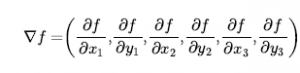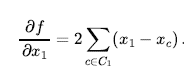Algorytm wyszukiwania wspinaczki pokazano poniżej

Śledzi jeden aktualny stan i przy każdej iteracji przechodzi do sąsiedniego stanu o najwyższej wartości, to znaczy kieruje się w kierunku, który zapewnia najbardziej strome wznoszenie. Kończy się, gdy osiągnie „szczyt”, w którym żaden sąsiad nie ma wyższej wartości. Wspinaczka górska nie wykracza poza bezpośrednich sąsiadów obecnego stanu. Przypomina to próbę znalezienia szczytu Mount Everestu w gęstej mgle podczas cierpienia na amnezję. Zwróć uwagę, że jeden ze sposobów korzystania z wyszukiwania wspinaczki górskiej polega na użyciu negatywu heurystycznej funkcji kosztu jako funkcji celu; który będzie wspinał się lokalnie do stanu o najmniejszej heurystycznej odległości do celu. Aby zilustrować wspinaczkę po wzgórzach, użyjemy problemu 8-królowych.
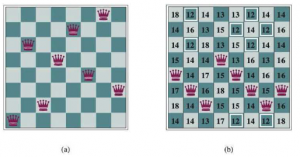
(a) Problem 8 hetmanów: umieść 8 hetmanów na szachownicy tak, aby żaden hetman nie atakował drugiego. (Hetman atakuje dowolną figurę w tym samym rzędzie, kolumnie lub po przekątnej.) Ta pozycja jest prawie rozwiązaniem, z wyjątkiem dwóch hetmanów w czwartej i siódmej kolumnie, które atakują się nawzajem po przekątnej. (b) Stan 8 hetmanów z heurystycznym kosztorysem h = 17. Plansza pokazuje wartość dla każdego możliwego następcy uzyskanego przez przesunięcie hetmana w jej kolumnie. Jest 8 ruchów, które są remisowane najlepiej, z h = 12 . Algorytm pokonywania wzniesień wybierze jeden z nich.
Użyjemy sformułowania pełnego stanu, co oznacza, że każdy stan ma wszystkie składniki rozwiązania, ale nie wszystkie mogą być we właściwym miejscu. W tym przypadku każdy stan ma na planszy 8 hetmanów, po jednej na kolumnę. Stan początkowy wybierany jest losowo, a następcami stanu są wszystkie możliwe stany generowane przez przeniesienie jednej hetmanki do innego pola w tej samej kolumnie (a więc każdy stan ma 8 x 7 = 56 następców). Heurystyczna funkcja kosztu to liczba par królowych, które atakują się nawzajem; będzie to zero tylko dla rozwiązań. (Liczy się jako atak, jeśli dwa pionki znajdują się w tej samej linii, nawet jeśli znajduje się między nimi pionek). Rysunek (b) pokazuje stan, w którym h = 17 . Rysunek przedstawia również wartości wszystkich jego następców.
Wspinaczka górska jest czasami nazywana chciwym poszukiwaniem lokalnym, ponieważ chwyta stan dobrego sąsiada, nie myśląc z wyprzedzeniem o tym, gdzie iść dalej. Chociaż chciwość jest uważana za jeden z siedmiu grzechów głównych, okazuje się, że algorytmy chciwości często działają całkiem nieźle. Wspinaczka po wzgórzach może szybko poczynić postępy w kierunku rozwiązania problemu, ponieważ zazwyczaj dość łatwo jest poprawić zły stan. Na przykład ze stanu z rysunku 4.3(b) wystarczy pięć kroków, aby osiągnąć stan z rysunku (a), który ma h = 1 i jest prawie rozwiązaniem. Niestety, wspinaczka górska może utknąć z jednego z następujących powodów:
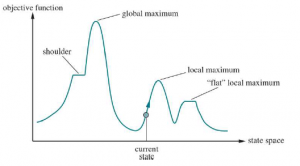
* LOCAL MAXIMA: Lokalne maksimum to szczyt, który jest wyższy niż każdy z sąsiednich stanów, ale niższy niż globalne maksimum. Algorytmy pokonywania wzniesień, które osiągną okolice lokalnego maksimum, zostaną przesunięte w górę w kierunku szczytu, ale utkną wtedy, nie mając dokąd pójść. Rysunek 4.1 ilustruje problem schematycznie. Mówiąc konkretniej, stan na rysunku 4.3(a) jest lokalnym maksimum (tj. lokalnym minimum kosztu); każdy ruch jednej hetmana pogarsza sytuację.
* GRZEBIE: Grzbiet pokazano na rysunku.
