Zaczniemy od prostych wykresów i przejdziemy do zaawansowanych wykresów. Pierwszy wykres, który utworzymy, to wykres słupkowy. Narysujemy tabelę częstotliwości, która pokazuje, ile zamówień sprzedaży mamy dla każdego numeru QUANTITY w naszej sprzedaży. Aby to zrobić, używamy funkcji ggplot(), używając sales jako danych i ustawiając estetykę za pomocą funkcji aes() z QUANTITY w osi x (pierwszy argument). Po utworzeniu podstawy wykresu za pomocą funkcji ggplot() dodajemy warstwy dla różnych obiektów, które chcemy zobaczyć na wykresie (na przykład słupki, linie i punkty). W tym przypadku my dodaj słupki z funkcją geom_bar(). Zwróć uwagę, jak ta warstwa jest dodawana za pomocą znaku + (plus) do podstawy wykresu. Następnie dodajemy kolejną warstwę dla tytułu z ggtitle(). Na koniec dodajemy specyfikację osi x z funkcją scale_x_continuous(), która pozwoli nam zobaczyć liczbę dla każdego słupka na wykresie. Jeśli nie dodasz tej warstwy, wykres może nie pokazywać liczby dla każdego słupka, co może być nieco mylące. Sposób, w jaki to określamy, polega na wysyłaniu sekwencji liczb, które powinny być używane jako przerwy (tam, gdzie pokazane są dane tickowe). Ponieważ liczby w danych mogą się różnić seq() od minimalnej liczby w zmiennej QUANTITY do maksymalnejy. To automatycznie pokaże prawidłowe liczby, nawet jeśli zmienna QUANTITY ma bardzo różne zakresy. Może się wydawać, że to dużo kodu do zbudowania prostego wykresu. Jednak to właśnie ilość kodu pozwala nam dokładnie określić, co chcemy zobaczyć na wykresie, jak zobaczysz w poniższych przykładach. Należy również zauważyć, że tylko funkcje ggplot() (z odpowiadającą im funkcją aes()) i geom_bar() są wymagane do faktycznego utworzenia wykresu. Funkcje ggtitle() i scale_x_continuous() służą tylko do ulepszania wykresu:
graph <- ggplot(sales, aes(QUANTITY)) + geom_bar() + ggtitle(„QUANTITY Frequency”) + scale_x_continuous (
breaks = seq(min(sales[, „QUANTITY”]),
max(sales[, „QUANTITY”]))
)
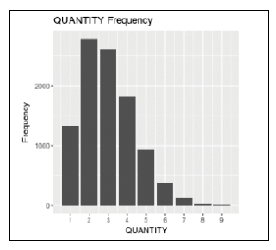
Poniższy wykres przedstawia częstotliwość QUANTITY dla poprzedniego kodu:
Ponieważ będziemy tworzyć wiele wykresów słupkowych, chcemy uniknąć konieczności kopiowania i wklejania kodu, który właśnie napisaliśmy, i nie tylko, ale także uczynienia go bardziej elastycznym. Aby to osiągnąć, uogólnimy nasz kod, parametryzując go i rozważając różne scenariusze, które powinniśmy pokryć. Na co więc możemy chcieć, żeby nasza niestandardowa funkcja graph_bar nam umożliwiała? Na początek możemy chcieć określić różne zmienne dla naszej osi x i osi y. Aby to zrobić, musimy zrozumieć, jak funkcja geom_bar() działa wewnętrznie. Jeśli spojrzysz wstecz na kod, nigdy nie określiliśmy zmiennej dla osi y i ggplot() automatycznie użyliśmy liczby razy QUANTITY liczby pojawiającej się w danych (częstotliwość ).
A jeśli chcemy użyć wartości PROFIT dla każdej sprzedaży jako zmiennej dla osi y? W takim przypadku musimy zdać sobie sprawę, że mamy ponad 2000 potencjalnie różnych wartości, jak PROFIT kiedy QUNTITY wynosi dwa lub trzy, a mniej w pozostałych przypadkach. Musimy w jakiś sposób zagregować te wartości PROFIT, zanim będziemy mogli użyć PROFIT na osi y. Do agregowania danych można użyć dowolnej funkcji, która może zredukować wartości PROFIT do jednej wartości dla wszystkich transakcji, dla każdej wartości QUATITY. Jednak najbardziej typowe wybory wykorzystują średnią lub sumę. Średnia pokazałaby wykres, na którym widzimy średnią PROFIT dla każdej wartości QUANTITY. Suma pokaże nam łączną wartość PROFIT dla każdej wartości QUANTITY. To samo dotyczyłoby, gdybyśmy chcieli użyć PROFIT_RATIO (lub dowolnej innej zmienna numeryczna) na osi y. Najbardziej intuicyjne opcje wykorzystują sumę dla PROFIT (całkowity zysk) i średnią dla PROFIT_RATIO (średni wskaźnik zysku), więc użyjemy tych. W przypadku osi x możemy mieć zmienne jakościowe, numeryczne lub daty. W tym konkretnym przypadku domyślne opcje osi x są odpowiednie dla zmiennych kategorialnych i dat, ale nadal chcemy widzieć wszystkie liczby w znacznikach podczas pracy ze zmiennymi numerycznymi. Oznacza to, że musimy zapewnić sprawdzenie typu zmiennej na osi x, a jeśli jest liczbowa, to musimy wykonać odpowiednią korektę (taką samą, jaką widzieliśmy w poprzednim kodzie).
