Aby uzyskać podsumowanie danych, możemy wykonać summary(data) i zobaczyć odpowiednie podsumowania dla każdego typu zmiennej. Podsumowanie jest dostosowane do typu danych każdej kolumny. Jak widać, zmienne liczbowe, takie jak ID i NVotes, uzyskują podsumowanie kwantylowe, podczas gdy zmienne czynnikowe (kategorialne) uzyskują liczbę dla każdej kategorii, na przykład AreaType i RegionName. Jeśli istnieje wiele kategorii, podsumowanie pokaże kategorie, które pojawiają się najczęściej, a resztę zgrupuje w (Other) grupę, jak widać na dole RegionName.
summary(date)
#> ID RegionName NVotes Opuść
#> Min. : 1 Długość: 1070 min. : 1039 min. : 287
#> 1. kw .: 268 Klasa: znak 1. kw .: 4252 1. kw .: 1698
#> Mediana: 536 Tryb: znak Mediana: 5746 Mediana: 2874
#> Średnia: 536 Średnia: 5703 Średnia: 2971
#> 3
#> Max. : 1070 Maks. : 15148 Maks. : 8316
(Obcięte wyjście)
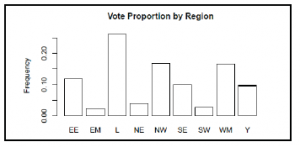
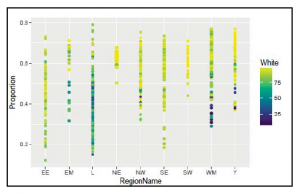
Stąd widać, że Londyn jest regionem, do którego należy więcej okręgów, a następnie północno-zachodnia i zachodnia część Midlands. Widzimy również, że podopieczny z najmniejszą liczbą głosów we wszystkich danych miał tylko 1039 głosów, ten z największą liczbą głosów – 15 148, a średnia liczba głosów na podopiecznego wyniosła 5703. W dalszej części rozdziału przyjrzymy się dokładniej tego rodzaju analizom. Na razie skupimy się na tym, aby podsumowanie danych było przydatne do dalszej analizy. Jak być może zauważyłeś, nie możemy używać wyników summary() do wykonywania obliczeń. Możemy spróbować zapisać podsumowanie w zmiennej, poznać typ zmiennej i przejść przez nią w odpowiedni sposób. Jeśli jednak to zrobimy, okaże się, że są to dane tekstowe, co oznacza, że nie możemy ich użyć do obliczeń, tak jak jest:
summary <- summary(data)
class(summary)
#> [1] “tabela”
summary[1]
#> [1] “Min.: 1”
class (summary[1])
#> [1] “znak”
Z pewnością musi istnieć sposób na umieszczenie danych summary w ramce danych w celu dalszej analizy. To jest R, więc możesz się założyć, że jest! Pierwszą rzeczą, na którą powinniśmy zwrócić uwagę, jest to, że nie możemy bezpośrednio przetłumaczyć wyjścia funkcji summary() na ramkę danych ze względu na zmienne nieliczbowe. Te zmienne nienumeryczne zawierają inną strukturę podsumowującą, która nie składa się z wartości minimalnych, pierwszego kwartylu, mediany, średniej, trzeciego kwartylu i maksymalnych. Oznacza to, że najpierw musimy podzielić dane, aby uzyskać tylko dane liczbowe zmienne. W końcu ramka danych jest prostokątną strukturą z dobrze zdefiniowanymi wierszami i kolumnami. Gdybyśmy próbowali mieszać typy (włączając podsumowania liczbowe i nieliczbowe) w ramce danych, byłoby to trudne. Aby sprawdzić, czy kolumna jest liczbowa, czy nie, możemy użyć funkcji is.numeric(). Na przykład widzimy, że kolumna Proportion jest numeryczna, a RegionName nie jest:
is.numeric(data$Proportion)
#> [1] TRUE
is.numeric(data$RegioName)
#> [1] FALSE
Następnie możemy zastosować is.numeric() do każdej kolumny za pomocą funkcji sapply(). To da nam wektor logiczny (boolowski) z wartością TRUE lub FALSE dla każdej kolumny, wskazującą, czy jest to liczba. Następnie możemy użyć tego wektora logicznego do podzbioru naszych danych i pobierz tylko kolumny liczbowe z datat[, numerical_varaibles]. Jak widzisz, w obiekcie data_numerical nie ma kolumn nienumerycznych:
numerical_variables <- sapply(data, is.numeric)
numerical_variables
#> ID RegionName NVotes Leave Residents
