Istnieje wiele sposobów, w jakie moglibyśmy pomyśleć o zbudowaniu własnego silnika rekomendacji znajomych na Twitterze. Twitter ma wiele wymiarów danych, więc możemy pomyśleć o polecaniu ludziom na podstawie tego, o czym „tweetują”. Byłoby to ćwiczenie w eksploracji tekstu i wymagałoby dopasowywania ludzi na podstawie jakiegoś wspólnego zestawu słów lub tematów w ramach ich tweetów. Podobnie wiele tweetów zawiera dane geolokalizacyjne, dlatego możemy polecić użytkowników, którzy są aktywni i znajdują się w pobliżu. Lub możemy połączyć te dwa podejścia, przechodząc przez punkt przecięcia 100 najlepszych rekomendacji z każdego. To jednak część o sieciach, więc skupimy się na budowaniu silnika opartego tylko na relacjach międzyludzkich. Dobrym miejscem na początek jest prosta teoria o ewolucji użytecznych relacji w dużej sieci społecznościowej. W swojej przełomowej pracy z 1958 r. Fritz Heider przedstawił ideę „teorii równowagi społecznej”.
przyjaciel mojego przyjaciela jest moim przyjacielem
wróg mojego przyjaciela jest moim wrogiem
przyjaciel mojego wroga jest moim wrogiem
wróg mojego wroga jest mój przyjaciel
—Fritz Heider, Psychologia relacji interpersonalnych
Pomysł jest dość prosty i można go opisać w kategoriach zamykania i dzielenia trójkątów na wykresie społecznościowym. Teoria Heidera wymaga tylko obecności podpisanych relacji, tj. Mojego przyjaciela (pozytywny) lub mojego wroga (negatywny). Wiedząc, że nie mamy tych informacji, w jaki sposób możemy wykorzystać jego teorię, aby zbudować silnik rekomendacji dla relacji na Twitterze? Po pierwsze, skuteczna rekomendacja silnik Twittera może zadziałać, aby zamknąć otwarte trójkąty, to znaczy znaleźć przyjaciół moich przyjaciół i uczynić ich przyjaciółmi. Chociaż nie mamy w pełni podpisanych relacji, znamy wszystkie pozytywne relacje, jeśli założymy, że wrogowie nie podążają za sobą na Twitterze. Kiedy wykonaliśmy nasze początkowe pobieranie danych, przeprowadziliśmy dwuetapowe wyszukiwanie śnieżki. Te dane zawierają naszych przyjaciół i przyjaciół naszych przyjaciół. Możemy więc wykorzystać te dane do zidentyfikowania trójkątów, które wymagają zamknięcia. Pytanie brzmi zatem: który z wielu potencjalnych trójkątów powinienem polecić jako pierwszy? Ponownie możemy przyjrzeć się teorii równowagi społecznej. Szukając tych węzłów w naszym początkowym wyszukiwaniu śnieżkami, których nie śledzi nasienie, ale które śledzi wielu ich przyjaciół, możemy mieć dobrych kandydatów na rekomendacje. To rozszerza teorię Heidera na następujące: przyjaciel wielu moich przyjaciół może być dla mnie dobrym przyjacielem. Zasadniczo chcemy zamknąć najbardziej oczywisty trójkąt w zbiorze relacji z nasionami na Twitterze. Z technicznego punktu widzenia to rozwiązanie jest również znacznie łatwiejsze niż próba eksploracji tekstu lub analizy geoprzestrzennej w celu polecania znajomym. Tutaj musimy po prostu policzyć, którzy z przyjaciół naszych przyjaciół śledzą większość naszych przyjaciół. Aby to zrobić, zaczynamy od wczytania pełnych danych sieciowych, które zebraliśmy wcześniej. Tak jak poprzednio, użyjemy danych Drew w tym przykładzie, ale zachęcamy do śledzenia własnych danych, jeśli je masz.
