Głównym problemem z A* jest wykorzystanie pamięci. W tej sekcji omówimy kilka sztuczek implementacyjnych, które oszczędzają miejsce, a następnie kilka zupełnie nowych algorytmów, które lepiej wykorzystują dostępną przestrzeń. Pamięć jest podzielona między stany graniczne i osiągnięte. W naszej implementacji wyszukiwania best-first stan, który znajduje się na granicy, jest przechowywany w dwóch miejscach: jako węzeł na granicy (abyśmy mogli zdecydować, co dalej rozwinąć) oraz jako wpis w tabeli stanów osiągniętych (więc wiemy jeśli odwiedziliśmy ten stan wcześniej). W przypadku wielu problemów (takich jak eksploracja siatki) to powielanie nie stanowi problemu, ponieważ rozmiar granicy jest znacznie mniejszy niż osiągnięty, więc powielanie stanów na granicy wymaga stosunkowo niewielkiej ilości pamięci. Ale niektóre implementacje utrzymują stan tylko w jednym z dwóch miejsc, oszczędzając trochę miejsca kosztem komplikacji (i być może spowolnienia) algorytmu. Inną możliwością jest usunięcie stanów z osiągniętych, kiedy możemy udowodnić, że nie są już potrzebne. W przypadku niektórych problemów możemy użyć właściwości separacji (Rysunek 3.6 na stronie 72) wraz z zakazem wykonywania zawracania, aby upewnić się, że wszystkie działania przesuną się na zewnątrz z granicy lub do innego stanu granicznego. W takim przypadku wystarczy sprawdzić granicę pod kątem zbędnych ścieżek i możemy wyeliminować osiągniętą tabelę. W przypadku innych problemów możemy zachować liczniki odwołań wskazujące, ile razy stan został osiągnięty i usunąć go z osiągniętej tabeli, gdy nie ma więcej sposobów na osiągnięcie stanu. Na przykład w świecie z siatką, w którym każdy stan można osiągnąć tylko od czterech sąsiadów, po czterokrotnym osiągnięciu stanu możemy usunąć go z tabeli. Rozważmy teraz nowe algorytmy, które mają na celu oszczędzanie pamięci.
Wyszukiwanie wiązki ogranicza rozmiar granicy. Najprostszym podejściem jest zachowanie tylko węzłów z najlepszymi wynikami, odrzucając wszelkie inne rozwinięte węzły. To oczywiście sprawia, że wyszukiwanie jest niekompletne i nieoptymalne, ale możemy zdecydować się na dobre wykorzystanie dostępnej pamięci, a algorytm działa szybko, ponieważ rozszerza mniej węzłów. W przypadku wielu problemów może znaleźć dobre, prawie optymalne rozwiązania. Możesz myśleć o przeszukiwaniu o jednolitym koszcie lub A* jako o rozchodzeniu się wszędzie w koncentrycznych konturach, a o przeszukiwaniu wiązką jako o badaniu tylko skupionej części tych konturów, części, która zawiera najlepszych kandydatów. Alternatywna wersja wyszukiwania wiązki nie utrzymuje ścisłego limitu rozmiaru granicy, ale zamiast tego utrzymuje każdy węzeł, którego -wynik mieści się w najlepszym -wyniku. W ten sposób, gdy istnieje kilka węzłów o silnej punktacji, tylko kilka zostanie zachowanych, ale jeśli nie ma żadnych silnych węzłów, zostanie zachowanych więcej, dopóki nie pojawi się silny.
Pogłębiające iteracyjne przeszukiwanie A* (IDA*) jest dla A* tym, czym iteracyjne-pogłębiające przeszukiwanie jest od pierwszego w głąb: IDA* daje nam korzyści z A* bez konieczności zachowywania w pamięci wszystkich osiągniętych stanów, kosztem odwiedzenia niektórych stanów wiele razy. Jest to bardzo ważny i powszechnie stosowany algorytm rozwiązywania problemów, które nie mieszczą się w pamięci. W standardowym pogłębianiu iteracyjnym odcięciem jest głębokość, która jest zwiększana o jedną w każdej iteracji. W IDA* punktem odcięcia jest koszt f ( g+h); w każdej iteracji wartość odcięcia jest najmniejszym kosztem dowolnego węzła, który przekroczył wartość odcięcia w poprzedniej iteracji. Innymi słowy , każda iteracja wyczerpująco przeszukuje -kontur, znajduje węzeł tuż za tym konturem i używa -kosztu tego węzła jako następnego konturu. W przypadku problemów, takich jak 8-puzzle, w których koszt każdej ścieżki jest liczbą całkowitą, działa to bardzo dobrze, powodując stały postęp w kierunku celu w każdej iteracji. Jeśli optymalne rozwiązanie kosztuje C* , to nie może być więcej niż C* iteracji (na przykład nie więcej niż 31 iteracji na najtrudniejszych 8-zagadkowych problemach). Ale w przypadku problemu, w którym każdy węzeł ma inny koszt f, każdy nowy kontur może zawierać tylko jeden nowy węzeł, a liczba iteracji może być równa liczbie stanów.
