“Wspomóż rozwój naszego Bloga. Kliknij w Reklamę. Nic nie tracisz a zyskujesz naszą wdzięczność … oraz lepsze, ciekawsze TEKSTY. Dziękujemy”
Wykresy słupkowe są jednym z najczęściej używanych narzędzi graficznych na świecie i ten rozdział nie jest wyjątkiem. W naszym ostatnim przykładzie wykresu słupkowego pokażemy, jak wykreślić wykresy najlepszych wyników dla danej zmiennej w kolejności malejącej. Naszym celem jest wykreślenie PROFIT lub Frequency na osi y oraz sparametryzowanej zmiennej dla osi x. Chcemy pokazać najbardziej efektywne n elementy dla zmiennej x w malejącej kolejności od lewej do prawej, jak pokazano na poniższym wykresie.
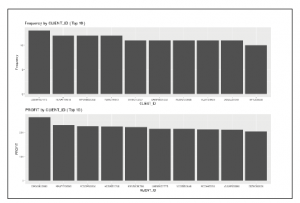
Aby to osiągnąć, otrzymujemy jako parametry dane (w tym przypadku sales), zmienną, która będzie używana dla osi x liczbę najlepszych wykonawców, których chcemy pokazać n i czy chcemy użyć PROFIT na osi y lub nie (w takim przypadku użyjemy Frequency), używając wartości boolowskiej by_profit. Pierwszą rzeczą, którą robimy, jest sprawdzenie parametru by_profit; jeśli to TRUE, to agregujemy dane PROFIT dla każdego CLIENT_ID z funkcją aggregate() przy użyciu operatora sum ( chcemy całkowitego zysku od klienta, a nie średniego zysku od klienta). Następnie porządkujemy wyniki funkcją order() Znak minus (-) tuż przed wartością profit_by_client$x oznacza, że chcemy porządku malejącego, a x następujący po profit_by_client jest spowodowane tym, że wynikiem funkcji aggregate() jest ramka danych z Group.1 i x kolumnami, które przechowują sumę CLIENT_ID i PROFIT, odpowiednio. Ponieważ chcemy uniknąć niepotrzebnego powielania kodu, kiedy zwracamy żądany wykres, musimy upewnić się, że oba przypadki w bloku if else używają tych samych nazw zmiennych, których użyjemy w funkcji ggplot(). Dlatego jawnie przypisujemy nazwy x i y_bar do ramki danych top_df. Jeśli zajrzałeś do wnętrza obiektu top_df podczas wykonywania, zobaczysz, że zawiera on zduplikowane dane z różnymi nazwami kolumn. Moglibyśmy się tym zająć, usuwając kolumny z nazwami, których nie chcemy, ale w tym momencie jest to niepotrzebne, ponieważ i tak jest to obiekt jednorazowy. Jednak w niektórych sytuacjach może to być problem z wydajnością, z którym musimy się uporać, ale nie w tym przypadku. W przypadku bloku else koncepcyjnie robimy to samo. Jednak technicznie realizujemy inaczej. W tym przypadku tworzymy tabelę, w której każdy wpis w tabeli jest unikalną wartością CLIENT_ID, a wartością każdego wpisu jest liczba razy CLIENT_ID pojawiająca się w danych (Frequency) i robimy to za pomocą funkcji table(). Następnie sortujemy te wyniki w porządku malejącym za pomocą funkcji sort() i bierzemy górę n wyników. Następnie wykorzystujemy te wyniki do utworzenia ramki danych top_df z odpowiednimi kolumnami. Zauważ, że potrzebujemy pomocniczej nazwy aux_name dla zmiennej x, ponieważ nie możemy utworzyć ramki danych przez określenie nazwy kolumny za pomocą zmiennej. Następnie kopiujemy dane z kolumny aux_name do rzeczywistej nazwy, której potrzebujemy (zawartej w zmiennej x). Na koniec tworzymy wykres i natychmiast zwracamy go bez pamięci pośredniej. W tym momencie szczegółowe informacje na temat tego, co robi każda linia w tej części kodu, powinny być dla Ciebie jasne, więc unikniemy ponownego wyjaśniania tego. Teraz możesz łatwo utworzyć n najlepszych wykresów za pomocą następującego kodu. Sugerujemy, abyś spróbował utworzyć podobne wykresy dla innych zmiennych kategorialnych (na przykład CONTINENT lub PROTEIN_SOURCE). Zwróć uwagę, że wartości CLIENT_ID w każdym przypadku są różne, co oznacza, że klienci, którzy kupują najwięcej w The Food Factory, niekoniecznie są klientami, którzy generują na tym największy zysk:
graph_top_n_bars(sales, „CLIENT_ID” , 10)
graph_top_n_bars(sales, „CLIENT_ID” , 10, TRUE)
Chcieliśmy zacząć od prostego i pokazać podstawowe koncepcje pracy z funkcjami wykresów, zanim skomplikujemy sprawy w kolejnych sekcjach