Klasyfikacja Binarna
Na samym końcu poprzedniej części szybko przedstawiliśmy przykład klasyfikacji. Użyliśmy wysokości i ciężarów, aby przewidzieć, czy dana osoba jest mężczyzną czy kobietą. Na naszym przykładowym wykresie byliśmy w stanie narysować linię dzielącą dane na dwie grupy: jedną grupę, w której przewidzieliśmy „mężczyznę”, a drugą grupę, w której przewidzieliśmy „kobietę”. Linia ta została nazwana hiperpłaszczyzną oddzielającą, ale odtąd będziemy używać terminu „granica decyzji”, ponieważ będziemy pracować z danymi, których nie można poprawnie sklasyfikować przy użyciu tylko linii prostych. Stworzenie narzędzi ogólnego przeznaczenia, które pozwalają nam radzić sobie z problemami, w których granica decyzji nie jest pojedynczą linią, jest jednym z wielkich osiągnięć uczenia maszynowego. W szczególności jedno podejście, na którym skupimy się później, nazywa się sztuczką jądra, która ma niezwykłą właściwość polegającą na tym, że możemy pracować ze znacznie bardziej wyrafinowanymi granicami decyzyjnymi bez prawie dodatkowych kosztów obliczeniowych. Ale zanim zaczniemy rozumieć, w jaki sposób te granice decyzyjne są ustalane w praktyce, przejrzyjmy niektóre z wielkich pomysłów w klasyfikacji. Zakładamy, że mamy zestaw oznaczonych przykładów kategorii, które chcemy nauczyć się identyfikować. Te przykłady składają się z etykiety, którą nazwiemy również klasą lub typem, oraz szeregu mierzonych zmiennych opisujących każdy przykład. Nazwiemy te funkcje pomiarowe lub predyktory. Kolumny wzrostu i wagi, z którymi pracowaliśmy wcześniej, są przykładami funkcji, których moglibyśmy użyć do odgadnięcia etykiet „męskich” i „żeńskich”, z którymi wcześniej pracowaliśmy. Przykłady klasyfikacji można znaleźć gdziekolwiek ich szukasz:
- Czy biorąc pod uwagę wyniki mammografii, pacjentkami ma raka piersi?
- Czy pomiary ciśnienia krwi sugerują, że u pacjenta występuje nadciśnienie?
- Czy platforma kandydata politycznego sugeruje, że jest kandydatką republikańską lub demokratyczną?
- Czy zdjęcie przesłane do sieci społecznościowej zawiera twarz?
- Czy Burza została napisana przez Williama Szekspira czy Francisa Bacona?
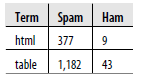
W tej części skupimy się na problemach z klasyfikacją tekstu, które są ściśle związane z narzędziami, których możesz użyć, aby odpowiedzieć na ostatnie pytanie z naszej listy. W naszym ćwiczeniu zbudujemy jednak system do decydowania, czy wiadomość e-mail jest spamem czy nieą. Nasze surowe dane pochodzą z publicznego korpusu SpamAssassin, dostępnego do bezpłatnego pobrania na stronie http://spamassassin.apache.org/publiccorpus/. Na etapie nieprzetworzonym zawiera po prostu zawartość nieprzetworzonego e-maila jako zwykły tekst. Ten nieprzetworzony tekst stanowi nasz pierwszy problem. Musimy przekształcić nasze nieprzetworzone dane tekstowe w zestaw funkcji, które opisują pojęcia jakościowe w sposób ilościowy. W naszym przypadku będzie to strategia kodowania 0/1: spam lub nie Na przykład możemy chcieć ustalić, co następuje: „Czy zawieranie tagów HTML zwiększa prawdopodobieństwo, że wiadomość e-mail jest spamem?” Aby odpowiedzieć na to pytanie, potrzebujemy strategii zamiany tekstu w naszym e-mailu na liczby. Na szczęście pakiety do eksploracji tekstu ogólnego przeznaczenia dostępne w R wykonają za nas większość tej pracy. Z tego powodu znaczna część tej części skupi się na budowaniu intuicji dla typów funkcji, z których ludzie korzystali w przeszłości podczas pracy z danymi tekstowymi. Generowanie funkcji jest głównym tematem w obecnych badaniach nad uczeniem maszynowym i wciąż jest bardzo dalekie od automatyzacji w ogólnym zastosowaniu. Obecnie najlepiej jest pomyśleć o funkcjach używanych w ramach słownictwa uczenia maszynowego, z którym lepiej się zapoznasz, wykonując więcej zadań uczenia maszynowego. Tak jak uczenie się słów nowego języka buduje intuicję dla tego, co mogłoby być realistycznie słowem, tak samo poznawanie funkcji, z których ludzie korzystali w przeszłości, buduje intuicję dla tego, które funkcje mogą być pomocne w przyszłości. Podczas pracy z tekstem historycznie najważniejszym rodzajem używanej funkcji była liczba słów. Jeśli uważamy, że tekst tagów HTML jest silnym wskaźnikiem tego, czy wiadomość e-mail jest spamem, możemy wybrać terminy takie jak „html” i „table” i policzyć, jak często występują w jednym typie dokumentu w porównaniu do drugiego. Aby pokazać, jak to podejście będzie działać z publicznym korpusem SpamAssassin, posunęliśmy się do przodu i policzyliśmy liczbę wystąpień terminów „html” i „table”. Tabela pokazuje wyniki.
Dla każdego e-maila w naszym zestawie danych nakreśliliśmy również członkostwo w klasie na powyższym rysunku. Ten wykres nie jest zbyt pouczający, ponieważ zbyt wiele punktów danych w naszym zestawie danych nakłada się. Tego rodzaju problem pojawia się dość często, gdy pracujesz z danymi, które zawierają tylko kilka unikalnych wartości dla jednej lub więcej zmiennych. Ponieważ jest to powtarzający się problem, istnieje standardowe rozwiązanie graficzne: po prostu dodajemy losowy szum do wartości przed wykreśleniem. Hałas ten „rozdzieli” punkty, aby zmniejszyć liczbę przypadków nadmiernego kreślenia. Ten dodatek hałasu nazywa się drżeniem i jest bardzo łatwy do wytworzenia w ggplot2
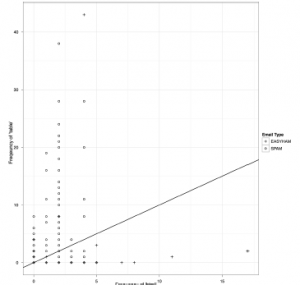
Ta ostatnia fabuła sugeruje, że moglibyśmy zrobić tak bardzo trudną decyzję, czy e-mail jest spamem, po prostu zliczając liczbę wystąpień terminów „html” i „table”. W praktyce możemy wykonać znacznie lepszą pracę, używając znacznie więcej niż tylko tych dwóch bardzo oczywistych terminów. W rzeczywistości do naszej ostatecznej analizy użyjemy kilku tysięcy terminów. Mimo że będziemy używać tylko danych z liczbą słów, nadal otrzymamy stosunkowo dokładną klasyfikację. W prawdziwym świecie chciałbyś używać innych funkcji poza liczbą słów, takich jak sfałszowane nagłówki, czarne listy adresów IP lub e-mail itp., Ale tutaj chcemy jedynie przedstawić podstawy klasyfikacji tekstu. Zanim przejdziemy dalej, powinniśmy przejrzeć niektóre podstawowe pojęcia prawdopodobieństwa warunkowego i przedyskutować ich związek z klasyfikowaniem wiadomości na podstawie jej tekstu.