Rekurencyjne przeszukiwanie „najlepszy-pierwszy” (RBFS) próbuje naśladować działanie standardowego przeszukiwania „najlepszy-pierwszy”, ale używa tylko przestrzeni liniowej.

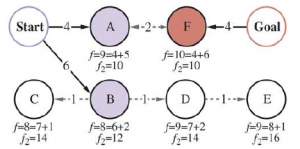
RBFS przypomina rekurencyjne wyszukiwanie wgłębne, ale zamiast kontynuować w nieskończoność bieżącą ścieżkę, używa zmiennej _limit do śledzenia wartości f najlepszej alternatywnej ścieżki dostępnej od dowolnego przodka bieżącego węzła. Jeśli bieżący węzeł przekroczy ten limit, rekursja zostanie cofnięta do alternatywnej ścieżki. Gdy rekursja się rozwija, RBFS zastępuje wartość f każdego węzła na ścieżce wartością z kopii zapasowej — najlepszą wartością f jego dzieci. W ten sposób RBFS zapamiętuje wartość f najlepszego liścia w zapomnianym poddrzewie i dlatego może zdecydować, czy warto ponownie rozwinąć poddrzewo w późniejszym czasie. Rysunek pokazuje, w jaki sposób RBFS dociera do Bukaresztu.
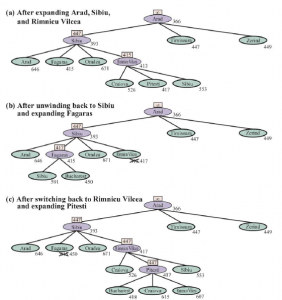
Etapy w RBFS szukają najkrótszej trasy do Bukaresztu. Wartość f-limit dla każdego wywołania rekurencyjnego jest pokazana na górze każdego bieżącego węzła, a każdy węzeł jest oznaczony swoim kosztem f. (a) Ścieżka przez Rimnicu Vilcea jest kontynuowana, aż aktualnie najlepszy liść (Pitesti) ma wartość gorszą niż najlepsza alternatywa Ath (Fagaras). (b) Rekurencja rozwija się i najlepsza wartość liścia zapomnianego poddrzewa (417) jest kopiowana do Rimnicu Vilcea; następnie Fagaras jest rozwijany, odsłaniając najlepszą wartość liścia wynoszącą 450. (c) Rekurencja rozwija się i najlepsza wartość liścia zapomnianego poddrzewa (450) jest kopiowana do Fagarasa; następnie rozbudowuje się Rimnicu Vilcea. Tym razem, ponieważ najlepsza alternatywna droga (przez Timisoarę) kosztuje co najmniej 447, ekspansja trwa dalej do Bukaresztu.
RBFS jest nieco bardziej wydajny niż IDA*, ale nadal cierpi z powodu nadmiernej regeneracji węzłów. W przykładzie na rysunku 3.23 RBFS podąża ścieżką przez Rimnicu Vilcea, następnie „zmienia zdanie” i próbuje Fagaras, a następnie ponownie zmienia zdanie. Te zmiany myślenia zachodzą, ponieważ za każdym razem, gdy bieżąca najlepsza ścieżka jest rozszerzana, jej wartość f prawdopodobnie wzrośnie — h jest zwykle mniej optymistyczny dla węzłów bliższych celowi. Kiedy tak się stanie, druga najlepsza ścieżka może stać się najlepszą ścieżką, więc poszukiwanie musi się cofnąć, aby nią podążać. Każda zmiana myślenia odpowiada iteracji IDA* i może wymagać wielu ponownych rozszerzeń zapomnianych węzłów, aby odtworzyć najlepszą ścieżkę i rozszerzyć ją o kolejny węzeł.
RBFS jest optymalny, jeśli dopuszczalna jest funkcja heurystyczna h(n). Jego złożoność przestrzenna jest liniowa na głębokości najgłębszego optymalnego rozwiązania, ale jego złożoność czasowa jest raczej trudna do scharakteryzowania: zależy ona zarówno od dokładności funkcji heurystycznej, jak i od tego, jak często zmienia się najlepsza ścieżka w miarę rozszerzania węzłów. Rozszerza węzły w kolejności rosnącej f -score, nawet jeśli f jest niemonotoniczne.
