“Wspomóż rozwój naszego Bloga. Kliknij w Reklamę. Nic nie tracisz a zyskujesz naszą wdzięczność … oraz lepsze, ciekawsze TEKSTY. Dziękujemy”
Jak zwykle zaczynamy rozwijać naszą funkcję wykresu. Jako parametry otrzymujemy data oraz zmienne osi x (x) i osi y (y), a w tym przypadku przewidujemy cztery przypadki, które odpowiadają kombinacjom obejmującym lub nie zmiennych color i shape dla wykresu. Wykonujemy standardowe sprawdzenie i tworzymy odpowiednią bazę wykresów. Oto inna część, którą nazywamy funkcją ggMrginal() pakietu ggExtra z grafem obiektu, który chcemy (w tym przypadku wykres bazowy plus warstwa punktów) i określ typ wykresu, który ma być używany dla rozkładów krańcowych. Możesz wybrać spośród density, histogram i boxplot. Wybieramy histogram:
graph_marginal_distributions <- function(data, x, y, color = NULL, shape = NULL_ {
if (is.null(color)) {
if (is.null(shape)) {
graph <- ggplot(data, aes_string(x,y))
} else {
graph <- ggplot(data, aes_string(x,y), shape = shape)
}
} else {
if (is.null(shape)) {
graph <- ggplot(data, aes_string(x,y), color = color))
} else {
graph <- ggplot(data, aes_string(x,y), color = color ,shape = shape))
}
}
return (ggMarginal(graph + geom_point(), type = „histogram”))
}
Teraz możemy łatwo tworzyć wykresy punktowe z marginalnymi rozkładami po bokach. Na pierwszym wykresie (po lewej) pokazujemy zależność między PRICE, COST, PROTEIN_SOURCE i CONTINENT.
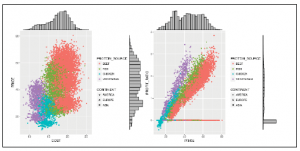
Zauważ, że istnieją bardzo rozróżnialne grupy. Na drugim wykresie (po prawej) pokazujemy zależność między PRICE, POFIT_RATIO PROTEI_SOURCE i CONTINENT. Zauważ, że znajdujemy tę samą relację, którą znaleźliśmy na naszych interaktywnych wykresach punktowych 3D, im wyższa wartość PRICE, tym wyższa wartość PROFIT_RATIO. Jednak są tutaj dwa interesujące ustalenia. Czy możesz powiedzieć, czym one są?
graph_marginal_distributions (sales, „COST”, „PRICE”, „PROTEIN_SOURCE”< „CONTINENT”)
Jeśli użyjesz funkcji graph_marginal_distributions() do sporządzenia wykresu kombinacji COST, PRIE, STATUS i PAID, nie powinien pojawić się żaden wzorzec, ponieważ te dystrybucje zostały losowo zasymulowane, aby uzyskać normalny rozkład oraz nie zastosowano do nich żadnego procesu wypaczania.