Sprawdzimy normalność za pomocą dwóch różnych technik, aby zilustrować użycie techniki znanej jako wzorzec strategii, która jest częścią zestawu wzorców z programowania obiektowego. Na razie możesz myśleć o schemacie strategii jako o technice, która ponownie wykorzysta kod, który w przeciwnym razie zostałby zduplikowany i po prostu zmienia sposób wykonywania rzeczy zwanych strategią. W poniższym kodzie widać, że tworzymy funkcję o nazwie save_png(), która zawiera kod, który zostałby zduplikowany (zapisywanie plików PNG) i nie musi być. Będziemy mieć dwie strategie, w postaci funkcji, sprawdzania normalności danych – histogramy i wykresy kwantyl-kwantyl. Zostaną one przesłane za pomocą argumentu o dogodnej nazwie function_to_create_images. Jak widać, ten kod otrzymuje pewne dane, zmienną, która zostanie użyta dla wykresu, nazwę pliku obrazu oraz funkcję, która zostanie użyta do utworzenia wykresów. Ten ostatni parametr, funkcja, nie powinien być nieznany czytelnikowi, że możemy wysyłać funkcje jako argumenty i używać ich tak, jak robimy w tym kodzie wywołując je poprzez ich nową nazwę wewnątrz funkcji, function_to_create_images() w tym przypadku:
save_png <- function(data,variable, save_to, function_to_create_image){
if (not_empty(save_to)) png(save_to)
function_to_create_image(data, variable)
if (not_empty(save_to)) dev.off()
}
Teraz pokażemy kod, który będzie używał tej funkcji save_png() i hermetyzujemy wiedzę o funkcji używanej w każdym przypadku. W przypadku histogramów funkcja histohram() pokazana w poniższym kodzie po prostu opakowuje funkcję hist() używaną do tworzenia wykresu ze wspólnym interfejsem, który będzie również używany przez inne strategie (w tym przypadku funkcja quantile_quantile() przedstawiona w poniższym kodzie). Ten wspólny interfejs pozwala nam używać tych strategii jako wtyczek, które można łatwo zastąpić, tak jak robimy to w odpowiednich funkcjach variable_histogram i variable_qqplot() (obie wykonują to samo wywołanie, ale w każdym przypadku używają innej strategii). Jak widać, inne szczegóły, które nie są częścią wspólnego interfejsu (na przykład main i xlab), są obsługiwane w kodzie każdej strategii. Moglibyśmy dodać je jako opcjonalne argumenty, gdybyśmy chcieli, ale nie jest to konieczne w tym przykładzie:
variable_historgram <- function(data, variable, save_to = „”){
save_png(data, variable, save_to, histgram_
}
histogram <- function(data, variable_ {
hist(data[, variable], main = „Histogram”, xlab = Proportion”]
)
variable_qqplot <- fution(data, variable, save_to = „”) {
save_png(data, variable, save+to, quantile_quatile)
}
quantile_quantile <- function(data, variable) {
qqnorm)data[, varaible[, main= „Normal QQ-Plot for Proprotion”)
qqline(data[, variable])
}
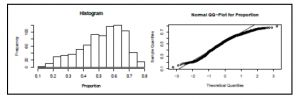
Poniżej przedstawiono wykres do sprawdzania normalności proporcji:
quantile_quantile <- function(data, variable) {
qqnorm(data[, variable] , main = „Normal QQ- Plot for Proprotion”)
qqline(data[, variable])
}
Gdybyśmy chcieli udostępnić kod używany do tworzenia obrazów PNG z trzecią (lub więcej) strategiami, możemy po prostu dodać opakowanie strategii dla każdego nowego przypadku, nie martwiąc się o powielanie kodu, który tworzy obrazy PNG. Może się wydawać, że to nic wielkiego, ale wyobraź sobie, że kod użyty do utworzenia plików PNG był złożony i nagle znalazłeś błąd. Czego potrzebujesz, aby naprawić ten błąd? Cóż, musiałbyś udać się w każde miejsce, w którym zduplikowałeś kod i tam go naprawić. Wydaje się mało wydajne. Co się stanie, jeśli nie chcesz już zapisywać plików PNG, a zamiast tego chcesz zapisywać pliki JPG? Cóż, znowu musiałbyś iść wszędzie, gdzie zduplikowałeś swój kod i zmienić go.
Znowu niezbyt wydajne. Jak widać, ten sposób programowania wymaga niewielkiej inwestycji z góry (stworzenie wspólnych interfejsów i dostarczenie opakowań), ale korzyści z tego zwrócą się w ramach zaoszczędzonego czasu, trzeba zmienić kod, choćby raz , a także bardziej zrozumiały i prostszy kod. Jest to forma zarządzania zależnościami i jest to coś, czego powinieneś się nauczyć, aby stać się bardziej wydajnym programistą. Być może zauważyłeś, że w poprzednim kodzie mogliśmy uniknąć jednego wywołania funkcji, wywołując bezpośrednio funkcję save_png(). Jednak zrobienie tego wymagałoby od użytkownika znajomości dwóch rzeczy: funkcji save_png() do zapisywania obrazu i funkcji quantile_quantile() lub histogram() które tworzą wykresy, w zależności od tego, co próbowała wykreślić. To dodatkowe obciążenie dla użytkownika, choć pozornie nie jest problematyczne, może sprawić, że sytuacja będzie dla niej bardzo zagmatwana, ponieważ niewielu użytkowników jest przyzwyczajonych do wysyłania funkcji jako argumentów i musieliby znać dwie sygnatury funkcji zamiast jednej. Zapewnienie opakowania, którego podpis jest łatwy w użyciu, tak jak robimy to z variable_histogram() i variable_qqplot() ułatwia to użytkownikowi i pozwala nam rozszerzyć sposób, w jaki chcemy wyświetlać wykresy, na wypadek gdybyśmy chcieli to później zmienić bez zmuszania użytkownika do uczenia się nowej sygnatury funkcji. Aby faktycznie utworzyć wykresy, których szukamy, używamy następującego kodu:
variable_histogram(data = data, variable = „Proportion”)
variable_qqplot(data = data, variable = „Prorporti
Jak widać, histogram pokazuje przybliżony rozkład normalny lekko pochylony w prawo, ale możemy go łatwo zaakceptować jako normalny. Odpowiedni wykres kwantylowo-kwantylowy przedstawia te same informacje w nieco inny sposób. Linia, którą pokazuje, odpowiada kwantylom rozkładu normalnego, a kropki pokazują rzeczywisty rozkład danych. Im bliżej linii znajdują się te kropki, tym bliżej rozkładu zmiennej jest rozkład normalny. Jak widać, w przeważającej części Proportion ma rozkład normalny, a na skrajach widać niewielkie odchylenie, które prawdopodobnie wynika z tego, że nasza zmienna Proportion w rzeczywistości zmienna ma sztywne limity na 0 i 1. Jednakże możemy również zaakceptować ją jako rozkład normalny i możemy bezpiecznie przejść do następnego założenia.