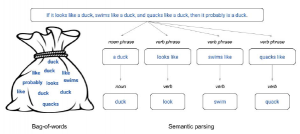
Analiza tekstu to proces uzyskiwania informacji z tekstu. Informacje są zwykle uzyskiwane za pomocą technik, takich jak IR, NLP i SL, i obejmują one strukturyzację tekstu, wyprowadzanie wzorców z ustrukturyzowanych danych, a na końcu ocenę i interpretację wyników. Podstawowymi modelami używanymi do analizy tekstu są modele bag-of-words, model przestrzeni wektorowej i semantyczny model analizy. Model worka słów to uproszczona reprezentacja tekstu, w której tekst (w naszym przypadku recenzja) jest reprezentowany jako zbiór jego terminów (słów), pomijając gramatykę i kolejność słów, ale zachowując wielość (stąd termin torba). Po przekształceniu tekstu w worek słów i uporządkowaniu w korpus (uporządkowany zbiór danych tekstowych), możemy obliczyć różne miary, aby scharakteryzować tekst w przestrzeni wektorowej. Model bag-of-words jest powszechnie stosowany w metodach SL i będziemy go używać z losowymi lasami w tej części. W praktyce służy jako narzędzie do generowania cech. Poniższy obraz wyjaśnia model worka słów:
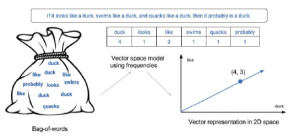
Model przestrzeni wektorowej wykorzystuje zbiór słów wyodrębniony z dokumentów w celu utworzenia wektora cech dla każdego tekstu, gdzie każdy element jest terminem, a wartość elementu jest wagą terminu. Termin waga może być wartością binarną (1 oznacza, że termin wystąpił w dokumencie, a 0 oznacza, że tak się nie stało), wartością częstotliwości terminu (TF) (wskazującą, ile razy termin wystąpił w dokumencie) lub terminem wartość odwrotnej częstotliwości dokumentu (TF-IDF) (wskazująca, jak ważny jest termin dla tekstu, biorąc pod uwagę jego korpus). Istnieją bardziej złożone mechanizmy ważenia, które koncentrują się na konkretnych problemach, ale są to najpowszechniejsze i na nich się skupimy. Biorąc pod uwagę to, o czym wspomnieliśmy wcześniej, tekst okazuje się być wektorem cech, a każdy wektor cech odpowiada punktowi w przestrzeni wektorowej. Model tej przestrzeni wektorowej jest taki, że istnieje oś dla każdego terminu w słowniku, a więc przestrzeń wektorowa jest n-wymiarowa, gdzie n jest rozmiarem słownictwa we wszystkich analizowanych danych (może to być ogromne) . Czasami warto pomyśleć o tych pojęciach w sposób geometryczny. Model worka słów i model przestrzeni wektorowej odnoszą się do różnych aspektów charakteryzowania tekstu i uzupełniają się wzajemnie. Poniższa ilustracja wyjaśnia model przestrzeni wektorowej:
Istotną słabością modelu bag-of-words jest to, że ignoruje on kontekst semantyczny terminów. Istnieją bardziej złożone modele, które próbują naprawić te niedociągnięcia. Jednym z nich jest parsowanie semantyczne, które polega na odwzorowywaniu zdania w języku naturalnym na formalną reprezentację jego znaczenia. Wykorzystuje głównie kombinacje programowania indukcyjnego i uczenia się statystycznego. Tego typu techniki stają się bardziej przydatne w przypadku złożonych tekstów. Chociaż nie będziemy ich dalej omawiać w tej książce, są one potężnym narzędziem i bardzo interesującym obszarem badań. Na przykład, jeśli spróbujesz pomyśleć o reprezentacji poniższego cytatu za pomocą modelu worka słów i semantycznego modelu parsowania, możesz intuicyjnie pomyśleć, że pierwszy z nich może dać nonsensowne wyniki, podczas gdy drugi może dostarczyć co najmniej trochę zrozumienia i miałbyś rację.
„Pułapka na ryby istnieje dzięki rybom. Gdy już zdobędziesz rybę, możesz zapomnieć o pułapce. Pułapka na królika istnieje z powodu królika. Kiedy już zdobędziesz królika, możesz zapomnieć o sidła. Słowa istnieją dzięki znaczenie. Kiedy już zrozumiesz znaczenie, możesz zapomnieć o słowach. Gdzie mogę znaleźć mężczyznę, który zapomniał słów, abym mógł z nim porozmawiać? ”
– Pisma Chuang Tzu, IV wiek p.n.e.