Wystarczy teorii, przejdźmy do działania budującego naszą własną aplikację. Aplikacja, którą zbudujemy, będzie korzystać z poprzedniego rozdziału, więc jeśli go nie czytałeś, zrób to. Pulpit nawigacyjny, który zbudujemy, będzie miał większy sens, jeśli to zrobisz. Ten pulpit nawigacyjny pokaże wykresy z punktami danych cenowych z symulacji danych z poprzedniego rozdziału, a także z obliczeń SMA, które opracowaliśmy. Co więcej, pozwoli nam to zbadać dane cenowe za pomocą dynamicznej tabeli. Przez dynamiczną rozumiemy, że reaguje na dane wejściowe użytkownika.
Konfigurowanie dystrybucji dwukolumnowej
Układ, który wybierzesz dla swojej aplikacji, zależy od jej celów. W takim przypadku wystarczy układ dwukolumnowy. Aby to osiągnąć, używamy funkcji fluidPage() i przypisujemy ją do obiektu ui. Ta funkcja dostosowuje zawartość do wymiarów przeglądarki internetowej:
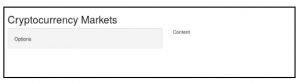
Wewnątrz fluidPage() używamy funkcji titlePanel() do podania tytułu naszej aplikacji i funkcji sidebarLayout() do stworzenia układu dwukolumnowego. Ta ostatnia funkcja wymaga wywołania w niej dwóch innych funkcji w celu utworzenia odpowiedniej zawartości dla każdej kolumny. Te dwie funkcje są nazywane sidebarPanel() i miniPanel() i otrzymują treść, którą chcemy w nich stworzyć jako parametry. Kolumna po lewej stronie będzie używana do wyświetlania dostępnych opcji dla użytkowników, a kolumna po prawej do wyświetlania rzeczywistej zawartości w wyniku danych wejściowych użytkownika, więc używamy niektórych ciągów znaków jako symboli zastępczych, które dokładnie opisują to:
ui <- fluidPage (
titlePanel(„Cryptocurrency Markets”),
sidebarLayout (
sidebarPanel(„Options”),
mainPanel(„Content”)
}
}
fuidPage() po prostu generuje HTML, który jest wysyłany do przeglądarki internetowej. Możesz wydrukować obiekt w konsoli R w miarę postępów w rozdziale, aby zobaczyć HTML, który utworzył. Ten kod utworzy bardzo podstawową strukturę, taką jak pokazano na następnym obrazku. W miarę postępów będziemy coraz bardziej skomplikować aplikację, ale musimy od czegoś zacząć. Jak widać, wywołania funkcji zagnieżdżania będą typowym wzorcem w obiekcie ui do tworzenia struktury aplikacji. Może to być trudne, a jeśli z jakiegoś powodu pominiesz gdzieś przecinek („ , ”), możesz znaleźć tajemniczą wiadomość, taką jak ta pokazana. W takim przypadku upewnienie się, że przecinki są poprawnie umieszczone, jest dobrym początkiem do naprawienia tego błędu:
Error in tag(„div”, list(…)) : argument is missing , with no default
Calls : fluidPages … tablesetPanel -> tabPanel -> div -> -> tag