutów jest prawie zawsze węzłem z najwyższym procentem wygranych, ponieważ proces selekcji coraz bardziej faworyzuje procent wygranych wraz ze wzrostem liczby playoutów.

Czas na obliczenie rozgrywek jest liniowy, a nie wykładniczy, w głębi drzewa gry, ponieważ w każdym punkcie wyboru wykonywany jest tylko jeden ruch. To daje nam mnóstwo czasu na wiele rozgrywek. Na przykład: rozważ grę ze współczynnikiem rozgałęzienia 32, gdzie
średnia gra trwa 100 warstw. Jeśli mamy wystarczającą moc obliczeniową, aby rozważyć miliard stanów gry, zanim będziemy musieli wykonać ruch, to minimax może przeszukiwać 6 warstw, alfa-beta z doskonałym porządkowaniem ruchów może przeszukiwać 12 warstw, a wyszukiwanie Monte Carlo może wykonać 10 milionów odtworzeń. Które podejście będzie lepsze? Zależy to od dokładności funkcji heurystycznej w porównaniu z zasadami wyboru i odtwarzania. Powszechnie uważa się, że wyszukiwanie metodą Monte Carlo ma przewagę nad alfa-betą w grach takich jak Go, w których współczynnik rozgałęzienia jest bardzo wysoki (a zatem alfa-beta nie może wyszukiwać wystarczająco głęboko) lub gdy trudno jest zdefiniować dobry funkcja oceny. To, co robi alfa-beta, to wybór ścieżki do węzła, który ma najwyższy osiągalny wynik funkcji oceny, biorąc pod uwagę, że przeciwnik będzie próbował zminimalizować wynik. Tak więc, jeśli funkcja oceny jest niedokładna, alfa-beta będzie niedokładna. Błędne obliczenia na pojedynczym węźle mogą spowodować, że alfa-beta błędnie wybierze (lub ominie) ścieżkę do tego węzła. Ale wyszukiwanie Monte Carlo opiera się na agregacie wielu playoutów, a zatem nie jest tak podatne na pojedynczy błąd. Możliwe jest połączenie MCTS i funkcji oceny, wykonując playout dla określonej liczby ruchów, a następnie skracając playout i stosując funkcję oceny. Możliwe jest również połączenie aspektów wyszukiwania alfa-beta i Monte Carlo. Na przykład w grach, które mogą trwać wiele ruchów, możemy chcieć użyć wczesnego zakończenia gry, w którym zatrzymujemy grę, która zajmuje zbyt wiele ruchów i albo oceniamy ją za pomocą funkcji oceny heurystycznej, albo po prostu ogłaszamy remis.
Wyszukiwanie metodą Monte Carlo można zastosować do zupełnie nowych gier, w których nie ma żadnego doświadczenia, z którego można by czerpać, aby zdefiniować funkcję oceny. Dopóki znamy zasady gry, wyszukiwanie w Monte Carlo nie wymaga żadnych dodatkowych informacji. Zasady selekcji i odtwarzania mogą dobrze wykorzystać zdobytą ręcznie wiedzę ekspercką, gdy jest ona dostępna, ale dobrych zasad można się nauczyć, korzystając z sieci neuronowych wyszkolonych wyłącznie przez samodzielną grę. Wyszukiwanie Monte Carlo ma wadę, gdy jest prawdopodobne, że pojedynczy ruch może zmienić przebieg gry, ponieważ stochastyczny charakter wyszukiwania Monte Carlo oznacza, że może nie wziąć pod uwagę tego ruchu. Innymi słowy, przycinanie typu B w wyszukiwaniu Monte Carlo oznacza, że kluczowa linia gry może w ogóle nie zostać zbadana. Wyszukiwanie Monte Carlo ma również wadę, gdy istnieją stany gry, które są „oczywiście” wygraną dla jednej lub drugiej strony (zgodnie z ludzką wiedzą i funkcją oceny), ale w przypadku, gdy weryfikacja wymaga wielu ruchów w playout Zwycięzca. Od dawna utrzymywano, że wyszukiwanie alfa-beta lepiej nadaje się do gier takich jak szachy z niskim współczynnikiem rozgałęzienia i dobrymi funkcjami oceny, ale ostatnio podejście Monte Carlo wykazało sukces w szachach i innych grach. Ogólna idea symulowania ruchów w przyszłość, obserwowanie wyniku i wykorzystywanie wyniku do określenia, które ruchy są dobre, jest jednym z rodzajów uczenia się przez wzmacnianie