Aby wygenerować priorytetową rangę dla każdej wiadomości w naszych danych treningowych, musimy pomnożyć wszystkie wagi wyprodukowane w poprzedniej sekcji. Oznacza to, że dla każdej wiadomości w danych musimy przeanalizować wiadomość e-mail, pobrać wyodrębnione funkcje, a następnie dopasować je do odpowiednich ramek danych wagi, aby uzyskać odpowiednią wartość wagi. Następnie weźmiemy iloczyn tych wartości, aby stworzyć jedną – i niepowtarzalną – wartość rangi dla każdej wiadomości. Następująca funkcja rank.message to pojedyncza funkcja, która pobiera ścieżkę pliku do komunikatu i generuje priorytetowy priorytet dla tej wiadomości na podstawie zdefiniowanych przez nas funkcji i ich kolejnych wag. Funkcja rank.message opiera się na wielu funkcjach, które już zdefiniowaliśmy, a także na nowej funkcji get.weights, która wyszukuje wagę, gdy funkcja nie jest mapowana na pojedynczą wagę – tzn. Temat i treść wiadomości.
get.weights <- function(search.term, weight.df, term=TRUE) {
if(length(search.term) > 0) {
if(term) {
term.match <- match(names(search.term), weight.df$Term)
}
else {
term.match <- match(search.term, weight.df$Thread)
}
match.weights <- weight.df$Weight[which(!is.na(term.match))]
if(length(match.weights) > 1) {
return(1)
}
else {
return(mean(match.weights))
}
}
else {
return(1)
}
}
Najpierw definiujemy get.weights, który przyjmuje trzy argumenty: niektóre wyszukiwane hasła (ciąg znaków), ramkę danych wagi, w której należy wyszukiwać, oraz pojedynczą wartość logiczną dla terminu. Ten końcowy parametr pozwoli nam powiedzieć aplikacji, czy sprawdza ramkę danych terminu, czy ramkę danych wątku. Będziemy traktować te wyszukiwania nieco inaczej ze względu na różnice w etykietach kolumn w ramce danych wątku. Wagi, więc musimy wprowadzić to rozróżnienie. Proces tutaj jest dość prosty, ponieważ używamy funkcji dopasowania, aby znaleźć elementy w ramce danych wagi, które pasują do search.term i zwrócić wartość masy. Ważniejsze jest to, jak funkcja obsługuje niedopasowania. Po pierwsze, przeprowadzamy jedną kontrolę bezpieczeństwa, aby upewnić się, że szukany termin przekazywany do get.weights jest prawidłowy, sprawdzając, czy ma pewną długość dodatnią. Jest to ten sam rodzaj kontroli, który przeprowadziliśmy podczas analizowania danych e-mail, aby sprawdzić, czy wiadomość e-mail rzeczywiście ma temat. Jeśli jest to niepoprawny wyszukiwany termin, zwracamy po prostu 1 (co według podstawowej matematyki nie zmieni produktu obliczonego w następnym kroku z powodu reguł pomnożenia przez 1). Następnie funkcja dopasowania zwróci wartość NA dla wszystkich elementów w wektorze wyszukiwania, które nie pasują do search.term. Dlatego wyodrębniamy wartości masy tylko dla tych dopasowanych elementów, które nie są NA. Jeśli nie ma żadnych dopasowań, wektor term.match będzie wszystkimi NA, w takim przypadku dopasuj. Ciężary będą miały zerową długość. Tak więc wykonujemy dodatkową kontrolę dla tego przypadku, a jeśli napotkamy ten przypadek, ponownie zwracamy 1. Jeśli dopasowaliśmy niektóre wartości masy, zwracamy średnią z wszystkich tych ciężarów jako wynik.
