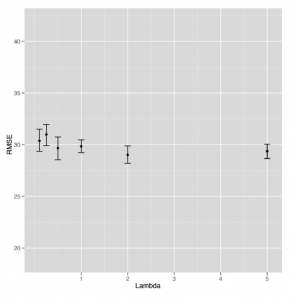
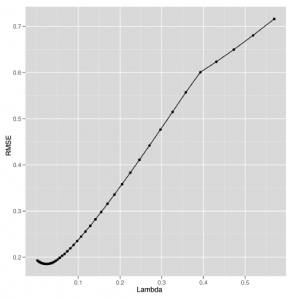
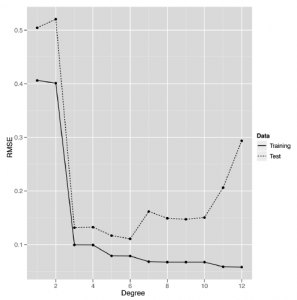
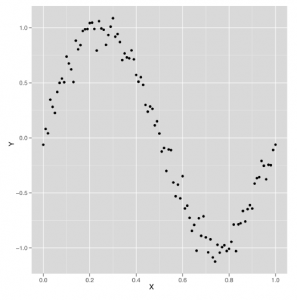
Teraz, gdy przygotowaliśmy Cię do pracy z regresjami, studium przypadku tej części skupi się na użyciu regresji do przewidywania liczby odsłon stron dla 1000 najlepszych stron internetowych w 2011 r. Pięć górnych wierszy tego zestawu danych, które dostarczone nam przez Neila Kodnera, pokazano w tabeli
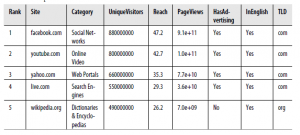
Do naszych celów będziemy pracować tylko z podzbiorem kolumn tego zestawu danych. Skupimy się na pięciu kolumnach: Rank, PageViews, UniqueVisitors, HasAdvertising i IsEnglish.
Kolumna Rank informuje nas o pozycji witryny na pierwszej liście 1000. Jak widać, Facebook jest witryną numer jeden w tym zestawie danych, a YouTube jest drugą. Rank jest interesującym rodzajem pomiaru, ponieważ jest liczbą porządkową, w której liczby są używane nie dla ich prawdziwych wartości, ale po prostu dla ich kolejności. Jednym ze sposobów uświadomienia sobie, że wartości nie mają znaczenia, jest uświadomienie sobie, że nie ma realnej odpowiedzi na pytania typu „Jaka jest 1.578. strona na tej liście?” Tego rodzaju pytanie miałoby odpowiedź, gdyby użyte liczby były wartościami kardynalnymi. Innym sposobem na podkreślenie tego rozróżnienia jest zwrócenie uwagi na rangi 1, 2, 3 i 4 na A, B, C i D i nie utracić żadnych informacji.
Następna kolumna, PageViews, to wynik, który chcemy przewidzieć w tym studium przypadku, i pokazuje nam, ile razy strona była widziana w tym roku. Jest to dobry sposób mierzenia popularności witryn, takich jak Facebook, z wielokrotnie odwiedzanymi użytkownikami, którzy często wracają. Po przeczytaniu całej części dobrym ćwiczeniem byłoby porównanie odsłon strony z UniqueVisitors, aby znaleźć sposób na stwierdzenie, które rodzaje witryn mają wiele powtarzających się odwiedzin, a które z nich mają bardzo niewiele powtórzeń. Kolumna UniqueVisitors mówi nam, ile różnych osób przyszło na stronę w ciągu miesiąca, w którym dokonano tych pomiarów. Jeśli uważasz, że wyświetlenia strony można łatwo zawyżać, powodując, że ludzie niepotrzebnie odświeżają strony, UniqueVisitors to dobry sposób na zmierzenie, ile różnych osób widzi witrynę. Kolumna HasAdvertising informuje nas, czy witryna zawiera reklamy. Możesz pomyśleć, że reklamy byłyby irytujące, a ludzie, wszyscy inni są równi, unikają witryn z reklamami. Możemy to wyraźnie przetestować za pomocą regresji. W rzeczywistości jedną z wielkich wartości regresji jest to, że pozwala ona próbować odpowiadać na pytania, w których musimy mówić o tym, że „wszystko inne jest równe”. Mówimy „spróbuj”, ponieważ jakość regresji jest tak dobra, jak nasze dane wejściowe. Jeśli w naszych danych wejściowych brakuje ważnej zmiennej, wyniki regresji mogą być bardzo dalekie od prawdy. Z tego powodu należy zawsze zakładać, że wyniki regresji są wstępne: „Gdyby dane wejściowe były wystarczające, aby odpowiedzieć na to pytanie, odpowiedź byłaby…”. Kolumna IsEnglish mówi nam, czy strona internetowa jest głównie w języku angielskim. Przeglądając listę, widać, że większość najlepszych witryn to przede wszystkim witryny w języku angielskim lub chińskim. Uwzględniliśmy tę kolumnę, ponieważ interesujące jest pytanie, czy znajomość języka angielskiego jest pozytywna, czy nie. Uwzględniamy również tę kolumnę, ponieważ jest to przykład, w którym kierunek przyczynowości nie jest wcale jasny z regresji; czy pisanie w języku angielskim zwiększa popularność witryny, czy też bardziej popularne witryny decydują się na konwersję na angielski, ponieważ jest to lingua franca w Internecie? Model regresji może powiedzieć, że dwie rzeczy są ze sobą powiązane, ale nie może powiedzieć, czy jedna rzecz powoduje drugą, czy też faktycznie działa odwrotnie. Teraz, gdy opisaliśmy dane wejściowe i zdecydowaliśmy, że PageViews będą naszymi wynikami, zacznijmy rozumieć, w jaki sposób te rzeczy odnoszą się do siebie. Zaczniemy od utworzenia wykresu rozrzutu, który wiąże odsłon strony z UniqueVisitors. Zawsze zalecamy rysowanie wykresów rozrzutu dla zmiennych numerycznych, zanim spróbujesz powiązać je za pomocą regresji, ponieważ wykres rozrzutu może wyjaśnić, kiedy założenie regresji nie jest spełnione.
top.1000.sites <- read.csv(‘data/top_1000_sites.tsv’,
sep = ‘\t’,
stringsAsFactors = FALSE)
ggplot(top.1000.sites, aes(x = PageViews, y = UniqueVisitors)) +
geom_point()
Wykres rozrzutu, który otrzymujemy z tego wywołania do ggplot
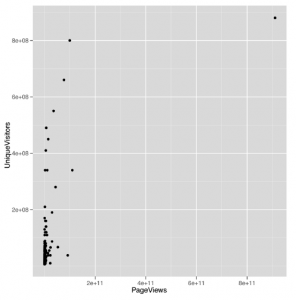
wygląda okropnie:
prawie wszystkie wartości są zebrane razem na osi X i tylko niewielka liczba wyskakuje z paczki. Jest to powszechny problem podczas pracy z danymi, które zwykle nie są dystrybuowane, ponieważ użycie skali wystarczająco dużej, aby pokazać pełny zakres wartości, powoduje, że większość punktów danych jest tak blisko siebie, że nie można ich oddzielić wizualnie. Aby potwierdzić, że kształt danych stanowi problem z tym wykresem, możemy przyjrzeć się rozkładowi odsłon stron:
ggplot(top.1000.sites, aes(x = PageViews)) +
geom_density()
Ten wykres gęstości (pokazany na rysunku 5-7)
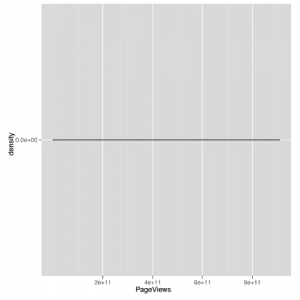
wygląda tak samo nieprzenikniony jak wcześniejszy wykres rozrzutu. Gdy zobaczysz bezsensowne wykresy gęstości, dobrym pomysłem jest wypróbowanie dziennika wartości, które próbujesz przeanalizować, i wykonanie wykresu gęstości tych wartości przekształconych w log. Możemy to zrobić za pomocą prostego wywołania funkcji dziennika R:
ggplot (top.1000.sites, aes (x = log (PageViews))) +
geom_density ()
Ten wykres gęstości (pokazany na rysunku 5-8)
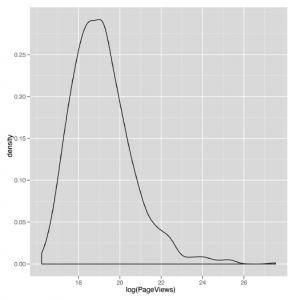
wygląda o wiele bardziej rozsądnie. Z tego powodu odtąd zaczniemy korzystać z przekształconych w dzienniki odsłon strony i UniqueVisitors. Odtworzenie naszego wcześniejszego wykresu rozrzutu na skali dziennika jest łatwe:
