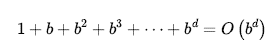Najpopularniejszym algorytmem świadomego wyszukiwania jest wyszukiwanie A* (wymawiane „wyszukiwanie z gwiazdką A”), wyszukiwanie „najlepsze-pierwsze”, które wykorzystuje funkcję oceny
f(n) = h(n)+ g(n)
gdzie g(n) to koszt ścieżki od stanu początkowego do węzła n, a h(n) to szacowany koszt najkrótszej ścieżki z n do stanu docelowego, więc mamy
f(n) = szacowany koszt najlepszej ścieżki, która biegnie od n do celu.
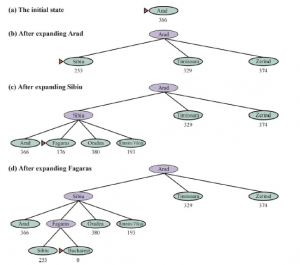
Na rysunku pokazujemy postęp wyszukiwania A*, którego celem jest dotarcie do Bukaresztu.
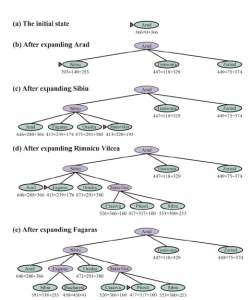
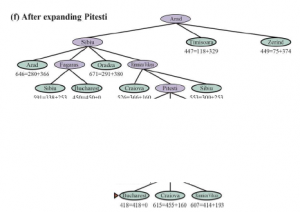
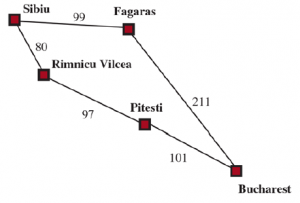
Wartości g obliczono z kosztów działań na Rysunku 3.1 , a wartości hSLD podano na Rysunku 3.16 . Zauważ, że Bukareszt po raz pierwszy pojawia się na granicy w kroku (e), ale nie jest wybrany do ekspansji (a zatem nie jest wykrywany jako rozwiązanie), ponieważ przy f = 450 nie jest to najtańszy węzeł na granicy — byłoby to Pitesti, przy f= A17. Innym sposobem na powiedzenie tego jest to, że może istnieć rozwiązanie przez Pitesti, którego koszt jest tak niski, jak 417, więc algorytm nie zadowoli się rozwiązaniem, które kosztuje 450. W kroku (f) inna droga do Bukaresztu jest teraz najniższa -koszt węzła, przy f = 418, więc jest wybierany i wykrywany jako rozwiązanie optymalne.
Wyszukiwanie* zakończone. To, czy A* jest optymalne pod względem kosztów, zależy od pewnych właściwości heurystyki. Kluczową właściwością jest dopuszczalność: dopuszczalna heurystyka to taka, która nigdy nie przecenia kosztów osiągnięcia celu. (Dopuszczalna heurystyka jest zatem optymistyczna.) Przy dopuszczalnej heurystyce A* jest optymalny pod względem kosztów, co możemy wykazać za pomocą dowodu przez sprzeczność. Załóżmy, że optymalna ścieżka ma koszt C*, ale algorytm zwraca ścieżkę o koszcie C > C*. Następnie musi istnieć jakiś węzeł n, który znajduje się na optymalnej ścieżce i jest nierozwinięty (ponieważ gdyby wszystkie węzły na optymalnej ścieżce zostały rozwinięte, to zwrócilibyśmy to optymalne rozwiązanie). Zatem używając notacji g*(n) do oznaczenia kosztu ścieżki optymalnej od początku do n i h*(n) do oznaczenia kosztu ścieżki optymalnej od n do najbliższego celu, mamy:
f (n) > C∗ (w przeciwnym razie n zostałoby rozszerzone)
f (n) = g (n) + h (n) (z definicji)
f (n) = g∗ (n) + h (n) (ponieważ n jest na optymalnej ścieżce)
f (n) ≤ g∗ (n) + h∗ (n) (ze względu na dopuszczalność, h (n) ≤ h∗ (n))
f (n) ≤ C∗ (z definicji, C∗ = g∗ (n) + h∗ (n))
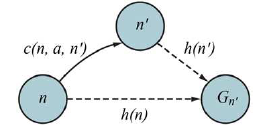
Pierwsza i ostatnia linia tworzą sprzeczność, więc założenie, że algorytm może zwrócić ścieżkę suboptymalną, musi być błędne – musi być tak, że A* zwraca tylko ścieżki optymalne kosztowo. Nieco silniejsza właściwość nazywa się konsystencją. Heurystyka h(n) jest niesprzeczna, jeśli dla każdego węzła n i każdego następnika n’ z n wygenerowanego przez akcję a mamy:
h(n) ≤ c(n, a, n′) + h(n′).
Jest to forma nierówności trójkąta, która stanowi, że bok trójkąta nie może być dłuższy niż suma pozostałych dwóch boków. Przykładem spójnej heurystyki jest odległość w linii prostej hSLD, którą wykorzystaliśmy, aby dostać się do Bukaresztu.
Każda spójna heurystyka jest dopuszczalna (ale nie odwrotnie), więc przy spójnej heurystyce A* jest optymalny pod względem kosztów. Ponadto, dzięki spójnej heurystyce, za pierwszym razem, gdy osiągniemy stan, będzie on na optymalnej ścieżce, więc nigdy nie będziemy musieli ponownie dodawać stanu do granicy i nigdy nie musimy zmieniać wpisu w osiągniętym. Ale przy niespójnej heurystyce możemy skończyć z wieloma ścieżkami osiągającymi ten sam stan, a jeśli każda nowa ścieżka ma niższy koszt ścieżki niż poprzednia, wtedy skończymy z wieloma węzłami dla tego stanu na granicy, co będzie nas kosztować zarówno czas, jak i przestrzeń. Z tego powodu niektóre implementacje A* dbają o to, aby tylko raz wprowadzić stan do granicy, a jeśli zostanie znaleziona lepsza ścieżka do stanu, wszystkie następniki stanu są aktualizowane (co wymaga, aby węzły miały również wskaźniki podrzędne jako wskaźniki nadrzędne). Te komplikacje doprowadziły wielu realizatorów do uniknięcia niespójnych heurystyk, ale Felner przekonuje, że w praktyce najgorsze efekty zdarzają się rzadko i nie należy obawiać się niekonsekwentnych heurystyk.
Przy niedopuszczalnej heurystyce A* może być lub nie być optymalny pod względem kosztów. Oto dwa przypadki, w których tak jest: Po pierwsze, jeśli istnieje chociaż jedna ścieżka optymalna pod względem kosztów, na której h(n) jest dopuszczalne dla wszystkich n węzłów na ścieżce, wtedy ta ścieżka zostanie znaleziona, bez względu na to, co mówi heurystyka
stwierdza poza ścieżką. Po drugie, jeśli optymalne rozwiązanie ma koszt C*, a drugie najlepsze ma koszt C2 i h(n), jeśli przeszacowuje niektóre koszty, ale nigdy o więcej niż C2 – C*, to A* gwarantuje zwrócenie rozwiązań optymalnych kosztowo.