Zanim przejdziemy do projektowania różnych algorytmów wyszukiwania, rozważymy kryteria wyboru spośród nich. Możemy ocenić wydajność algorytmu na cztery sposoby:
* KOMPLETNOŚĆ: Czy algorytm gwarantuje znalezienie rozwiązania, gdy jest, i prawidłowe zgłoszenie awarii, gdy nie ma?
* OPTYMALNOŚĆ KOSZTÓW: Czy znajduje rozwiązanie o najniższym koszcie ścieżki ze wszystkich rozwiązań?
* ZŁOŻONOŚĆ CZASOWA: Ile czasu zajmuje znalezienie rozwiązania? Można to zmierzyć w sekundach lub bardziej abstrakcyjnie na podstawie liczby rozważanych stanów i działań.
* KOMPLEKSOWOŚĆ PRZESTRZENI: Ile pamięci potrzeba do przeprowadzenia wyszukiwania?
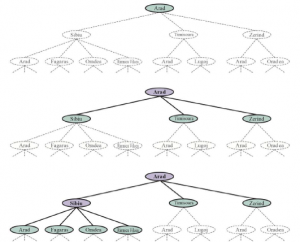
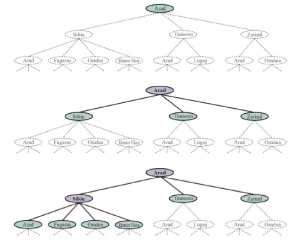
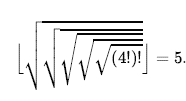
Aby zrozumieć kompletność, rozważ problem wyszukiwania z jednym celem. Ten cel może znajdować się w dowolnym miejscu w przestrzeni stanów; dlatego kompletny algorytm musi być w stanie systematycznie badać każdy stan, który jest osiągalny ze stanu początkowego. W skończonych przestrzeniach stanów, które są proste do osiągnięcia: tak długo, jak śledzimy ścieżki i odcinamy te, które są cyklami (np. Arad do Sibiu do Arad), w końcu dotrzemy do każdego osiągalnego stanu. W nieskończonych przestrzeniach stanów konieczna jest większa ostrożność. Na przykład algorytm, który wielokrotnie stosował operator „silnia” w zadaniu „4” Knutha, podążałby nieskończoną ścieżką od 4 do 4! do (4!)!, i tak dalej. Podobnie, na nieskończonej siatce bez przeszkód, wielokrotne poruszanie się do przodu w linii prostej również podąża nieskończoną ścieżką nowych stanów. W obu przypadkach algorytm nigdy nie powraca do stanu, który osiągnął wcześniej, ale jest niekompletny, ponieważ nigdy nie dochodzi do szerokich przestrzeni stanów. Aby być kompletnym, algorytm wyszukiwania musi być systematyczny w sposobie eksploracji nieskończonej przestrzeni stanów, upewniając się, że może ostatecznie osiągnąć dowolny stan, który jest połączony ze stanem początkowym. Na przykład w nieskończonej siatce jednym rodzajem systematycznego wyszukiwania jest spiralna ścieżka, która obejmuje wszystkie komórki znajdujące się kilka kroków od początku przed przejściem do komórek znajdujących się kilka kroków dalej. Niestety, w nieskończonej przestrzeni stanów bez rozwiązania, algorytm dźwięku musi kontynuować poszukiwania w nieskończoność; nie może zakończyć, ponieważ nie może wiedzieć, czy następny stan będzie celem.
Złożoność czasowa i przestrzenna jest rozpatrywana w odniesieniu do pewnej miary trudności problemu. W informatyce teoretycznej typową miarą jest rozmiar grafu w przestrzeni stanów |V| + |E|, gdzie |V| jest liczbą wierzchołków (węzłów stanu) grafu a |E| liczbą krawędzi (różnych par stan/działanie). Jest to właściwe, gdy wykres jest wyraźną strukturą danych, taką jak mapa Rumunii. Ale w wielu problemach AI graf jest reprezentowany tylko domyślnie przez stan początkowy, działania i model przejścia. W przypadku niejawnej przestrzeni stanów złożoność można mierzyć pod względem głębokości d lub liczby działań w optymalnym rozwiązaniu; maksymalna liczba akcji na dowolnej ścieżce m ; oraz współczynnik rozgałęzienia b lub liczbę następców węzła, które należy wziąć pod uwagę.