ggplot (top.1000.sites, aes (x = log (PageViews), y = log (UniqueVisitors))) +
geom_point ()
Pakiet ggplot2 zawiera również funkcję wygody do zmiany skali osi do dziennika. W takim przypadku możesz użyć dziennika scale_x_log lub scale_y_log. Przypomnijmy również z naszej wcześniejszej dyskusji, że w niektórych przypadkach będziesz chciał użyć funkcji logp w R, aby uniknąć błędów związanych z przyjmowaniem logarytmu zerowego. W tym przypadku jednak nie stanowi to problemu. Powstały wykres rozproszenia pokazany tu
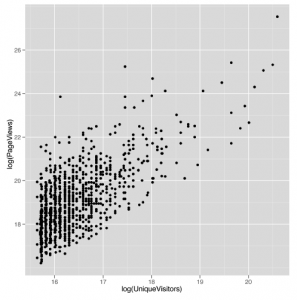
wygląda na to, że istnieje potencjalna linia do narysowania za pomocą regresji. Zanim użyjemy lm do dopasowania linii regresji, użyjmy geom_smooth z argumentem method = ‘lm’, aby zobaczyć, jak będzie wyglądać linia regresji:
ggplot(top.1000.sites, aes(x = log(PageViews), y = log(UniqueVisitors))) +
geom_point() +
geom_smooth(method = ‘lm’, se = FALSE)
Powstała linia, pokazana na rysunku 5-10,
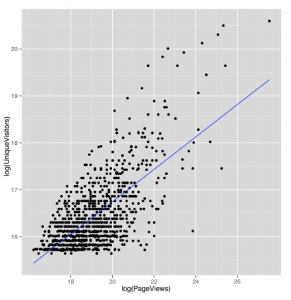
wygląda obiecująco, więc znajdźmy wartości, które określają jego nachylenie i przechwytują, wywołując lm:
lm.fit <- lm (log (PageViews) ~ log (UniqueVisitors),
data = top.1000.sites)
Teraz, gdy już dopasowaliśmy linię, chcielibyśmy uzyskać jej krótkie podsumowanie. Możemy spojrzeć na współczynniki za pomocą cefe, lub możemy spojrzeć na RMSE za pomocą reszt. Ale wprowadzimy kolejną funkcję, która tworzy znacznie bardziej złożone podsumowanie, które możemy wykonać krok po kroku. Ta funkcja jest dogodnie nazywana summary:
summary(lm.fit)
#Call:
#lm(formula = log(PageViews) ~ log(UniqueVisitors), data = top.1000.sites)
#
#Residuals:
# Min 1Q Median 3Q Max
#-2.1825 -0.7986 -0.0741 0.6467 5.1549
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) -2.83441 0.75201 -3.769 0.000173 ***
#log(UniqueVisitors) 1.33628 0.04568 29.251 < 2e-16 ***
#—
#Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
#Residual standard error: 1.084 on 998 degrees of freedom
#Multiple R-squared: 0.4616, Adjusted R-squared: 0.4611
#F-statistic: 855.6 on 1 and 998 DF, p-value: < 2.2e-16
Pierwszą rzeczą, którą mówi nam summary, jest rozmowa z lm. Nie jest to bardzo przydatne, gdy pracujesz przy konsoli, ale może być pomocne, gdy pracujesz w większych skryptach, które wykonują wiele wywołań do lm. W takim przypadku informacje te pomagają w uporządkowaniu wszystkich modeli, dzięki czemu można dokładnie zrozumieć, jakie dane i zmienne trafiły do każdego modelu. Następną rzeczą, którą mówi nam podsumowanie, są kwantyle reszt, które wyliczyłbyś, gdybyś nazwał kwantylem (reszty (lm.fit)). Osobiście nie uważamy tego za bardzo pomocne, chociaż inni wolą szukać symetrii w minimalnej i maksymalnej wartości resztkowej, niż patrzeć na wykres rozrzutu danych. Jednak prawie zawsze uważamy, że wykresy są bardziej pouczające niż streszczenia numeryczne. Następnie podsumowanie mówi nam o współczynnikach