“Wspomóż rozwój naszego Bloga. Kliknij w Reklamę. Nic nie tracisz a zyskujesz naszą wdzięczność … oraz lepsze, ciekawsze TEKSTY. Dziękujemy”
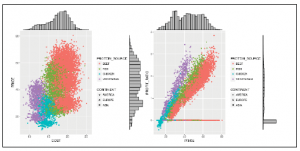
Problemem, który napotkasz podczas programowania, jest to, że czasami funkcja, którą uważasz za wystarczająco ogólną, musi zostać w jakiś sposób zmieniona. Czasami właściwą decyzją jest zmiana istniejącej funkcji, ale innym razem właściwą decyzją jest utworzenie nowej funkcji (być może na podstawie oryginalnej), którą można zmodyfikować w razie potrzeby bez łamania starego kodu, który ją używał. Dzieje się tak, gdy założenia dotyczące funkcji nie są spełnione i nie można jej łatwo dostosować. W naszym przypadku, co się stanie, jeśli będziemy chcieli wykorzystać dane clients do wykreślenia dat urodzenia naszych klientów za pomocą roku na osi x, miesiąca na osi y, koloru według płci i pokazania korekty oceny wielkość kropek? Cóż, założenia dotyczące danych osi x i osi y mogą zostać spełnione przy niewielkich przekształceniach danych, założenie dotyczące koloru jest już spełnione, ale założenie dotyczące rozmiaru wydaje się nie pasować do naszego poprzedniego modelu. W naszej funkcji graph_marginal_distributions() założyliśmy, że użyjemy shape jako czwartej zmiennej do reprezentowania zmiennych kategorialnych, ale wydaje się, że chociaż zmienna STARS jest technicznie czynnikiem, lepiej byłaby reprezentowana przy użyciu rozmiaru, a nie różnych kształtów. Fakt, że musimy zająć się osią x, osią y i założeniami dotyczącymi wielkości w specjalnych przypadkach dla danych clients, jest wystarczającym powodem, aby zdecydować się na stworzenie własnej funkcji na podstawie oryginalnej. Jeśli w pewnym momencie zechcemy połączyć te dwie funkcje w jedną, możemy to zrobić, ale na tym etapie nie ma potrzeby zbytniego komplikowania rzeczy dla siebie. W naszej funkcji graph_marginal_distributions_clients_birth_dates() wystarczy nam odebrać dane, nad którymi będziemy pracować (w tym przypadku cliets). Nie ma potrzeby stosowania innych parametrów, ponieważ wszystkie założenia zostaną w tym przypadku zakodowane na stałe w funkcji, ponieważ nie chcemy uogólniać kodu. Aby kod był bardziej czytelny, użyjemy krótkich nazw zmiennych, które będą zawierać ciąg znaków, którego użyjemy do stworzenia specyfikacji wykresu. Tym właśnie są te zmienne x, y, x_noise i y_noise. Jak wspomniano, musimy nieco przekształcić dane, zanim będziemy w stanie stworzyć wykres. Najpierw musimy zdezagregować BIRTH_DATE na BD_YEAR i BD_MOTH (BD jest skrótem od daty urodzenia (birth date)). Następnie dodajemy szum do dat, ponieważ gdybyśmy po prostu zachowali daty bez zmian, otrzymalibyśmy siatkę wartości, a nie rozkład, a to dlatego, że zarówno rok, jak i miesiąc są wartościami całkowitymi, więc byłoby dużo kropek jeden na drugim i dużo pustej przestrzeni między nimi, widzimy mieszaną wersję danych i dlatego musimy dodać do nich szum. Zobacz poniżej, jak obie te funkcje działają wewnętrznie. Po uzyskaniu naszych krótkich nazw i przekształceniu danych jesteśmy gotowi do utworzenia wykresu punktowego, tak jak robiliśmy to wcześniej. Tutaj pojawia się rozróżnienie między datami z hałasem i bez. Gdybyśmy użyli dat z szumem do wyświetlenia wartości tików dla osi, zobaczylibyśmy etykiety lat, takie jak 1953,51, 1973,85, 1993,23 i tak dalej. Oczywiście wyświetlanie osi roku z takimi wartościami nie jest intuicyjne. Podobnie dla osi y zobaczylibyśmy wartości miesięcy, takie jak 1,24, 4,09, 8,53 i tak dalej. Ten sam problem. Dlatego potrzebujemy dwie wersje danych, ta z szumem (wartościami rzeczywistymi), która jest używana do umieszczania punktów na wykresie, i ta bez szumu (wartości całkowite), która jest używana do wyświetlania wartości na osi. Na koniec dodajemy etykiety osi i wysyłamy wykres przez funkcję ggMarginal, tak jak to zrobiliśmy wcześniej:
graph_marginal_distributios_client_birth_dates <- function(data) {
x<- „BD_YEAR”
y <- „BD_MONTH”
x_noise <- „BD_YEAR_NOISE”
y_noise <- „BD_MONTH_NOISE”
data <- disaggregate_dates(data)
data <- add_dates_noise(data)
graph <- ggplot(data, aes_string(x_noise, y_noise, size = „STARS”, color = „GENDER”)) +
scale_x_continuous(breaks = seq(min(data[, x], max(data[, x]), by = 5)) +
scale_y_continuous(breaks = seq(min(datat[, y]) , max(data[, y]))) + geom_point() + ylab(„MONTH”) + xlab(„YEAR”)
return(ggMargina(graph, type = „historgam”))
}
disaggregate_dates <- funtion(data) {
}
disaggregate_dates <- function(data) {
data$BD_YEAR <- as.numeric(format(data$BIRTH_DATE, „%Y”))
data$BD_MONTH<- as.numeric(format(data$BIRTH_DATE, „%m”))
return(data)
}
Dodawanie szumu do danych jest proste, po prostu tworzymy nowe zmienne (BD_YEAR_NOISE i BD_MONTH_NOISE), które mają oryginał (liczbę całkowitą) wartości i dodajemy liczbę losową z rozkładu normalnego ze średnią 0 i odchyleniem standardowym 0,5. Potrzebujemy małego odchylenia standardowego, aby upewnić się, że nasze dane nie ulegają zbyt dużym zmianom:
add_dates_noise <- funtion(data) {
year_noise <- rnorm(nrow(data), sd = 0.5)
month_noise <- rnorm(nrow(data), sd= 0.5)
data$BD_YEAR_NOISE <- data$BD_YEAR + year_noise
data$BD_MOTH_NOISE <- data$BD_MONTH + month_noise
return(data)
}
Aby zdezagregować daty, po prostu tworzymy nowe zmienne (BD_YEAR i BD_MOTH), które zawierają odpowiednią wartość daty wyodrębnioną przy użyciu specyfikacji formatu daty, która zawiera R (%Y dla roku i %m dla miesiąca numerycznego) przekonwertowane na liczby (abyśmy mogli dodać do nich szum i je wykreślić). Przyjrzyjmy się datom urodzenia klienta za pomocą wykresu:
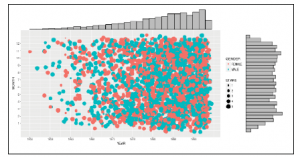
Teraz możemy łatwo utworzyć ten wykres w dowolnym momencie, bez martwienia się o szczegóły, jak go utworzyć za pomocą następującego kodu:
graph_marginal_distributions_lient_birth_dates(clients)