rank.message <- function(path) {
msg <- parse.email(path)
# Weighting based on message author
# First is just on the total frequency
from <- ifelse(length(which(from.weight$From.EMail == msg[2])) > 0,
from.weight$Weight[which(from.weight$From.EMail == msg[2])], 1)
# Second is based on senders in threads, and threads themselves
thread.from <- ifelse(length(which(senders.df$From.EMail == msg[2])) > 0,
senders.df$Weight[which(senders.df$From.EMail == msg[2])], 1)
subj <- strsplit(tolower(msg[3]), “re: “)
is.thread <- ifelse(subj[[1]][1] == “”, TRUE, FALSE)
if(is.thread) {
activity <- get.weights(subj[[1]][2], thread.weights, term=FALSE)
}
else {
activity <- 1
}
# Next, weight based on terms
# Weight based on terms in threads
thread.terms <- term.counts(msg[3], control=list(stopwords=stopwords()))
thread.terms.weights <- get.weights(thread.terms, term.weights)
# Weight based terms in all messages
msg.terms <- term.counts(msg[4], control=list(stopwords=stopwords(),
removePunctuation=TRUE, removeNumbers=TRUE))
msg.weights <- get.weights(msg.terms, msg.weights)
# Calculate rank by interacting all weights
rank <- prod(from, thread.from, activity,
thread.terms.weights, msg.weights)
return(c(msg[1], msg[2], msg[3], rank))
}
Funkcja rank.message używa reguł podobnych do funkcji get.weights do przypisywania wartości masy do funkcji wyodrębnionych z każdego e-maila w zestawie danych. Po pierwsze, wywołuje funkcję arse.email w celu wyodrębnienia czterech interesujących cech. Następnie stosuje serię klauzul „jeśli-to”, aby ustalić, czy którakolwiek z funkcji wyodrębnionych z bieżącego e-maila jest obecna w którejkolwiek z ramek danych wagi używanych do rangowania, i odpowiednio przypisuje wagi. od i thread.from użyj funkcji interakcji społecznościowych, aby znaleźć wagę na podstawie adresu e-mail nadawcy. Zauważ, że w obu przypadkach jeśli funkcja ifelse nie pasuje do niczego w ramkach danych masy danych, zwracana jest wartość 1. Jest to ta sama strategia, którą zastosowano w funkcji get.weights. W przypadku ważenia opartego na wątkach i terminach wykonuje się wewnętrzne parsowanie tekstu. W przypadku wątków najpierw sprawdzamy, czy oceniany e-mail jest częścią wątku, dokładnie tak samo, jak w fazie szkolenia. Jeśli tak, sprawdzamy pozycję; w przeciwnym razie przypisujemy 1. W przypadku ważenia opartego na terminach korzystamy z funkcji term.counts, aby uzyskać informacje o zainteresowaniach z funkcji wiadomości e-mail, a następnie odpowiednio przypisywać wagę. W ostatnim kroku generujemy ranking, przekazując wszystkie wartości wagi, które właśnie sprawdziliśmy, do funkcji prod. Funkcja rank.message zwraca następnie wektor z datą / godziną e-maila, adresem nadawcy, tematem i pozycją.
train.paths <- Priority.df $ Ścieżka [1: (okrągły (nrow (Prior.df) / 2))]
test.paths <- Priority.df $ Ścieżka [((okrągły (nrow (Prior.df) / 2)) + 1): Nrow (Prior.df)]
train.ranks <- lapply (train.paths, rank.message)
train.ranks.matrix <- do.call (rbind, train.ranks)
train.ranks.matrix <- cbind (train.paths, train.ranks.matrix, „TRAINING”)
train.ranks.df <- data.frame (train.ranks.matrix, stringsAsFactors = FALSE)
names (train.ranks.df) <- c („Wiadomość”, „Data”, „Od”, „Subj”, „Pozycja”, „Typ”)
train.ranks.df $ Rank <- as.numeric (train.ranks.df $ Rank)
priority.threshold <- mediana (train.ranks.df $ Rank)
train.ranks.df $ Priority <- ifelse (train.ranks.df $ Rank> = priorytet. próg, 1, 0)