userk <- „drewconway”
user.graph <- read.graph (wklej („dane /”, user, „/”, userk, „_net.graphml”, sep = „”),
format = „graphml”)
Naszym pierwszym krokiem jest zdobycie na Twitterze nazwisk wszystkich przyjaciół seedów. Możemy użyć funkcji neighbors, aby uzyskać wskaźniki sąsiadów, ale pamiętajmy, że z powodu różnych domyślnych wartości indeksowania igraph w stosunku do R musimy dodać jedną do wszystkich tych wartości. Następnie przekazujemy te wartości do specjalnej funkcji V, która zwróci węzeł atrybutu wykresu, którym w tym przypadku jest nazwa. Następnie wygenerujemy pełną listę krawędzi wykresu jako dużą macierz N-na-2 z funkcją get.edgelist.
friends <- V(user.graph)$name[neighbors(user.graph, user, mode=”out”)+1]
user.el <- get.edgelist(user.graph)
Mamy teraz wszystkie dane, których potrzebujemy, aby policzyć liczbę moich znajomych, którzy śledzą wszystkich użytkowników, którzy nie są aktualnie śledzeni przez ziarno. Najpierw musimy zidentyfikować wiersze w pliku user.el, które zawierają linki od znajomych nasion do użytkowników, których nasiona obecnie nie śledzą. Tak jak w poprzednich rozdziałach, użyjemy wektoryzowanej funkcji sapply do uruchomienia funkcji, która zawiera dość złożony test logiczny w każdym rzędzie macierzy. Chcemy wygenerować wektor wartości PRAWDA i FAŁSZ, aby określić, które wiersze zawierają znajomych znajomych nasion, których nasiona nie śledzą. Używamy funkcji ifelse do konfigurowania testu, który sam jest wektoryzowany. Wstępny test pyta, czy którykolwiek element wiersza jest użytkownikiem i czy pierwszy element (źródło) nie jest jednym z przyjaciół nasion. Korzystamy z dowolnej funkcji, aby sprawdzić, czy którakolwiek z tych instrukcji jest prawdziwa. Jeśli tak, będziemy chcieli zignorować ten wiersz. Drugi test sprawdza, czy drugi element rzędu (cel) nie jest jednym z przyjaciół nasion. Dbamy o to, kim są przyjaciele naszych przyjaciół, a nie kto podąża za nimi, dlatego też je ignorujemy.
Ten proces może potrwać minutę lub dwie, w zależności od liczby wierszy, ale po zakończeniu wyodrębniamy odpowiednie wiersze do pliku non.friends.el i tworzymy liczbę nazw za pomocą funkcji tabel.
non.friends <- sapply(1:nrow(user.el), function(i) ifelse(any(user.el[i,]==user |
!user.el[i,1] %in% friends) | user.el[i,2] %in% friends, FALSE, TRUE))
non.friends.el <- user.el[which(non.friends==TRUE),]
friends.count <- table(non.friends.el[,2])
Następnie chcemy zgłosić wyniki. Chcemy znaleźć najbardziej „oczywisty” trójkąt do zamknięcia, dlatego chcemy znaleźć użytkowników w tych danych, które pokazują się najczęściej. Tworzymy ramkę danych z wektora utworzonego przez funkcję tabeli. Dodamy również znormalizowaną miarę najlepszych użytkowników, których należy polecić, obliczając procent znajomych nasienia, którzy stosują się do każdej potencjalnej rekomendacji. W ostatnim kroku możemy posortować ramkę danych w kolejności malejącej według najwyższego odsetka znajomych obserwujących każdego użytkownika.