regresji o wiele bardziej szczegółowo niż zrobiłby to Coef. Dane wyjściowe z cewki kończą się w tej tabeli jako kolumna „Oszacowanie”. Następnie są kolumny dla „Std. Błąd ”,„ wartość t ”i wartość p każdego współczynnika. Wartości te służą do oceny niepewności, którą mamy w obliczonych przez nas szacunkach; innymi słowy, mają one być miarą naszej pewności, że wartości, które wyliczyliśmy z określonego zestawu danych, są dokładnymi opisami świata rzeczywistego, który wygenerował dane „Std. Błąd ”, na przykład, można wykorzystać do uzyskania 95% przedziału ufności dla współczynnika. Interpretacja tego przedziału może być myląca i czasami jest prezentowana w sposób wprowadzający w błąd. Przedział wskazuje granice, dla których możemy powiedzieć: „95% czasu, algorytm, którego używamy do konstruowania przedziałów, będzie zawierał prawdziwy współczynnik wewnątrz przedziałów, które wytwarza”. Jeśli jest to dla ciebie niejasne, to normalne: analiza niepewności jest niezwykle ważna, ale o wiele trudniejsza niż inne materiały, które omawiamy .Jeśli naprawdę chcesz zrozumieć ten materiał, zalecamy kupienie odpowiedniego podręcznika statystyki. Na szczęście tego rodzaju jakościowe rozróżnienia, które wymagają zwrócenia uwagi na standardowe błędy, zwykle nie są konieczne, jeśli próbujesz po prostu zhakować modele, aby coś przewidzieć. Zarówno „wartość t”, jak i wartość p (zapisane jako „Pr (> | t |)” w danych wyjściowych ze streszczenia) są miarami tego, jak jesteśmy pewni, że prawdziwy współczynnik nie jest równy zero. Mówi się o tym, że jesteśmy przekonani, że istnieje rzeczywisty związek między wynikami a danymi wejściowymi, które obecnie badamy. Na przykład tutaj możemy użyć kolumny „wartość t”, aby ocenić, czy jesteśmy pewni, że Wyświetlenia strony naprawdę są powiązane z UniqueVisitors. Naszym zdaniem te dwie liczby mogą być przydatne, jeśli rozumiesz, jak z nimi pracować, ale są one wystarczająco skomplikowane, aby ich użycie pomogło ludziom założyć, że nigdy nie w pełni rozumieją statystyki. Jeśli zależy ci na tym, aby mieć pewność, że dwie zmienne są ze sobą powiązane, sprawdź, czy oszacowanie wynosi co najmniej dwa standardowe błędy od zera. Na przykład współczynnik log (UniqueVisitors) wynosi 1,33628, a błąd standardowy wynosi 0,04568. Oznacza to, że współczynnik wynosi 1,33628 / 0,04568 == 29,25306 błędów standardowych od zera. Jeśli dzieli Cię więcej niż trzy standardowe błędy od zera, możesz mieć pewność, że Twoje dwie zmienne są powiązane. Wartości t i p są przydatne przy podejmowaniu decyzji, czy związek między dwiema kolumnami w danych jest prawdziwy, czy tylko przypadkiem. Decyzja o istnieniu związku jest cenna, ale zrozumienie związku to zupełnie inna sprawa. Regresje nie mogą ci w tym pomóc. Ludzie próbują je zmusić, ale ostatecznie, jeśli chcesz zrozumieć powody, dla których dwie rzeczy są ze sobą powiązane, potrzebujesz więcej informacji niż zwykła regresja.