#> TRUE FALSE TRRUE TRUE TRUE
#> Households MeanAge AdultMeanAge Aget_0to4 Age_5to7
#> TRUE TRUE TRUE TRUE TRUE
data_numerical <- datat[, numerical_variables]
colnames(data_numerical)
#> [1] “ID” “Nvotes” “Leave” “Residents”
#> [5] “Households” “MeanAge” “AdultMeanAge” “Age_0to4”
#> [9] “Age_5to7” “Age_8to9” “Age_10to14” “Age_15”
#> [13] “Age_16to17 “Age_18to19” “Age_20to24” “Age_25to29”
(Obcięte dane wyjściowe)
Ponieważ nie ma sensu uzyskiwanie wartości summary dla zmiennej ID, możemy usunąć ją z wektora logicznego, traktując ją skutecznie jako zmienną nienumeryczną. Jeśli to zrobimy, musimy pamiętać o odtworzeniu obiektu data_numeric, aby upewnić się, że nie zawiera on również zmiennej ID:
numerical_variable[[„ID”]] <- FALSE
data_numerical <- data [, numerical_variables]
Aby utworzyć podsumowanie zmiennych numerycznych, najpierw zastosujemy funkcję summary(), którą utworzyliśmy wcześniej, do każdej kolumny liczbowej za pomocą funkcji lapply(). Funkcja lapply() zwraca nazwaną listę, gdzie każdy element listy ma odpowiednią nazwę kolumny: lapply(data[,numerical_variables], summary)
#> $NVotes
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1039 4252 5746 5703 7020 15148
#>
#> $Leave
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 287 1698 2874 2971 3936 8316
#>
#> $Residents
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1932 8288 11876 11646 14144 34098
#>#>
(Obcięte wyjście)
Teraz musimy umieścić każdego członka tej listy razem w ramce danych. W tym celu użyjemy funkcji cbind() i do.call(). do.call() będą obowiązywać kolejno cbind() do każdego członka listy wygenerowanej przez lapply() i zwróć je wszystkie razem.
numerical_summary <- do.call(cbid, lapply(data_numerical, summary))
#> Warning in (function (…, deparse.level = 1) : number of rows of result
is
#> not a multiple of vector length (arg 1)
numerical_summary
#> NVotes Leave Residents Households MeanAge AdultMeanAge Age_0to4
#> Min. 1039 287 1932 779 27.80 29.20 2.200
#> 1st Qu. 4252 1698 8288 3466 35.60 44.10 5.400
#> Median 5746 2874 11876 4938 38.70 47.40 6.300
#> Mean 5703 2971 11646 4767 38.45 46.85 6.481
#> 3rd Qu. 7020 3936 14144 5832 41.40 49.90 7.50058
#> Max. 15148 8316 34098 15726 51.60 58.10 12.300
#> NA’s 1039 267 1932 779 27.80 29.20 2.200
Otrzymaliśmy nasze wyniki, ale nie tak szybko! Dostaliśmy ostrzeżenie i wygląda to podejrzanie. Co oznacza wiadomość number of rows of result is not a multiple of vector legth oznacza wiadomość? Aha! Jeśli przyjrzymy się dokładniej liście, którą otrzymaliśmy wcześniej z naszego lapply() widzimy, że w przypadku Leave (i Proportion) otrzymujemy dodatkową kolumnę dla NAs, której nie otrzymujemy dla żadnej innej kolumny. Oznacza to, że kiedy spróbujemy użyć cbind() na tych kolumnach, dodatkowa kolumna NAs utworzy dodatkową przestrzeń, którą należy wypełnić. Jak widzieliśmy, R radzi sobie z tym, powtarzając wektory po kolei, aż wszystkie przestrzenie zostaną wypełnione. W naszym przypadku oznacza to, że pierwszy element, odpowiadający wartości minimalnej, zostanie powtórzony dla przestrzeni NA dla każdej kolumny, która nie ma spacji NA. Możesz to sprawdzić, porównując liczby w kolumnach Min i NAs dla zmiennych innych niż Leave lub Proportion (dla tych dwóch wartości powinny być faktycznie różne) . Aby to naprawić, możemy po prostu usunąć wiersz dodatkowej wartości NA z wynikowej ramki danych, ale to nie dotyczy źródła ostrzeżenia, a jedynie objaw. Aby poradzić sobie ze