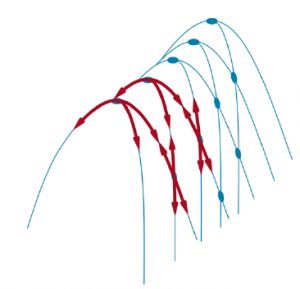
Ilustracja wyjaśniająca, dlaczego grzbiety utrudniają wspinaczkę na wzgórza. Siatka stanów (ciemne koła) nakłada się na grzbiet wznoszący się od lewej do prawej, tworząc ciąg lokalnych maksimów, które nie są bezpośrednio ze sobą połączone. Od każdego lokalnego maksimum wszystkie dostępne akcje kierują się w dół. Takie topologie są powszechne w niskowymiarowych przestrzeniach stanów, takich jak punkty na dwuwymiarowej płaszczyźnie. Ale w przestrzeniach stanów o setkach lub tysiącach wymiarów, ten intuicyjny obraz nie sprawdza się i zazwyczaj istnieje przynajmniej kilka wymiarów, które umożliwiają ucieczkę z grzbietów i płaskowyżów. Grzbiety tworzą sekwencję lokalnych maksimów, która jest bardzo trudna do nawigacji dla zachłannych algorytmów * PLATEAUS: Płaskowyż to płaski obszar krajobrazu przestrzeni stanów. Może to być płaskie maksimum lokalne, z którego nie ma wyjścia pod górę, lub pobocze, z którego możliwy jest postęp. Poszukiwanie wspinaczki może się zgubić wędrując po płaskowyżu.
W każdym przypadku algorytm osiąga punkt, w którym nie następuje żaden postęp. Zaczynając od losowo wygenerowanego stanu 8 królowych, wspinaczka na najbardziej strome wzgórze utknie w 86% przypadków, rozwiązując tylko 14% przypadków problemowych. Z drugiej strony działa szybko, wykonując średnio tylko 4 kroki, gdy się powiedzie, i 3, gdy utknie – nieźle jak na przestrzeń stanów z 88 ≈ 17 milionami stanów. Jak możemy rozwiązać więcej problemów? Jedną z odpowiedzi jest pójście dalej, gdy osiągniemy plateau – aby pozwolić na ruch w bok w nadziei, że plateau jest naprawdę ramię . Ale jeśli faktycznie jesteśmy na płaskim lokalnym maksimum, to takie podejście będzie wędrować po płaskowyżu na zawsze. Dlatego możemy ograniczyć liczbę kolejnych ruchów w bok, zatrzymując się po, powiedzmy, 100 kolejnych ruchach w bok. Zwiększa to odsetek przypadków problemów rozwiązanych przez wspinaczkę pod górę z 14% do 94%. Sukces ma swoją cenę: algorytm średnio około 21 kroków dla każdego udanego wystąpienia i 64 dla każdego niepowodzenia.
Wynaleziono wiele wariantów wspinaczki górskiej. Wspinaczka stochastyczna wybiera losowo spośród ruchów pod górę; prawdopodobieństwo wyboru może się różnić w zależności od stromości podjazdu. Zwykle zbiega się to wolniej niż najbardziej strome podejście, ale w niektórych krajobrazach stanowych znajduje lepsze rozwiązania. Wspinaczka górska pierwszego wyboru wprowadza stochastyczne wspinanie się na wzniesienia poprzez losowe generowanie następców, dopóki nie zostanie wygenerowany jeden, który jest lepszy niż stan obecny. To dobra strategia, gdy państwo ma wielu (np. tysiące) następców.
Innym wariantem jest wspinaczka górska z losowym ponownym startem, która przyjmuje powiedzenie: „Jeśli na początku ci się nie uda, spróbuj, spróbuj ponownie”. Przeprowadza serię poszukiwań wspinaczkowych od losowo generowanych stanów początkowych, aż do znalezienia celu. Jest kompletny z prawdopodobieństwem 1, ponieważ ostatecznie wygeneruje stan docelowy jako stan początkowy. Jeśli każde wyszukiwanie wspinaczki ma prawdopodobieństwo powodzenia, oczekiwana liczba wymaganych ponownych uruchomień wynosi 1/p . W przypadku 8-kobietowych instancji bez dozwolonych ruchów na boki, p ≈ 14 , więc potrzebujemy około 7 iteracji, aby znaleźć cel (6 porażek i 1 sukces). Oczekiwana liczba kroków to koszt jednej udanej iteracji plus (1-p)/p razy koszt niepowodzenia, czyli łącznie około 22 kroki. Kiedy dopuszczamy ruchy boczne 1/0,94 ≈ 1,06, potrzebne są średnio iteracje i (1 x 21) + (0,06/0,94) x 64 ≈ 25 kroków. W przypadku 8-kobiet wspinanie się na wzgórze z losowym restartem jest naprawdę bardzo skuteczne. Nawet dla trzech milionów królowych podejście może znaleźć rozwiązanie w ciągu kilku sekund. Sukces wspinaczki górskiej zależy w dużej mierze od kształtu krajobrazu przestrzeni stanowej: jeśli jest niewiele lokalnych maksimów i płaskowyżów, wspinaczka górska z przypadkowym ponownym startem bardzo szybko znajdzie dobre rozwiązanie. Z drugiej strony, wiele prawdziwych problemów ma krajobraz, który bardziej przypomina rozsianą rodzinę łysiejących jeżozwierz na płaskiej podłodze, z miniaturowymi jeżozwierzami żyjącymi na czubku każdej igły jeżozwierza. Problemy NP-trudne mają wykładniczą liczbę lokalnych maksimów, na których można utknąć. Mimo to po niewielkiej liczbie ponownych uruchomień często można znaleźć dość dobre lokalne maksimum.