To, co wyjaśniliśmy wcześniej, jest zaprogramowane w naszej funkcji graph_bars(). Otrzymuje jako parametry dane oraz zmienne osi x i osi y. Najpierw sprawdza, czy podaliśmy określoną zmienną osi y. Jeśli nie otrzymamy zmiennej osi y , tworzymy wykres słupkowy tak jak to zrobiliśmy wcześniej (używając częstotliwości zmienna osi x domyślnie) i tworzymy odpowiedni tytuł za pomocą funkcji paste(). Jeśli otrzymamy zmienną dla osi y (co oznacza, że jesteśmy w bloku else), to musimy dowiedzieć się, jaki typ agregacji musimy zrobić, i robimy to za pomocą naszej funkcji get_aggregation(), która zwraca sumę jako metodę agregacji, jeśli zostaniemy poproszeni o wykreślenie zmiennej PROFIT na osi y, i zwraca średnią w każdym innym przypadku. Następnie używamy tej nazwy funkcji jako wartości parametru fun.y (odczytywanego jako funkcja dla y) i określamy, że jesteśmy praca z funkcją podsumowującą (jeśli nie potrzebujesz agregacji dla zmiennej, powinieneś wysłać parametr stat = ‘identity’ do funkcji geom_bar() i unikaj wysyłania go do parametru fun.y). Następnie w razie potrzeby określamy tytuł wykresu. Po bloku if else sprawdzamy, czy typ zmiennej dla osi x jest numeryczny, a jeśli tak, to stosujemy transformację nazw przedziałów:
graph_bars <- funtio(data, x,y = NULL) {
if (is.null(y)) {
graph <- ggplot(data, aes_string(x)) + geom_bar() + ggtitle(paste(x, „Frequeny”)) +
ylab(„Frequency”)
}else {
aggregation <- get_aggregation(y)
praph <- ggplot(data, aes_string(x,y) ) + geom_bar(fun.y = aggregation, stat = „summary”) + ggtitle(paste(y , „by” , x))
}
if (class(data[, x]) == „numeric”) {
praph <- praph + scale__continous (
breaks = seq(min(data[, ]). ma(datat[, ])
}
return (graph)
}
Podczas pracy z tą funkcją dotyczącą przypadków specjalnych zalecamy umieszczenie wielkości liter w części if sprawdzainia, aby upewnić się, że wychwytujesz tylko przypadki specjalne, których szukamy, a w przeciwnym razie zwracasz wielkość ogólną. Jeśli zrobisz to na odwrót (najpierw sprawdzając przypadki ogólne), z pewnością napotkasz kilka trudnych błędów:
get_aggregation <- function(y) {
if (y == „PROFIT”) {
return(„sum”)
}
return(„mean”)
}
Teraz możemy stworzyć o wiele więcej wykresów słupkowych za pomocą naszej niestandardowej funkcji graph_bars():
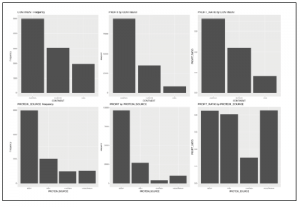
graph_bars()(sales, „CONTINENT”)
graph_bars()(sales, „CONTINENT”, „PROFIT”)
graph_bars()(sales, „CONTINENT”, „PROFIT_RATIO”)
graph_bars()(sales, „PROTEIN_SOURCE”)
graph_bars()(sales, „PROTEIN_SOURCE”, „PROFIT”)
graph_bars()(sales, „PROTEIN_SOURCE”, „PROFIT_RATIO”)
Wszystkie poniższe wykresy są pokazane razem w celu łatwiejszej wizualizacji i zachowania miejsca, ale można je uzyskać jeden po drugim, wykonując kod samodzielnie.