Tradycyjnym punktem odcięcia dla pewności, że dane wejściowe są powiązane z naszymi wynikami, jest znalezienie współczynnika oddalonego od zera co najmniej o dwa standardowe błędy. Następną informacją, którą wypluwa podsumowanie, są kody istotności współczynników. Są to gwiazdki pokazane wzdłuż boku, które mają wskazywać, jak duża jest „wartość t” lub jak mała jest wartość p. W szczególności gwiazdka mówi ci niezależnie od tego, czy minął szereg arbitralnych wartości odcięcia, przy których wartość p jest mniejsza niż 0,1, mniejsza niż 0,05, mniejsza niż 0,01 lub mniejsza niż 0,001. Nie martw się o te wartości; są niepokojąco popularne w środowisku akademickim, ale tak naprawdę są reliktami z czasów, gdy analiza statystyczna była wykonywana ręcznie, a nie na komputerze. W tych liczbach nie ma dosłownie żadnej interesującej treści, która nie zostałaby znaleziona w pytaniu, ile standardowych błędów szacuje się od 0. Rzeczywiście, mogliśmy zauważyć w naszym wcześniejszym obliczeniu, że „wartość t” dla log (UniqueVisitors) była dokładnie liczbą standardu błędu od 0, że współczynnik log (UniqueVisitors) był. Ta zależność między wartościami t a liczbą błędów standardowych od zera jest na ogół prawdziwa, dlatego sugerujemy, aby w ogóle nie pracować z wartościami p. Ostateczne informacje, które otrzymujemy, są związane z mocą predykcyjną modelu liniowego, który dopasowaliśmy do naszych danych. Pierwszy element, „resztkowy błąd standardowy”, jest po prostu RMSE modelu, który moglibyśmy obliczyć za pomocą qrt (średnia (reszty (lm.fit) ^ 2)). „Stopnie swobody” odnoszą się do pojęcia, że efektywnie wykorzystaliśmy dwa punkty danych w naszej analizie, dopasowując dwa współczynniki: punkt przecięcia i współczynnik log (UniqueVisitors). Ta liczba, 998, jest istotna, ponieważ niski współczynnik RMSE nie jest imponujący, jeśli użyłeś 500 współczynników w swoim modelu, aby dopasować 1000 punktów danych. Korzystanie z wielu współczynników, gdy masz bardzo mało danych, jest formą nadmiernego dopasowania, o której powiemy więcej później. Następnie widzimy „wielokrotne R-kwadrat”. Jest to standardowy „R-kwadrat”, który opisaliśmy wcześniej, który mówi nam, jaki procent wariancji w naszych danych został wyjaśniony przez nasz model. Tutaj wyjaśniamy 46% wariancji przy użyciu naszego modelu, czyli całkiem dobre.
„Skorygowany R-kwadrat” to druga miara, która penalizuje „Wiele R-kwadrat” za liczbę użytych współczynników. W praktyce osobiście ignorujemy tę wartość, ponieważ uważamy, że jest ona nieco ad hoc, ale jest wielu ludzi, którzy bardzo ją lubią. Wreszcie ostatnia informacja, którą zobaczysz, to „Statystyka F.” Jest to miara ulepszenia twojego modelu w porównaniu z wykorzystaniem jedynie średniej do prognozowania. Jest to alternatywa dla „R-kwadrat”, która pozwala obliczyć „wartość p”. Ponieważ uważamy, że „wartość p” jest zwykle zwodnicza, zachęcamy was, abyście nie pokładali zbyt dużej wiary w statystykę F. „Wartości p” mają swoje zastosowanie, jeśli całkowicie rozumiesz mechanizm zastosowany do ich obliczenia, ale w przeciwnym razie mogą zapewnić fałszywe poczucie bezpieczeństwa, które sprawi, że zapomnisz, że złotym standardem wydajności modelu jest moc predykcyjna danych, które nie były używane do dopasowania modelu, a nie jego wydajności w stosunku do danych, do których był dopasowany. Omówimy metody oceny zdolności Twojego modelu do przewidywania nowych danych w rozdziale 6. Te dane wyjściowe z podsumowania prowadzą nas dość daleko, ale chcielibyśmy zawrzeć inne rodzaje informacji poza powiązaniem odsłon strony z UniqueVisitors. Uwzględnimy także HasAdvertising i IsEnglish, aby zobaczyć, co się stanie, gdy damy naszemu modelowi więcej danych do pracy:
lm.fit <- lm(log(PageViews) ~ HasAdvertising + log(UniqueVisitors) + InEnglish,
data = top.1000.sites)
summary(lm.fit)
#Call:
#lm(formula = log(PageViews) ~ HasAdvertising + log(UniqueVisitors) +
# InEnglish, data = top.1000.sites)
#
#Residuals:
# Min 1Q Median 3Q Max
#-2.4283 -0.7685 -0.0632 0.6298 5.4133
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) -1.94502 1.14777 -1.695 0.09046 .
