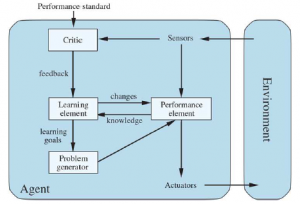
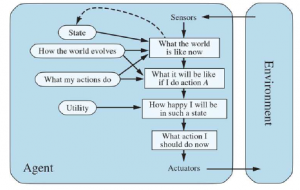
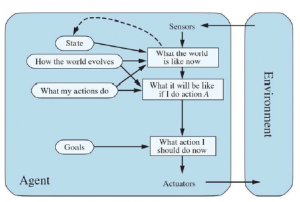
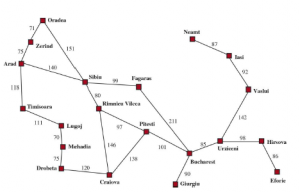
Wyobraź sobie agenta cieszącego się wakacjami w Rumunii. Agent chce podziwiać widoki, poprawić swój rumuński, cieszyć się życiem nocnym, unikać kaca i tak dalej. Problem decyzyjny jest złożony. Załóżmy teraz, że agent jest obecnie w mieście Arad i ma bezzwrotny bilet na lot z Bukaresztu następnego dnia. Agent obserwuje znaki drogowe i widzi, że z Aradu wychodzą trzy drogi: jedna w kierunku Sibiu, jedna do Timisoary i jedna do Zerind. Żadne z nich nie jest celem, więc dopóki agent nie zna geografii Rumunii, nie będzie wiedział, którą drogą podążać. Jeśli agent nie ma dodatkowych informacji — to znaczy, jeśli środowisko jest nieznane — agent nie może zrobić nic lepszego niż losowe wykonanie jednej z akcji. Ta smutna sytuacja została omówiona później . Tu założymy, że nasi agenci zawsze mają dostęp do informacji o świecie, takich jak mapa na rysunku .
Dzięki tym informacjom agent może śledzić ten czterofazowy proces rozwiązywania problemów:
* Sformułowanie celu: Agent przyjmuje cel dotarcia do Bukaresztu. Cele organizują zachowanie, ograniczając cele, a tym samym działania, które należy wziąć pod uwagę.
* SFORMULOWANIE PROBLEMU: Agent opracowuje opis stanów i działań niezbędnych do osiągnięcia celu – abstrakcyjnego modelu odpowiedniej części świata. Dla naszego agenta dobrym modelem jest rozważenie czynności przemieszczania się z jednego miasta do sąsiedniego miasta, a zatem jedynym faktem o stanie świata, który zmieni się w wyniku działania, jest obecne miasto.
* WYSZUKIWANIE: Przed podjęciem jakichkolwiek działań w świecie rzeczywistym agent symuluje sekwencje działań w swoim modelu, szukając, aż znajdzie sekwencję działań, która osiągnie cel. Taka sekwencja nazywana jest rozwiązaniem. Agent może być zmuszony do zasymulowania wielu sekwencji, które nie osiągną celu, ale w końcu znajdzie rozwiązanie (takie jak przejście z Arad do Sybinu, Fagaras do Bukaresztu) lub stwierdzi, że żadne rozwiązanie nie jest możliwe.
* WYKONANIE: Agent może teraz wykonywać akcje w rozwiązaniu, pojedynczo. Ważną cechą jest to, że w całkowicie obserwowalnym, deterministycznym, znanym środowisku rozwiązaniem każdego problemu jest ustalona sekwencja działań: przejazd do Sybinu, potem Fagaras, potem Bukareszt. Jeśli model jest poprawny, to po znalezieniu rozwiązania agent może zignorować swoje spostrzeżenia podczas wykonywania działań – zamykając oczy, że tak powiem – ponieważ rozwiązanie gwarantuje, że doprowadzi do celu. Teoretycy sterowania nazywają to systemem otwartej pętli: ignorowanie percepcji przerywa pętlę między agentem a środowiskiem. Jeśli istnieje szansa, że model jest niepoprawny lub środowisko jest niedeterministyczne, agent byłby bezpieczniejszy
stosując podejście zamkniętej pętli, które monitoruje spostrzeżenia. W środowiskach częściowo obserwowalnych lub niedeterministycznych rozwiązaniem byłaby strategia rozgałęziania, która zaleca różne przyszłe działania w zależności od tego, jakie spostrzeżenia nadejdą. Na przykład agent może planować przejazd z Arad do Sibiu, ale może potrzebować planu awaryjnego na wypadek, gdyby przypadkowo dotarł do Zerind lub natrafił na tabliczkę z napisem „Drum Închis” (droga zamknięta).