Programy agentowe (bardzo wysokopoziomowe) opisaliśmy jako składające się z różnych komponentów, których funkcją jest odpowiadanie na pytania typu: „Jaki jest teraz świat?” „Co powinienem teraz zrobić?” „Co robią moje działania?” Następne pytanie dla studenta AI brzmi: „Jak, u licha, działają te komponenty?” Prawidłowa odpowiedź na to pytanie zajmuje około tysiąca stron, ale tutaj chcemy zwrócić uwagę czytelnika na kilka podstawowych różnic między różnymi sposobami, w jakie komponenty mogą reprezentować środowisko, w którym przebywa agent. Z grubsza mówiąc, możemy umieścić reprezentacje wzdłuż osi rosnącej złożoności i ekspresyjnej potęgi atomowej, podzielonej na czynniki i zorganizowanej. Aby zilustrować te pomysły, warto rozważyć konkretny komponent agenta, taki jak ten, który zajmuje się „Co robią moje działania”. Ten komponent opisuje zmiany, które mogą wystąpić w środowisku w wyniku podjęcia działania, a Rysunek przedstawia schematyczne przedstawienie tego, jak te przejścia mogą być reprezentowane
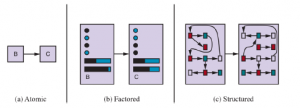
W atomowej reprezentacji każdy stan świata jest niepodzielny — nie ma wewnętrznej struktury. Rozważ zadanie znalezienia trasy dojazdu z jednego końca kraju do drugiego przez pewną sekwencję miast. W celu rozwiązania tego problemu może wystarczyć sprowadzenie stanu świata do nazwy miasta, w którym się znajdujemy — pojedynczego atomu wiedzy, „czarnej skrzynki”, której jedyną dostrzegalną własnością jest identyczność z lub różni się od innej czarnej skrzynki. Standardowe algorytmy leżące u podstaw wyszukiwania i gry , ukrytych modeli Markowa i procesów decyzyjnych Markowa działają z reprezentacjami atomowymi. Reprezentacja podzielona na czynniki dzieli każdy stan na ustalony zestaw zmiennych lub atrybutów, z których każdy może mieć wartość. Rozważ opis o wyższej wierności dla tego samego problemu z prowadzeniem pojazdu, w którym musimy zajmować się czymś więcej niż tylko lokalizacją atomową w jednym lub innym mieście; być może będziemy musieli zwrócić uwagę na to, ile paliwa znajduje się w zbiorniku, nasze aktualne współrzędne GPS, czy lampka ostrzegawcza oleju działa, ile mamy pieniędzy na opłaty drogowe, jaka stacja jest w radiu i tak dalej. Chociaż dwa różne stany atomowe nie mają ze sobą nic wspólnego — są to po prostu różne czarne skrzynki — dwa różne stany na czynniki mogą mieć wspólne atrybuty (takie jak bycie w określonej lokalizacji GPS), a inne (takie jak posiadanie dużej ilości gazu lub brak gazu). ; dzięki temu znacznie łatwiej jest wypracować sposób przekształcenia jednego stanu w inny. Wiele ważnych obszarów sztucznej inteligencji opiera się na reprezentacjach faktorycznych, w tym algorytmy spełniania ograniczeń, logika zdań , planowanie, sieci bayesowskie oraz różne algorytmy uczenia maszynowego. Z wielu powodów musimy rozumieć świat jako zawierający rzeczy, które są ze sobą powiązane, a nie tylko zmienne z wartościami. Na przykład możemy zauważyć, że duża ciężarówka przed nami wjeżdża tyłem na podjazd farmy mlecznej, ale luźna krowa blokuje drogę ciężarówce. Jest mało prawdopodobne, aby reprezentacja podzielona na czynniki była wstępnie wyposażona w atrybut TruckAheadBackingIntoDairyFarmDrivewayBlockedByLooseCow o wartości true lub false. Zamiast tego potrzebowalibyśmy ustrukturyzowanej reprezentacji, w której obiekty takie jak krowy i ciężarówki oraz ich różne i zróżnicowane relacje mogą być wyraźnie opisane. Reprezentacje strukturalne leżą u podstaw relacyjnych baz danych i logiki pierwszego rzędu, modeli prawdopodobieństwa pierwszego rzędu oraz większości zrozumienia języka naturalnego. W rzeczywistości wiele z tego, co ludzie wyrażają w języku naturalnym, dotyczy przedmiotów i ich relacji. Jak wspomnieliśmy wcześniej, oś, wzdłuż której leżą reprezentacje atomowe, czynnikowe i strukturalne, jest osią rosnącej ekspresji. Z grubsza mówiąc, bardziej ekspresyjna reprezentacja może uchwycić, przynajmniej tak samo zwięźle, wszystko, co można uchwycić mniej ekspresywną, plus trochę więcej. Często bardziej ekspresyjny język jest znacznie bardziej zwięzły; na przykład reguły gry w szachy mogą być napisane na jednej lub dwóch stronach w języku strukturalnej reprezentacji, takim jak logika pierwszego rzędu, ale wymagają tysięcy stron, gdy są napisane w języku reprezentacji faktorowej, takim jak logika zdań i około 1038 stron, gdy są napisane w języku język atomowy, taki jak język automatów skończonych. Z drugiej strony, rozumowanie i uczenie się stają się bardziej złożone wraz ze wzrostem siły wyrazu reprezentacji. Aby uzyskać korzyści płynące z wyrazistych reprezentacji przy jednoczesnym uniknięciu ich wad, inteligentne systemy dla świata rzeczywistego mogą wymagać jednoczesnej pracy we wszystkich punktach wzdłuż osi.
Inna oś reprezentacji obejmuje mapowanie pojęć do lokalizacji w pamięci fizycznej, czy to w komputerze, czy w mózgu. Jeśli istnieje mapowanie jeden-do-jednego między pojęciami a miejscami w pamięci, nazywamy to reprezentacją lokalistyczną. Z drugiej strony, jeśli reprezentacja koncepcji jest rozłożona na wiele lokalizacji w pamięci, a każde miejsce w pamięci jest wykorzystywane jako część reprezentacji wielu różnych koncepcji, nazywamy to reprezentacją rozproszoną. Reprezentacje rozproszone są bardziej odporne na zakłócenia i utratę informacji. W przypadku reprezentacji lokalnej mapowanie od koncepcji do lokalizacji w pamięci jest arbitralne, a jeśli błąd transmisji zniekształci kilka bitów, możemy pomylić ciężarówkę z niepowiązanym pojęciem rozejmu. Ale w przypadku reprezentacji rozproszonej możesz pomyśleć o każdym pojęciu reprezentującym punkt w przestrzeni wielowymiarowej, a jeśli zniekształcisz kilka bitów, przeniesiesz się do pobliskiego punktu w tej przestrzeni, który będzie miał podobne znaczenie.