W przypadku tych danych odpowiemy na podstawowe pytanie tylko analizując je wizualnie. W pozostałej części książki połączymy analizy numeryczne i wizualne, ale ponieważ ten przykład ma jedynie na celu wprowadzenie podstawowych paradygmatów programowania R, zatrzymamy się na komponencie wizualnym. Jednak w przeciwieństwie do poprzedniej wizualizacji histogramu, ggplot2 dokłada większej staranności, aby jawnie budować warstwy wizualne. Pozwoli nam to stworzyć wizualizację, która bezpośrednio rozwiąże kwestię sezonowości w poszczególnych stanach w czasie i stworzy wizualizację bardziej profesjonalną. Zbudujemy wizualizację naraz w poniższym przykładzie, a następnie wyjaśnimy każdą warstwę osobno:
state.plot<-ggplot(all.sightings, aes(x=YearMonth,y=Sightings))+
geom_line(aes(color=”darkblue”))+
facet_wrap(~State,nrow=10,ncol=5)+
theme_bw()+
scale_color_manual(values=c(“darkblue”=”darkblue”),legend=FALSE)+
scale_x_date(major=”5 years”, format=”%Y”)+
xlab(“Time”)+ylab(“Number of Sightings”)+
opts(title=”Number of UFO sightings by Month-Year and U.S. State (1990-2010)”)
ggsave(plot=state.plot, filename=”../images/ufo_sightings.pdf”,width=14,height=8.5)
Jak zawsze, pierwszym krokiem jest utworzenie obiektu ggplot z ramką danych jako pierwszym argumentem. Używamy ramki danych all.sightings, którą utworzyliśmy w poprzednim kroku. Ponownie musimy zbudować estetyczną warstwę danych do wykreślenia, w tym przypadku oś x to kolumna YearMonth, a oś y to dane Sightings. Następnie, aby pokazać sezonowe różnice między stanami, narysujemy linię dla każdego stanu. Umożliwi nam to obserwowanie wszelkich skoków, kołysań lub wahań liczby obserwacji UFO dla każdego stanu w czasie. Aby to zrobić, użyjemy funkcji geom_line i ustawimy kolor na „ciemnoniebieski”, aby ułatwić odczytanie wizualizacji. Jak widzieliśmy w tym przypadku, dane UFO są dość bogate i obejmują wiele obserwacji w Stanach Zjednoczonych przez długi okres czasu. Wiedząc o tym, musimy wymyślić sposób na rozbicie tej wizualizacji, abyśmy mogli obserwować dane dla każdego stanu, ale także porównać je z innymi stanami. Jeśli wykreślimy wszystkie dane w jednym panelu, bardzo trudno będzie odróżnić zmienność. Aby to sprawdzić, uruchom pierwszy wiersz kodu z poprzedniego bloku, ale zamień kolor = „ciemnoniebieski” na kolor = stan i wprowadź
> print (state.plot) na konsoli. Lepszym rozwiązaniem byłoby wykreślenie danych dla każdego stanu osobno i uporządkowanie ich w siatce w celu łatwego porównania. Aby utworzyć wykres wieloaspektowy, używamy funkcji facet_wrap i określamy, że panele mają być tworzone przez zmienną State, która jest już typem czynnikowym, tj. Kategorycznym. Definiujemy również jawnie liczbę wierszy i kolumn w siatce, co jest łatwiejsze dla naszego przypadku, ponieważ wiemy, że tworzymy 50 różnych fabuł. Pakiet ggplot2 ma wiele motywów do kreślenia. Domyślnym motywem jest ten, którego użyliśmy w pierwszym przykładzie i ma on szare tło z ciemnoszarymi liniami siatki. Chociaż jest to wyłącznie kwestia gustu, wolimy użyć białego tła dla tego wykresu, ponieważ ułatwi to dostrzeżenie niewielkich różnic między punktami danych w naszej wizualizacji. Dodajemy warstwę theme_bw, która utworzy