źródłem, musimy mieć taką samą liczbę kolumn dla każdej zmiennej, zanim zastosujemy cbind(). Ponieważ już wiemy, że mamy 267 braków danych dla zmiennej Leave, które wtedy wpływają na zmienną Proportion, możemy to łatwo naprawić, ignorując te informacje. Aby to zrobić, po prostu używamy pełnych przypadków, co oznacza, że przechowujemy obserwacje, które nie mają żadnych wartości NA w żadnej ze swoich zmiennych; lub inaczej mówiąc, pomijamy każdą obserwację, która zawiera co najmniej jeden . Gdy to zrobimy, odzyskamy wyniki i nie otrzymujemy żadnych ostrzeżeń:
data <- data[complete.cases(data), ]
data_numerical <- data[, numerical_variables]
numerical_summary <- do.call(cbind, lapply(data_numerical, summary))
numerical_summry
#> NVotes Leave Residents Households MeanAge AdultMeanAge Age_0to4
#> Min. 1039 287 1932 779 28.40 30.50 2.200
#> 1st Qu. 4242 1698 8405 3486 35.70 44.10 5.400
#> Median 5739 2874 11911 4935 38.60 47.40 6.300
#> Mean 5725 2971 11739 4793 38.43 46.83 6.479
#> 3rd Qu. 7030 3936 14200 5850 41.40 49.90 7.500
#> Max. 15148 8316 34098 15726 47.30 56.10 12.300
(Obcięte wyjście)
Jeśli chcemy otrzymać wartości podsumowania jako kolumny, a zmienne jako wiersze, możemy użyć funkcji rbind() zamiast cbind(). Struktura, której faktycznie używamy, będzie zależeć od tego, co chcemy z nią zrobić. Możemy jednak łatwo przełączać się między nimi później, jeśli zajdzie potrzeba:
do.call(rbind, lapply(data_numerical, summary))
#> Min. 1st Qu. Median Mean 3rd Qu.
Max.
#> NVotes 1039.0000 4241.5000 5.739e+03 5.725e+03 7.030e+03
1.515e+04
#> Leave 287.0000 1697.5000 2.874e+03 2.971e+03 3.936e+03
8.316e+03
#> Residents 1932.0000 8405.0000 1.191e+04 1.174e+04 1.420e+04
3.410e+04
#> Households 779.0000 3486.0000 4.935e+03 4.793e+03 5.850e+03
1.573e+04
#> MeanAge 28.4000 35.7000 3.860e+01 3.843e+01 4.140e+01
4.730e+01
Teraz, gdy mamy ten obiekt numerical_summary możemy go użyć do wykonania obliczeń, takich jak znalezienie zakresu między totemami z najmniejszą i największą liczbą głosów za opuszczenia szkoły (0,6681), co może być przydatne do interpretacji dużej różnicy między typami oddziałów, jakie możemy znaleźć w Wielkiej Brytanii. Jeśli chcemy wiedzieć, które totemy są używane, aby dostać się do tego wyniku, możemy wyszukać totemy z najmniejszą i największą liczbą głosów:
numericla_summary[„Max.”, „Proportion”] – numerical_summary[„Min.”, „Proportion”
desired_variables <- c(
„ID”,
„NoQuals”,
„Proportion”,
„AdultMeanAge”,
„L4Quals_plus”,
„RegionName”
)
>data[which.max(data$Proportion), desired_variables]
#> ID NoQuals Proportion AdultMeanAge L4Quals_plus RegionName
#> 754 754 35.8 0.7897 48.7 13.7 L
data[which.min(data$Proportion), desired_variables]
#> ID NoQuals Proportion AdultMeanAge L4Quals_plus RegionName
#> 732 732 2.8 0.1216 31.2 44.3 EE
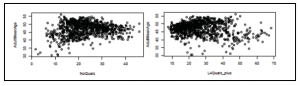
Jak widać, ta analiza już pokazuje interesujące wyniki. Okręg w Wielkiej Brytanii, który głosował za opuszczeniem UE najbardziej, charakteryzuje się osobami starszymi (MeanAge) z niskim poziomem wykształcenia (oQuals, L4Quals-plus). Z drugiej strony oddział Wielkiej Brytanii, który głosował za pozostaniem w UE najbardziej, charakteryzuje się młodymi ludźmi z dużo wyższym wykształceniem. Oczywiście nie jest to pełny obraz, ale jest to wskazówka dotycząca kierunku, w którym musimy spojrzeć, aby lepiej zrozumieć, co się dzieje. Na razie stwierdziliśmy, że wykształcenie i wiek wydają się być istotnymi zmiennymi do analizy