Jesteśmy teraz gotowi do uruchomienia naszego rankingu! Zanim przejdziemy dalej, podzielimy nasze dane na dwa chronologicznie podzielone zestawy. Pierwszym będą dane treningowe, które nazywamy ścieżkami. Wykorzystamy wygenerowane dane rankingowe do ustalenia wartości progowej dla komunikatu „priorytetowego”. Gdy już to zrobimy, możemy uruchomić ranking nad e-mailami w test.paths, aby określić, które z nich są priorytetowe i oszacować ich wewnętrzną kolejność. Następnie zastosujemy funkcję rank.messages do wektora train.paths, aby wygenerować listę wektorów zawierających funkcje i priorytetową pozycję dla każdego e-maila. Następnie wykonujemy podstawowe czynności porządkowe w celu przekształcenia tej listy w macierz. Na koniec przekształcamy tę macierz w ramkę danych z nazwami kolumn i odpowiednio sformatowanymi wektorami. Możesz zauważyć, że train.ranks <- lapply (train.paths, rank.message) powoduje, że R rzuca ostrzeżenie. To nie jest problem, ale po prostu wynik sposobu, w jaki zbudowaliśmy ranking. Możesz zawinąć lapply w funkcję suppressWarnings, jeśli chcesz wyłączyć to ostrzeżenie. Wykonujemy teraz krytyczny krok obliczania wartości progowej dla priorytetowego e-maila. Jak widać, w tym ćwiczeniu postanowiliśmy wykorzystać medianę wartości rangi jako nasz próg. Oczywiście moglibyśmy użyć wielu innych statystyk podsumowujących dla tego progu. Ponieważ do określenia tego progu nie używamy wcześniejszych przykładów, jak należy klasyfikować wiadomości e-mail, wykonujemy zadanie, które tak naprawdę nie jest standardowym rodzajem nadzorowanego uczenia się. Ale wybraliśmy medianę z dwóch zasadniczych powodów. Po pierwsze, jeśli zaprojektowaliśmy dobrego rangera, to rangi powinny mieć płynną dystrybucję, przy czym większość e-maili ma niską rangę, a wiele mniej e-maili ma wysoką rangę. Szukamy „ważnych wiadomości e-mail”, tj. Takich, które są najbardziej wyjątkowe lub w przeciwieństwie do normalnego przepływu ruchu pocztowego. Będą to wiadomości e-mail w prawym ogonie rozkładu rang. W takim przypadku wartości większe niż mediana będą wartościami nieco większymi niż typowa ranga. Intuicyjnie właśnie tak myślimy o poleceniu priorytetowego e-maila: wybranie tych, których ranga jest większa niż typowy e-mail. Po drugie, wiemy, że dane testowe będą zawierać wiadomości e-mail, które zawierają dane, które nie pasują do niczego w naszych danych szkoleniowych. Ciągle napływają nowe e-maile, ale biorąc pod uwagę naszą konfigurację, nie mamy możliwości zaktualizowania naszego rankingu. W związku z tym możemy chcieć mieć regułę dotyczącą priorytetu, która jest bardziej obejmująca niż wyłączna. Jeśli nie, możemy pominąć wiadomości, które są tylko częściowo zgodne z naszymi funkcjami. W ostatnim kroku dodajemy nową kolumnę binarną Priority do train.ranks.df, wskazując, czy e-mail będzie polecany jako priorytet przez nasz ranking.
Rysunek
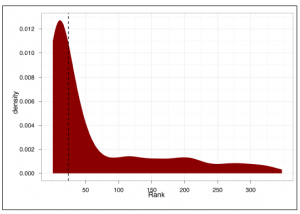
pokazuje szacunkową gęstość rang obliczoną na podstawie naszych danych treningowych. Pionowa linia przerywana to próg środkowy, który wynosi około 24. Jak widać, nasze szeregi są bardzo ciężkie, dlatego stworzyliśmy ranking, który dobrze radzi sobie z danymi treningowymi. Widzimy również, że mediana progu jest bardzo obejmująca, a znaczna część gęstości opadania jest uwzględniona jako priorytetowy e-mail. Znowu dzieje się to celowo. Znacznie mniej inkluzywnym progiem byłoby użycie standardowego odchylenia rozkładów, które możemy obliczyć za pomocą sd (train.ranks.df $ Rank). Standardowe odchylenie wynosi około 90, co prawie dokładnie wykluczałoby wiadomości e-mail poza ogonem.
Teraz obliczymy wartości rang dla wszystkich e-maili w naszym zestawie testowym. Ten proces przebiega dokładnie tak samo, jak w przypadku naszych danych szkoleniowych, więc aby zaoszczędzić miejsce, nie będziemy tutaj odtwarzać kodu. Aby zobaczyć kod, zapoznaj się z plikiem code / priority_inbox.R zawartym w tej części, zaczynając od około linii 308. Po obliczeniu rang w przypadku danych testowych możemy porównać wyniki i zobaczyć, jak dobrze radził sobie nasz ranking w nowych e-mailach.
Poniższy rysunek pokrywa gęstość szeregów z danych testowych dotyczących gęstości na powyższym rysunku.