wykres z białym tłem i czarnymi liniami siatki. Gdy poczujesz się bardziej komfortowo z ggplot2, zalecamy eksperymentowanie z różnymi ustawieniami domyślnymi, aby znaleźć ten, który preferujesz. Pozostałe warstwy są wykonywane jako prace porządkowe, aby wizualizacja miała profesjonalny wygląd. Chociaż nie jest to formalnie wymagane, zwracanie uwagi na te szczegóły może oddzielić amatorskie fabuły od profesjonalnie wyglądających wizualizacji danych. Funkcja scale_color_manual służy do określania, że ciąg „ciemnoniebieski” odpowiada bezpiecznemu dla sieci kolorowi „ciemnoniebieski”. Chociaż może się to wydawać powtarzalne, stanowi on rdzeń projektu ggplot2, który wymaga wyraźnej definicji szczegółów, takich jak kolor. W rzeczywistości ggplot2 ma tendencję do myślenia o kolorach jako o sposobie rozróżniania różnych typów lub kategorii danych i jako taki woli używać typu czynnika do określania koloru. W naszym przypadku definiujemy kolor jawnie za pomocą łańcucha i dlatego musimy zdefiniować wartość tego łańcucha za pomocą funkcji scale_color_manual.
Tak jak poprzednio, używamy parametru scale_x_date, aby określić główne linie siatki w wizualizacji. Ponieważ dane te obejmują 20 lat, będziemy ustawiać je w regularnych odstępach pięcioletnich. Następnie ustawiamy etykiety z kleszczami na rok w pełnym czterocyfrowym formacie. Następnie ustawiamy etykietę osi x na „Czas”, a etykietę osi y na „Liczba obserwacji” za pomocą odpowiednio funkcji xlab i ylab. Na koniec używamy funkcji opts, aby nadać fabule tytuł. Po zbudowaniu wszystkich warstw jesteśmy teraz gotowi do renderowania obrazu za pomocą ggsave i analizy danych. Istnieje wiele interesujących obserwacji, które wynikają z tej analizy
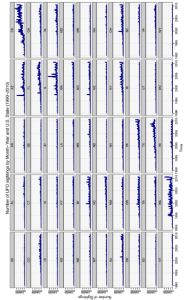
rys 1.7
Widzimy, że Kalifornia i Waszyngton są dużymi wartościami odstającymi pod względem liczby obserwacji UFO w tych stanach w porównaniu do innych. Pomiędzy tymi wartościami odstającymi istnieją również interesujące różnice. W Kalifornii liczba zgłaszanych obserwacji UFO wydaje się nieco losowa w czasie, ale stale rośnie od 1995 roku, podczas gdy w Waszyngtonie sezonowa zmienność wydaje się bardzo spójna w czasie, z regularnymi szczytami i dolinami w obserwacjach UFO począwszy od około 1995 roku Możemy również zauważyć, że wiele stanów doświadcza nagłych skoków liczby zgłaszanych obserwacji UFO. Na przykład wydaje się, że Arizona, Floryda, Illinois i Montana doświadczyły skoków w połowie 1997 roku, a Michigan, Ohio i Oregon doświadczyły podobnych skoków pod koniec 1999 roku. Tylko Michigan i Ohio są geograficznie blisko tych grup. Jeśli nie wierzymy, że są one faktycznie wynikiem pozaziemskich gości, jakie są alternatywne wyjaśnienia? Być może wzrosła czujność obywateli, aby spojrzeć w niebo, gdy tysiąclecie dobiegło końca, powodując cięższe doniesienia o fałszywych obserwacjach. Jeśli jednak jesteś przychylny poglądowi, że możemy regularnie gościć gości z kosmosu, istnieją również dowody, które wzbudzą twoją ciekawość. W rzeczywistości zaskakująca jest regularność tych obserwacji w wielu stanach w USA, a także dowody na tworzenie klastrów regionalnych. To prawie tak, jakby obserwacje naprawdę zawierały znaczący wzór