Na koniec dodamy trochę interaktywności do naszego wykresu, implementując inny podobny wykres, który będzie wykazywał efekt powiększenia tego, który stworzyliśmy wcześniej. Chodzi o to, że możemy wybrać obszar wykresu, który właśnie utworzyliśmy, a ten, który umieścimy poniżej, zostanie zaktualizowany, aby pokazać tylko określony obszar, który wybraliśmy. Wydaje się interesujące, prawda? Aby to osiągnąć, musimy zmodyfikować plotOutput() wstawiony na końcu poprzedniej sekcji parametr brush z wywołaniem funkcji brushOpts() , która z kolei otrzyma nazwę unikalnego identyfikatora dla tworzonego przez nas wejścia pędzla. Ten parametr służy do tworzenia specjalnego typu danych wejściowych, który pobiera wybrany obszar z wykresu wyświetlanego w przeglądarce internetowej. Dodajemy również kolejny fluidRow() z innym plotOutput() tuż pod nim, aby zawierał wykres, który zapewni efekt powiększenia. Kod wygląda następująco:
tabPanel(
„Simple Moving Averages”,
value =1 ,
fluidRow(plotOutput(„graph_top”, brush = brushOpts(„graph_brush”))),
fluidRow(plotOutput(„graph_bottom”))
Teraz wartość reaktywna input$graph_brush będzie zawierała listę z czterema elementami wewnątrz xmin,xmax, ymin i ymax, które są współrzędnymi odpowiadającymi obszarowi wybranemu na górnym wykresie. Nasza funkcja reaktywna ranges() użyje ich do wysłania odpowiednich wartości jako granic do dolnego wykresu. Sposób działania polega na tym, że sprawdzi, czy input$graph_brush jest NULL, a jeśli nie, to znaczy, że obszar jest zaznaczony, zwróci listę z dwoma elementami x i y, gdzie każdy z tych elementów zawiera odpowiednie współrzędne. Jeśli input$graph_brush jest NULL, to elementy x i y zwróconej listy będą NULL, co sygnalizuje funkcję coord_cartesian(), której będziemy używać na wierzchu sma_graph(), aby uniknąć umieszczania jakichkolwiek ograniczeń na osiach wykresu. Rzeczywista funkcja jest pokazana w poniższym kodzie i podobnie jak inne funkcje utworzone za pomocą reactive() powinna zostać umieszczona wewnątrz funkcji server. Zauważ również, że musimy dokonać małej transformacji wartości dla osi x, ponieważ są one zwracane jako liczby całkowite, a nie daty, które są typem obiektu używanego ggplot() dla tęj osi. Po prostu używamy funkcji as.POSIXct() do przekształcania takich liczb całkowith do prawidłowych dat, używając oring =
„1970-01-01”, który jest tym, co ggplot() używa domyślnie. Jeśli nie dokonamy transformacji, otrzymamy błąd:
ranges <- reative ({
if (!is.null(input$graph_brush)) {
return(list (
x = c(as.POSIXct(input$graph_brush$xmin, origin = „1970-01-01”),
as.POSIXct(input$grpah_brush$xmax,
origin = „1970-01-01”)),
y = (input$graph_brush$ymin,
iput$graph_brush$ymax)
))
}
return(list(x = NULL, y = NULL))
}
Teraz jesteśmy w stanie utworzyć obserwatora output$bottom_graph, tak jak stworzyliśmy poprzedni wykres, ale w tym przypadku dodamy funkcję coord_cartesian() na górze obiektu wykresu zwróconego przez sma_graph(), aby ograniczyć wartości osi. Zauważ, że używamy expand = FALSE do wymuszenia ograniczeń pochodzących z funkcji reaktywnej ranges(), którą właśnie utworzyliśmy w poprzednim kodzie:
output$graph_bottom <- renderPlot( {
return(sma_graph(data () , sma() ) +
coord_cartesian(xlim = ranges () $x,
ylim = ranges()$y, expand = FALSE))
)
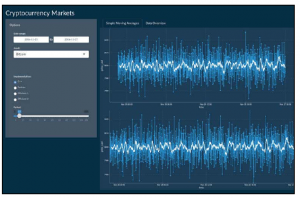
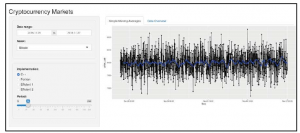
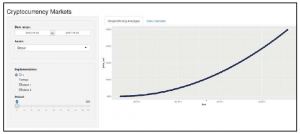
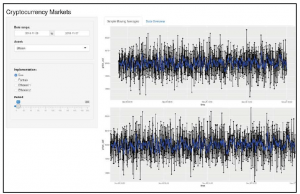
Po wprowadzeniu tych zmian powinniśmy osiągnąć zamierzony efekt. Aby to przetestować, możemy napisać aplikację i zobaczyć dwa identyczne wykresy jeden na drugim, jak pokazano na poniższym zrzucie ekranu:
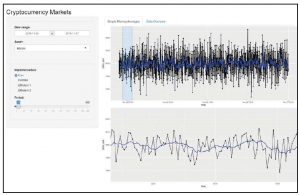
Jeśli jednak wybierzemy obszar na górnym wykresie, to wykres na dole powinien się zaktualizować, pokazując tylko tę konkretną część wykresu. Całkiem fajnie, prawda?
Na koniec powinieneś wiedzieć, że innym sposobem wprowadzenia interaktywnej grafiki jest użycie dobrze znanego języka JavaScript jak Plot.ly. Shiny tworzy strony internetowe, które używają JavaScript w tle, więc ta technika jest naturalna. Jest to jednak zaawansowana technika i jej użycie jest bardziej skomplikowane niż to, co tutaj pokazaliśmy, więc nie będziemy jej pokazywać, ale powinieneś wiedzieć, że jest to możliwe, jeśli chcesz wykonać ją samodzielnie.