friends.followers <- data.frame(list(Twitter.Users=names(friends.count),
Friends.Following=as.numeric(friends.count)), stringsAsFactors=FALSE)
friends.followers$Friends.Norm <- friends.followers$Friends.Following/length(friends)
friends.followers <- friends.followers[with(friends.followers, order(-Friends.Norm)),]
Aby zgłosić wyniki, możemy sprawdzić pierwsze 10 wierszy lub nasze 10 najlepszych rekomendacji, dla których należy postępować, uruchamiając Friends.followers [1:10,]. W przypadku Drew wyniki są w Tabeli
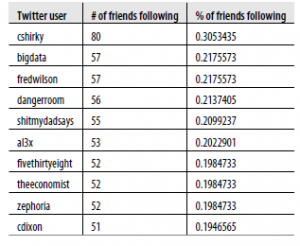
Jeśli znasz Drew, te imiona będą miały sens. Najlepszą rekomendacją Drew jest pójście za Clayem Shirky (cshirky), profesorem na NYU, który studiuje i pisze na temat roli technologii i Internetu w społeczeństwie. Biorąc pod uwagę to, czego już dowiedzieliśmy się o rozwidlonym mózgu Drew, wydaje się, że to dobre dopasowanie. Mając to na uwadze, pozostałe zalecenia pasują do jednego lub obu ogólnych zainteresowań Drew. Jest pokój niebezpieczeństw (pokój niebezpieczeństw); Blog Wired National Security; Big Data (bigdata); oraz 538 (pięćdziesiąt trzydzieści), blog prognozowania wyborów New York Timesa autorstwa Nate Silver. I oczywiście cholera. Chociaż te rekomendacje są dobre – i od czasu napisania pierwszego szkicu tej książki Drew cieszył się z nazwisk przedstawionych przez ten silnik – być może istnieje lepszy sposób na polecanie ludzi. Ponieważ wiemy już, że sieć danego użytkownika początkowego ma wiele wschodzących struktur, warto skorzystać z tej struktury, aby polecić użytkownikom pasującym do tych grup. Zamiast polecać najlepszych przyjaciół przyjaciół, możemy polecić przyjaciół przyjaciół, którzy są jak ziarno w danym wymiarze. W przypadku Drew możemy polecić zamknięcie trójkątów w jego społeczności bezpieczeństwa narodowego i politycznego lub w społeczności danych lub R.
user.ego <- read.graph(paste(“data/”, user, “/”, user, “_ego.graphml”, sep=””),
format=”graphml”)
friends.partitions <- cbind(V(user.ego)$HC8, V(user.ego)$name)
Pierwszą rzeczą, którą musimy zrobić, to załadować z powrotem do naszej sieci ego, która zawiera dane partycji. Ponieważ już zbadaliśmy partycję HC8, pozostaniemy przy tej ostatniej poprawce silnika rekomendacji. Po załadowaniu sieci utworzymy macierz friends.partitions, która ma teraz numer partycji w pierwszej kolumnie i nazwę użytkownika w drugiej. W przypadku danych Drew wygląda to tak:
> head(friends.partitions)
[,1] [,2]
[1,] “0” “drewconway”
[2,] “2” “311nyc”
[3,] “2” “aaronkoblin”
[4,] “3” “abumuqawama”
[5,] “2” “acroll”
[6,] “2” “adamlaiacano”
Teraz wszystko, co musimy zrobić, to obliczyć najbardziej oczywiste trójkąty, które należy zamknąć w każdej społeczności podrzędnej. Tworzymy więc funkcję partition.follows, która pobiera numer partycji i znajduje tych użytkowników. Wszystkie dane zostały już obliczone, więc funkcja po prostu wyszukuje użytkowników na każdej partycji, a następnie zwraca tę, która ma najwięcej obserwujących wśród znajomych nasion. Jedynym fragmentem sprawdzania błędów w tej funkcji, który może wystawać, jest instrukcja if, która sprawdza, czy liczba wierszy w danym podzbiorze jest mniejsza niż dwa. Robimy to, ponieważ wiemy, że jedna partycja będzie miała tylko jednego użytkownika, seed, i nie chcemy tworzyć rekomendacji z tej ręcznie kodowanej partycji.