IDA* i RBFS cierpią z powodu używania zbyt małej ilości pamięci. Między iteracjami IDA* zachowuje tylko jedną liczbę: aktualny limit kosztów F. RBFS zachowuje więcej informacji w pamięci, ale wykorzystuje tylko przestrzeń liniową: nawet jeśli więcej pamięci byłoby dostępne, RBFS nie ma możliwości jej wykorzystania. Ponieważ zapominają o większości tego, co zrobili, oba algorytmy mogą w efekcie wielokrotnie ponownie badać te same stany. Rozsądne wydaje się zatem określenie, ile mamy dostępnej pamięci i umożliwienie algorytmowi wykorzystania jej całej. Dwa algorytmy, które to robią, to MA* (A* ograniczone do pamięci) i SMA* (uproszczone MA*). SMA* jest dużo prostsze, więc to opiszemy. SMA* postępuje podobnie jak A*, rozwijając najlepszy liść aż do zapełnienia pamięci. W tym momencie nie może dodać nowego węzła do drzewa wyszukiwania bez usunięcia starego. SMA* zawsze odrzuca najgorszy węzeł liścia — ten z najwyższą wartością f. Podobnie jak RBFS, SMA* następnie tworzy kopię zapasową wartości zapomnianego węzła do swojego rodzica. W ten sposób przodek zapomnianego poddrzewa zna jakość najlepszej ścieżki w tym poddrzewie. Dzięki tym informacjom SMA* regeneruje poddrzewo tylko wtedy, gdy wszystkie inne ścieżki wyglądają gorzej niż ścieżka, którą zapomniała. Innym sposobem powiedzenia tego jest to, że jeśli zapomnimy o wszystkich potomkach węzła n, to nie będziemy wiedzieć, w którą stronę przejść od n , ale nadal będziemy mieli wyobrażenie o tym, jak opłaca się iść gdziekolwiek od n. Cały algorytm jest opisany w internetowym repozytorium kodu dołączonym do tej książki. Warto wspomnieć o jednej subtelności. Powiedzieliśmy, że SMA* rozwija najlepszy liść i usuwa najgorszy liść. Co się stanie, jeśli wszystkie węzły liści mają tę samą wartość f? Aby uniknąć wybierania tego samego węzła do usunięcia i rozwinięcia, SMA* rozwija najnowszy najlepszy liść i usuwa najstarszy najgorszy liść. Są one zbieżne, gdy istnieje tylko jeden liść, ale w takim przypadku bieżące drzewo wyszukiwania musi być pojedynczą ścieżką od korzenia do liścia, która wypełnia całą pamięć. Jeśli liść nie jest węzłem celu, to nawet jeśli znajduje się na optymalnej ścieżce rozwiązania, rozwiązanie to nie jest osiągalne z dostępną pamięcią. Dlatego węzeł można odrzucić dokładnie tak, jakby nie miał następców. SMA* jest zakończona, jeśli istnieje jakiekolwiek osiągalne rozwiązanie, to znaczy, jeśli głębokość najpłytszego węzła docelowego jest mniejsza niż rozmiar pamięci (wyrażony w węzłach). Optymalne jest, jeśli osiągalne jest jakiekolwiek optymalne rozwiązanie; w przeciwnym razie zwraca najlepsze osiągalne rozwiązanie. W praktyce SMA* jest dość solidnym wyborem do znajdowania optymalnych rozwiązań, szczególnie gdy przestrzeń stanów jest grafem, koszty działania nie są jednolite, a generowanie węzłów jest drogie w porównaniu z kosztami utrzymania granicy i osiągniętego zbioru. Jednak w przypadku bardzo trudnych problemów często zdarza się, że SMA* jest zmuszony do ciągłego przełączania się między wieloma potencjalnymi ścieżkami rozwiązania, z których tylko mały podzbiór może zmieścić się w pamięci. (Przypomina to problem thrashingu w systemach stronicowania dysków.) Następnie dodatkowy czas wymagany do powtórnej regeneracji tych samych węzłów oznacza, że problemy, które byłyby praktycznie możliwe do rozwiązania przez A* przy nieograniczonej ilości pamięci, stają się nie do rozwiązania dla SMA*. Innymi słowy, ograniczenia pamięci mogą sprawić, że problem będzie trudny do rozwiązania z punktu widzenia czasu obliczeń. Chociaż żadna aktualna teoria nie wyjaśnia kompromisu między czasem a pamięcią, wydaje się, że jest to nieunikniony problem. Jedynym wyjściem jest porzucenie wymogu optymalności.