Zanim zrobisz cokolwiek innego z nowym zestawem danych, powinieneś spróbować dowiedzieć się, co reprezentuje każda kolumna w bieżącej tabeli. Niektóre osoby lubią nazywać tę informację słownikiem danych, co oznacza, że możesz otrzymać krótki słowny opis każdej kolumny w zestawie danych. Wyobraź sobie na przykład, że otrzymałeś nieznakowany zestaw danych w Tabeli
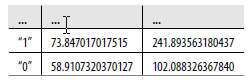
Bez jakichkolwiek danych identyfikujących naprawdę trudno jest ustalić, co zrobić z tymi liczbami. Rzeczywiście, jako punkt wyjścia powinieneś dowiedzieć się, jaki jest typ każdej kolumny: czy pierwsza kolumna jest naprawdę ciągiem, nawet jeśli wygląda na to, że zawiera tylko 0 i 1? W przykładzie UFO w pierwszym rozdziale natychmiast oznaczyliśmy wszystkie kolumny zestawu danych, który otrzymaliśmy. Gdy otrzymamy zestaw danych bez etykiet, możemy użyć niektórych funkcji określania typu wbudowanych w R. Trzy najważniejsze z tych funkcji pokazano w tabeli

Posiadanie podstawowych informacji o typach dla każdej kolumny może być bardzo ważne, gdy idziemy do przodu, ponieważ pojedyncza funkcja R często robi różne rzeczy w zależności od rodzaju jej danych wejściowych. Te zera i jedynki przechowywane jako znaki w naszym bieżącym zbiorze danych muszą zostać przetłumaczone na liczby, zanim będziemy mogli korzystać z niektórych wbudowanych funkcji w R, ale w rzeczywistości muszą zostać przekonwertowane na czynniki, jeśli będziemy używać innych wbudowane funkcje. Częściowo ta tendencja do przemieszczania się między typami pochodzi z ogólnej tradycji uczenia maszynowego do radzenia sobie z kategorycznymi różnicami. Wiele zmiennych, które naprawdę działają jak etykiety lub kategorie, jest kodowanych matematycznie jako 0 i 1. Możesz myśleć o tych liczbach, jakby były to wartości logiczne: 0 może wskazywać, że wiadomość e-mail nie jest spamem, 1 może oznaczać, że wiadomość e-mail jest spamem. To konkretne użycie zer i jedynek do opisania właściwości jakościowych obiektu jest często nazywane kodowaniem zastępczym w uczeniu maszynowym i statystyce. Atraktyczny system kodowania należy odróżnić od czynników R, które wyrażają właściwości jakościowe za pomocą wyraźnych etykiet. Czynniki w R można traktować jak etykiety, ale w rzeczywistości etykiety są kodowane numerycznie w tle: gdy programista uzyskuje dostęp do etykiety, wartości liczbowe są tłumaczone na etykiety znaków określone w indeksowanej tablicy ciągów znaków. Ponieważ R używa kodowania numerycznego w tle, naiwne próby konwersji etykiet czynnika R na liczby przyniosą dziwne wyniki, ponieważ otrzymasz rzeczywiste liczby schematów kodowania zamiast liczb powiązanych z etykietami tego czynnika. Tabele poniżen pokazują te same dane, ale dane zostały opisane za pomocą trzech różnych schematów kodowania.

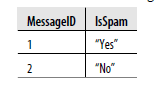
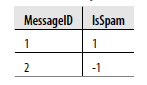
W pierwszej tabeli IsSpam należy traktować bezpośrednio jako czynnik w R, który jest jednym ze sposobów wyrażenia różnic jakościowych. W praktyce może być ładowany jako czynnik lub ciąg, w zależności od używanej funkcji przesiewania danych . Z każdym nowym zestawem danych musisz dowiedzieć się, czy wartości są ładowane poprawnie jako czynniki, czy jako ciągi znaków po tym, jak zdecydujesz, jak chcesz traktować każdą kolumnę R. Jeśli nie masz pewności, często lepiej zacząć od ładowania rzeczy jako ciągów. Zawsze możesz później przekonwertować kolumnę łańcuchową na kolumnę czynnikową. W tabeli drugiej IsSpam jest nadal pojęciem jakościowym, ale jest kodowane przy użyciu wartości liczbowych reprezentujących logiczne rozróżnienie: 1 oznacza, że IsSpam jest prawdziwy, a 0 oznacza, że IsSpam jest fałszywy. Ten styl kodowania numerycznego jest faktycznie wymagany przez niektóre algorytmy uczenia maszynowego. Na przykład glm, domyślna funkcja w R do korzystania z regresji logistycznej i algorytm klasyfikacji, który opiszemy w następnym rozdziale, zakłada, że twoje zmienne są atrapami. Wreszcie, w tabeli trzeciej pokazujemy inny rodzaj kodowania numerycznego dla tej samej koncepcji jakościowej. W tym systemie kodowania ludzie używają +1 i –1 zamiast 1 i 0. Ten styl kodowania różnic jakościowych jest bardzo popularny wśród fizyków, więc w końcu zobaczysz go, gdy przeczytasz więcej o uczeniu maszynowym. Jednak my całkowicie unikamy stosowania tego stylu notacji, ponieważ uważamy, że poruszanie się jest niepotrzebnym źródłem zamieszania