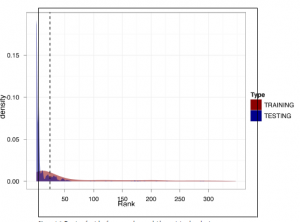
Ta ilustracja jest bardzo pouczająca pod względem jakości naszego rankingu. Po pierwsze, zauważamy, że gęstość danych testowych jest znacznie większa na bardzo niskich końcach rozkładów. Oznacza to, że jest o wiele więcej wiadomości e-mail o niskiej randze. Ponadto oszacowanie gęstości testu jest znacznie mniej płynne niż dane treningowe. Jest to dowód na to, że dane testowe obejmują wiele obserwacji, których nie ma w naszych danych treningowych. Ponieważ te obserwacje nie pasują do niczego w naszych danych treningowych, ranking skutecznie ignoruje te informacje. Chociaż jest to problematyczne, unikamy katastrof, ponieważ zastosowaliśmy próg obejmujący priorytetowe wiadomości e-mail. Zauważ, że nadal istnieje rozsądna gęstość danych testowych po prawej stronie linii progowej. Oznacza to, że nasz ranking nadal mógł znaleźć e-maile, które mogą polecić jako ważne z danych testowych. Na koniec sprawdźmy, które z nich ,e-maile, nasz ranking przesunął na szczyt. Tworzenie rankingowego tego typu cechuje nieodłączna „niepoznawalna” jakość. W całym tym ćwiczeniu przyjęliśmy założenia dotyczące każdej funkcji uwzględnionej w naszym projekcie i próbowaliśmy je intuicyjnie uzasadnić. Jednak nigdy nie możemy poznać „prawdziwej prawdy” dotyczącej tego, jak dobrze radzi sobie nasz ranking, ponieważ nie możemy wrócić i zapytać użytkownika, dla kogo te e-maile zostały wysłane, czy zamówienie jest dobre, czy może sens. W ćwiczeniu dotyczącym klasyfikacji znaliśmy etykiety dla każdego e-maila w zestawie szkoleniowym i testowym, dzięki czemu mogliśmy wyraźnie zmierzyć, jak dobrze klasyfikator radzi sobie, stosując macierz nieporozumień. W takim przypadku nie możemy, ale możemy spróbować wywnioskować, jak dobrze radzi sobie ranking, patrząc na wyniki. To właśnie czyni to ćwiczenie czymś innym niż standardowe nadzorowane uczenie się.
Poniżej pokazujemy 40 najnowszych e-maili w danych testowych, które zostały ocenione jako priorytetowe przez nasz ranking. Tabela ma naśladować to, co możesz zobaczyć w skrzynce odbiorczej e-maila, jeśli korzystałeś z tego rankingu w celu priorytetowego sortowania skrzynki odbiorczej nad wiadomościami e-mail, z dodanymi informacjami o randze wiadomości e-mail. Jeśli możesz usprawiedliwić nieco dziwne lub kontrowersyjne nagłówki tematów, zbadamy te wyniki, aby sprawdzić, w jaki sposób ranking grupuje e-maile.
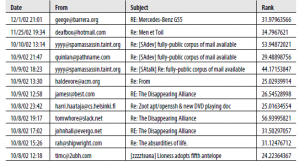
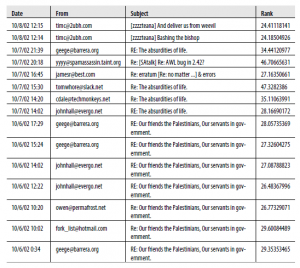
Najbardziej zachęcające w tych wynikach jest to, że ranking bardzo dobrze grupuje wątki. Możesz zobaczyć kilka przykładów tego w tabeli, gdzie e-maile z tego samego wątku zostały oznaczone jako priorytetowe i są zgrupowane razem. Ponadto ranking wydaje się przyznawać odpowiednio wysokie rangi e-mailom od częstych nadawców, jak ma to miejsce w przypadku nadawców odstających, takich jak tomwhore@slack.net i yyyy@spamassassin.taint.org. Wreszcie, i być może najbardziej zachęcające, osoba oceniająca priorytetowo traktuje wiadomości, które nie były obecne w danych szkoleniowych. W rzeczywistości tylko 12 z 85 wątków w danych testowych oznaczonych jako priorytetowe są kontynuacjami danych treningowych (około 14%). To pokazuje, że nasz ranking jest w stanie zastosować obserwacje z danych treningowych do nowych wątków w danych testowych i wydawać zalecenia bez aktualizacji. To jest bardzo dobre! W tej części przedstawiliśmy ideę wyjścia poza zestaw funkcji tylko jeden element do bardziej złożonego modelu z wieloma funkcjami. W rzeczywistości osiągnęliśmy dość trudne zadanie, a mianowicie zaprojektowanie modelu rankingu dla wiadomości e-mail, gdy widzimy tylko połowę transakcji. Opierając się na interakcjach społecznościowych, aktywności wątków i wspólnych terminach, określiliśmy cztery interesujące cechy i wygenerowaliśmy pięć ramek danych ważących do przeprowadzenia rankingu. Wyniki, które właśnie zbadaliśmy, były zachęcające, choć bez gruntownej prawdy, trudne do jednoznacznego przetestowania. Mając za sobą ostatnie dwa rozdziały, przeszedłeś przez stosunkowo prosty przykład nadzorowanego uczenia się stosowanego do przeprowadzania klasyfikacji spamu i bardzo podstawowej formy rankingu opartego na heurystyce. Jesteś gotowy na przejście do uczenia statystycznego: regresji.