“Wspomóż rozwój naszego Bloga. Kliknij w Reklamę. Nic nie tracisz a zyskujesz naszą wdzięczność … oraz lepsze, ciekawsze TEKSTY. Dziękujemy”
Tworzenie wykresów słupkowych jest przydatne przy przedstawianiu wyników osobom, które nie są zaznajomione ze statystykami, ale fakt, że wykresy słupkowe agregują informacje (tak jak to zrobiliśmy na wykresach słupkowych dla najlepszych wykonawców) oznacza, że w rzeczywistości tracimy informacje z powodu zmniejszenie. Jeśli pracujesz z ludźmi, którzy rozumieją, czym są kwartyle, wykresy pudełkowe mogą być przydatną wizualizacją. Są łatwym sposobem na wyświetlenie poszczególnych rozkładów dla różnych poziomów zmiennej. Każde pole reprezentuje pierwszy kwartyl na dole, trzeci kwartyl na górze oraz medianę na linii pośrodku. Linie, które rozciągają się w pionie, sięgają do dowolnej obserwacji w granicach 1,5 * IQR, gdzie rozstęp międzykwartylowy (IQR) to odległość między pierwszym a trzecim kwartylem. Każda obserwacja powyżej 1,5 * IQR jest traktowana jako wartość odstająca i jest pokazywana indywidualnie. Naszym celem jest pokazanie wykresu słupkowego, który stworzyliśmy dla najlepszych wykonawców według PROFIT, ale w sposób zdezagregowany. Podczas korzystania z wykresów słupkowych trudność wynika z agregacji danych poprawnie, ale ponieważ nie musimy agregować danych do wykresów pudełkowych, ich tworzenie jest bardzo proste.
Nasza funkcja graph_top_boxplots() przyjmuje jako parametry wartość data, zmienne dla osi x i y, liczbę najlepszych elementów do pokazania jako n i opcjonalnie kolory linii i wypełnienia, odpowiednio jako c i f. Jeśli nie określono kolorów, używany jest wybór błękitów. Specyfikację kolorów należy podać w notacji HEX lub z nazwami kolorów R. Po prostu filtrujemy dane naszą funkcją filte_n_top i używamy warstwy boxplot() do tworzenia wykresów pudełkowych z odpowiednimi kolorami. Tytuł określamy również jako połączenie parametrów otrzymanych przez funkcję:
graph_top_n_boxplots <- function(data , x, y ,n, f = „#2196F3” c = „#0D47A1”){
data <- filter_n_top(sales, n, x)
return (
ggplot (data, aess_string(x,y)) + geom__boxplot(fill = f ,color = c) + ggtitle (paste (y, „by” , x, „(Top” , n, „)”)
)
}
Funkcja flter_n_top() otrzymuje jako parametry wartość data, liczbę najlepszych wykonawców, którą chcemy zachować jako n, oraz identyfikator wykonawców jako by. Najpierw używamy funkcji aggregate() do agregowania zmiennej PROFIT według wybranego identyfikatora (który jest wysyłany jako lista, zgodnie z wymaganiami funkcji) i wykonujemy agregacja z operatorem sum w celu uzyskania sumy PROFIT na klienta. Gdybyśmy użyli operatora mean, zobaczylibyśmy wykres średniej PROFIT na klienta. Następnie porządkujemy wyniki, które są zawarte w drugiej kolumnie obiektu aggr w kolejności malejącej i bierzemy n górne wartości z pierwszej kolumny, która zawiera identyfikatory ( wartości CLIENT_ID w poniższym przykładzie). Na koniec przechowujemy w danych tylko te obserwacje, które odpowiadają najwyższym identyfikatorom, jakie mamy w obiekcie top.
filter_n_top <- funtion(data, n by) {
aggr <- aggregate(data$PROFIT , list(data[, by]), sum)
top <- aggr[order(-aggr[, 2]) [1:n] , 1]
data <- data[data [, by] %in% top, ]
return(data)
}
Teraz możemy łatwo powtórzyć wykres słupkowy, który utworzyliśmy w poprzedniej sekcji, używając wykresów pudełkowych.
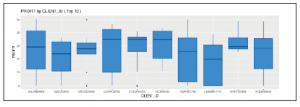
Jak widać, mamy więcej informacji pokazanych na wykresie, ale tracimy możliwość łatwego znalezienia całkowitej wartości PROFIT dla każdego CLIENT_ID. Wybór typu wykresu zależy od tego, jakie informacje próbujesz przekazać:
grpah_top_n_boxplots(sales, „CLIENT_ID”, „PROFIT”, 10)