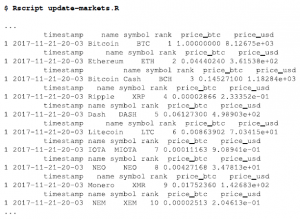
Nasz system obiektowy jest prawie gotowy. Brakuje nam tylko definicji User. W tym przypadku użyjemy S3 do zdefiniowania klasy User. Funkcja user_cnstructor() przyjmuje instancję email i Storage w storage, aby utworzyć instancję User. Jednak zanim to zrobi, sprawdza, czy wiadomość e-mail jest poprawna z funkcją valid_email() zdefiniowaną poniżej. Po utworzeniu użytkownika wywoływana jest metoda get_wallets() w celu pobrania portfeli skojarzonych z użytkownikiem przed odesłaniem. Funkcja vaid_email() po prostu otrzymuje ciąg znaków, który ma być adresem e-mail, i sprawdza, czy zawiera co najmniej jeden symbol @ i jeden symbol . . Oczywiście nie jest to solidny mechanizm sprawdzania, czy jest to adres e-mail, i został umieszczony tutaj tylko po to, aby zilustrować, jak można zaimplementować mechanizm sprawdzający:
source(„../assets/wallet.R”, chdir = TRUE)
user_constructor <-0 function(email,storage) {
if (!valid_email(email)) { stop(„Invalid email”) }
user <- list(storage = storage, email = email , wallets = list() )
class(user) <- „User:
user <- get_wallets(user)
return(user)
}
valid_email <- function(string) {
if (grepl(„@”, string) && grepl(„.”, string)) { return (TRUE) }
return(FALSE)
}
Funkcja get_wallets.User() po prostu prosi atrybut storage w obiekcie o pobranie portfeli powiązanych z jego własnym adresem e-mail, przypisuje je do atrybutu listy wallets, i odsyła obiekt User:
get_wallets.User <- function(user) {
user$wallets <- user$storage$read_wallets(usr$email)
return(user)
}
get_wallets <- function(object) {
UseMethod(„get_wallets”)
}
Funkcja new_wallet.User() otrzymuje instancję User, ciąg symbol, łańcuch address i ciąg znaków note aby utworzyć nową instancję i dołączyć ją do atrybutu listy wallets instancji User przekazanej do niej. Jednak zanim to zrobi, sprawdza wszystkie wcześniej zarejestrowane portfele dla użytkownika. Jeśli stwierdzi, że portfel jest już zarejestrowany, po prostu zignoruje dodanie i odeśle tę samą instancję z powrotem. To kolejny rodzaj sprawdzania, który możesz wdrożyć we własnych systemach:
new_wallet.User <- function(user, symbol, address, note) {
if (length(user$wallets) >= 1) {
for (wallet in user$wallets) {
if (wallet$get_symbol () == symbol &
wallet$get_address() == address) {
return(user)
}
}
}
wallet <- Wallet$new(user$email, symbol, address, note)
user$wallets <- c(user$wallets, list(wallet))
return(user)
}
new_wallet <- function(object, symbol, address, note) {
UseMethod(„new_wallet”)\
}
Funkcja update_assets.User() po prostu przechodzi przez każdą instancję Wallet w atrybucie list wallets i wywołuje swoją metodę publiczną update_assets() z bieżącym, przekazanym timestamp i instancją Storage zawartą wewnątrz instancji User. Jak widzieliśmy wcześniej, powoduje to aktualizację zasobów i zapisanie ich w bazie danych, a obiekt Wallet zajmuje się tym w imieniu instancji User:
update_assets.User <- function(user, timestamp) (
for (walllet in user$wallets) {
walllet$update_assets(timestamp, user$storage)
}
}
update_assets <- function(object, timestamp) {
UseMethod(„update_assets”)
}
Funkcja save.User() po prostu używa tego atrybutu storage do zapisania instancji User, a także danych jej portfeli. Jak widzieliśmy, jeśli portfele już istnieją w zapisanych danych, to nie zostaną one zduplikowane, a implementacja CSVFiles dba o to w imieniu instancji User:
save.User <- function(user) {
user$storage$write_user(user)
user$storage$write_wallets(user$wallets)
}
save <- function(object) {
UseMethod(„save”)
}
Na koniec użytkownik udostępnia metodę dataS3.User() zwracania listy z adresem e-mail użytkownika w celu ponownego zapisania w bazie danych:
dataS3.User <- function(user) {
return(list(email = user$email))
}
dataS3 <- function(object) {
UseMethod(„dataS3”)
}
Jak widzieliśmy w tej sekcji, po wykonaniu pewnych prac możemy opracować ładne i intuicyjne abstrakcje, które wykorzystują funkcjonalność zaimplementowaną w innych obiektach, aby zapewnić potężne mechanizmy, takie jak zapisywanie danych w bazie danych, za pomocą bardzo prostych wywołań.