#HasAdvertisingYes 0.30595 0.09170 3.336 0.00088 ***
#log(UniqueVisitors) 1.26507 0.07053 17.936 < 2e-16 ***
#InEnglishNo 0.83468 0.20860 4.001 6.77e-05 ***
#InEnglishYes -0.16913 0.20424 -0.828 0.40780
#—
#Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
#Residual standard error: 1.067 on 995 degrees of freedom
#Multiple R-squared: 0.4798, Adjusted R-squared: 0.4777
#F-statistic: 229.4 on 4 and 995 DF, p-value: < 2.2e-16
Ponownie widzimy, że summary przypomina nasze wezwanie do lm i wypisuje resztki. Nowością w tym podsumowaniu są współczynniki dla wszystkich zmiennych, które uwzględniliśmy w naszym bardziej skomplikowanym modelu regresji. Ponownie widzimy przecięcie wydrukowane jako (Inter cept). Następny wpis jest zupełnie inny niż wszystko, co widzieliśmy wcześniej, ponieważ nasz model zawiera teraz czynnik. Gdy użyjesz współczynnika w regresji, model musi zdecydować o dołączeniu jednego poziomu jako części przechwytywania, a drugiego poziomu jako czegoś, co ma być modelowane jawnie. Tutaj możesz zobaczyć, że HasAdvertising został zamodelowany w taki sposób, że strony, dla których HasAdvertising == „Tak” są oddzielone od przechwytywania, podczas gdy strony, dla których HasAdvertising == „Nie” są składane do przechwytywania. Innym sposobem na opisanie tego jest stwierdzenie, że przechwytywanie jest prognozą dla witryny, która nie ma reklam i ma zerowy dziennik (UniqueVisitors), co faktycznie występuje, gdy masz jednego UniqueVisitor. Możemy zobaczyć tę samą logikę dla InEnglish, z wyjątkiem tego, że ten czynnik ma wiele wartości NA, więc tak naprawdę istnieją trzy poziomy tej zmiennej zastępczej: NA, „Nie” i „Tak”. W takim przypadku R traktuje wartość NA jako domyślną wartość zagięcia do przechwytu regresji i pasuje do oddzielnych współczynników dla poziomów „Nie” i „Tak”. Teraz, gdy zastanowiliśmy się, w jaki sposób możemy wykorzystać te czynniki jako dane wejściowe do naszego modelu regresji, porównajmy każde z trzech danych wejściowych, które wykorzystaliśmy osobno, aby zobaczyć, która z nich ma najbardziej przewidywalną moc, gdy jest używana samodzielnie. Aby to zrobić, możemy wyodrębnić R-kwadrat dla każdego podsumowania osobno:
lm.fit <- lm(log(PageViews) ~ HasAdvertising,
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.01073766
lm.fit <- lm(log(PageViews) ~ log(UniqueVisitors),
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.4615985
lm.fit <- lm(log(PageViews) ~ InEnglish,
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.03122206
pasuje do oddzielnych współczynników dla poziomów „Nie” i „Tak”. Teraz, gdy zastanowiliśmy się, w jaki sposób możemy wykorzystać te czynniki jako dane wejściowe do naszego modelu regresji, porównajmy każde z trzech wejść, które wykorzystaliśmy osobno, aby zobaczyć, która z nich ma najbardziej przewidywalną moc, gdy jest używana samodzielnie. Aby to zrobić, możemy wyodrębnić R-kwadrat dla każdego podsumowania osobno:
lm.fit <- lm(log(PageViews) ~ HasAdvertising,
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.01073766
lm.fit <- lm(log(PageViews) ~ log(UniqueVisitors),
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.4615985
lm.fit <- lm(log(PageViews) ~ InEnglish,
data = top.1000.sites)
summary(lm.fit)$r.squared
#[1] 0.03122206
Jak widać, HasAdvertising wyjaśnia tylko 1% wariancji, UniqueVisitors wyjaśnia 46%, a InEnglish wyjaśnia 3%. W praktyce warto uwzględnić wszystkie dane wejściowe w modelu predykcyjnym, gdy są one tanie w zakupie, ale gdyby HasAdvertising był trudny do nabycia programowo, zalecamy umieszczenie go w modelu z innymi danymi wejściowymi, które mają o wiele większą moc predykcyjną