partition.follows <- function(i) {
friends.in <- friends.partitions[which(friends.partitions[,1]==i),2]
partition.non.follow <- non.friends.el[which(!is.na(match(non.friends.el[,1],
friends.in))),]
if(nrow(partition.non.follow) < 2) {
return(c(i, NA))
}
else {
partition.favorite <- table(partition.non.follow[,2])
partition.favorite <- partition.favorite[order(-partition.favorite)]
return(c(i,names(partition.favorite)[1]))
}
}
partition.recs <- t(sapply(unique(friends.partitions[,1]), partition.follows))
partition.recs <- partition.recs[!is.na(partition.recs[,2]) &
!duplicated(partition.recs[,2]),]
Możemy teraz spojrzeć na te rekomendacje według partycji. Jak wspomnieliśmy, partycja „0” dla zarodka nie ma żadnych zaleceń, ale pozostałe tak. Co ciekawe, w przypadku niektórych partycji widzimy niektóre z tych samych nazw z poprzedniego kroku, ale w przypadku wielu nie.
> partition.recs
[,1] [,2]
0 “0” NA
2 “2” “cshirky”
3 “3” “jeremyscahill”
4 “4” “nealrichter”
5 “5” “jasonmorton”
6 “6” “dangerroom”
7 “7” “brendan642”
8 “8” “adrianholovaty”
Oczywiście o wiele bardziej satysfakcjonujące jest zobaczenie tych zaleceń w sieci. Ułatwi to sprawdzenie, kto jest polecany dla jakiej podspołeczności. Kod zawarty w tym rozdziale doda te zalecenia do nowego pliku wykresu zawierającego te węzły i numery partycji. Wykluczyliśmy kod tutaj, ponieważ jest to przede wszystkim ćwiczenie w zakresie sprzątania, ale zachęcamy do przejrzenia go w kodzie dostępnym w tej książce przez O’Reilly. Ostatnim krokiem będzie wizualizacja tych danych pod kątem rekomendacji Drew. Wyniki pokazano na ryc. 11-9.
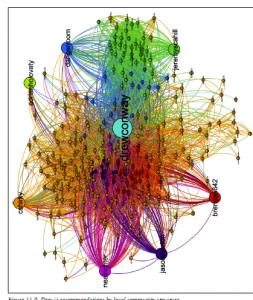
Te wyniki są całkiem dobre! Przypomnij sobie, że niebieskie węzły to ci użytkownicy Twittera w sieci Drew, którzy interesują się technologią i bezpieczeństwem narodowym. Silnik polecił blog Danger Room, który dokładnie opisuje obie te rzeczy. Zielone węzły to ludzie, którzy tweetują o polityce bezpieczeństwa narodowego; wśród nich nasz silnik polecił Jeremy Scahill jeremyscahill). Jeremy jest krajowym reporterem ds. Ekologii dla magazynu The Nation, który doskonale pasuje do tej grupy i być może informuje nas trochę o własnych perspektywach politycznych Drew. Z drugiej strony czerwone węzły to te w społeczności R. Polecający sugeruje Brendan O’Connor (brendan642), doktorantkę w dziedzinie uczenia maszynowego w Carnegie Mellon. Jest także kimś, kto tweetuje i bloguje o R. Wreszcie, grupa fioletowa zawiera innych ze społeczności danych. Tutaj sugestią jest Jason Morton (jasonmorton), asystent profesora matematyki i statystyki w stanie Pensylwania. Wszystkie te rekomendacje pasują do zainteresowań Drew, ale być może są bardziej przydatne, ponieważ teraz wiemy dokładnie, jak pasują do jego zainteresowań. Istnieje wiele innych sposobów na zhakowanie silnika rekomendacji i mamy nadzieję, że będziesz bawić się kodem i poprawiać go, aby uzyskać lepsze rekomendacje dla własnych danych.