Jaką zmienną mamy jeszcze w ramce danych sprzedaży? Cóż, aby sformułować to w taki sposób, aby problem był bardzo oczywisty, nadal mamy zmienne sprzedaży i zmienne klienta. Więc jaki może być problem? Cóż, za każdym razem, gdy klient dokonuje nowego zakupu, zapisujemy jej BIRTH_DATE, CLIENT_SINCE, GENDER i STARS informacje ponownie. Co się stanie, jeśli częsty klient dokona 100 różnych zakupów w The Food Factory? Cóż, jej informacje zostaną powtórzone 100 razy! Musimy to naprawić. Jak możemy to zrobić? Robimy to samo, co wcześniej, oddzielamy różne rzeczy. Zgadza się. Tworzymy osobną ramkę danych dla danych klienta i już wiemy, jak powiązać klientów ze sprzedażą, ponieważ używaliśmy tej samej techniki w poprzednim problemie, tworzymy identyfikatory w obu ramkach danych. Jest to relacja wiele do jednego (z punktu widzenia danych sprzedażowych w stosunku do danych klientów). Jestem pewien, że możesz dowiedzieć się, które zmienne należą do których ramek danych.
Eliminując powtarzające się dane, eliminujemy również możliwość przypadkowej zmiany niektórych z tych powtarzających się wartości, a następnie nie wiemy, które z nich są prawidłowe. Podsumowując, dokonaliśmy rozbicia ogromnej tabeli początkowej, która zawierała wszystkie informacje w jednym miejscu, na trzy różne tabele, które są połączone identyfikatorami, w taki sposób, że reprezentujemy różne rzeczy w każdej tabeli (sprzedaż, klienci, i wiadomości klientów), eliminując jednocześnie dużo marnowanej przestrzeni i powtarzających się wartości. Aby uzyskać więcej intuicji na temat organizacji po tych dostosowaniach, możemy przyjrzeć się poniższemu obrazowi, który pokazuje, jakie atrybuty danych należą do poszczególnych encji i jak są ze sobą powiązane:
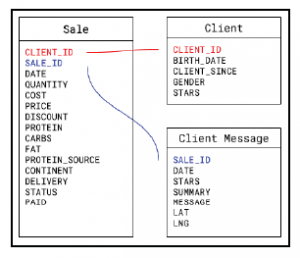
Techniki te, wraz z wieloma innymi, nazywane są normalizacją bazy danych, co może być przydatne w niektórych scenariuszach. Czasami jednak nie chcemy, aby nasze dane były w pełni znormalizowane z powodu problemów z wydajnością, ale są to zaawansowane przypadki, których nie omówimy tutaj.