Mamy teraz uporządkowane dane do tego stopnia, że możemy zacząć je analizować! W poprzedniej sekcji poświęciliśmy dużo czasu na prawidłowe sformatowanie danych i zidentyfikowanie odpowiednich wpisów do naszej analizy. W tej sekcji zajmiemy się danymi, aby jeszcze bardziej zawęzić naszą uwagę. Te dane mają dwa podstawowe wymiary: przestrzeń (gdzie obserwacja miała miejsce) i czas (kiedy miała miejsce obserwacja). Skupiliśmy się na tym poprzednio, ale tutaj skupimy się na drugim. Po pierwsze, używamy funkcji podsumowania w kolumnie DateOccurred, aby poznać ten chronologiczny zakres danych:
summary (ufo.us $ DateOccurred)
Min. 1st Qu. Mediana oznacza 3. kwartę Max.
„1400-06-30” „1999-09-06” „2004-01-10” „2001-02-13” „2007-07-26” „30.08.2010”
Zaskakujące jest to, że dane te pochodzą z dawna; najstarsze obserwacje UFO pochodzą z 1400 roku! Biorąc pod uwagę tę wartość odstającą, następne pytanie brzmi: w jaki sposób te dane są rozłożone w czasie? I czy warto analizować całe szeregi czasowe? Szybkim sposobem na to wizualnie jest zbudowanie histogramu. W dalszej części omówimy histogramy bardziej szczegółowo, ale na razie powinieneś wiedzieć, że histogramy pozwalają na binowanie danych według określonego wymiaru i obserwowanie częstotliwości, z jaką dane wpadają do tych pojemników. Wymiar zainteresowania jest tutaj czasem, dlatego tworzymy histogram, który łączy dane w czasie:
quick.hist <-ggplot (ufo.us, aes (x = DateOccurred)) + geom_histogram () +
scale_x_date (major = „50 lat”)
ggsave (plot = quick.hist, filename = “../ images / quick_hist.png”, wysokość = 6, szerokość = 8)
stat_bin: domyślnie binwidth to zakres / 30.
Użyj „binwidth = x”, aby to dostosować.
Należy tutaj zwrócić uwagę na kilka rzeczy. To jest nasze pierwsze użycie pakietu ggplot2, którego używamy w tej książce do wszystkich naszych wizualizacji danych. W tym przypadku tworzymy bardzo prosty histogram, który wymaga tylko jednego wiersza kodu. Najpierw tworzymy obiekt ggplot i przekazujemy mu ramkę danych UFO jako początkowy argument. Następnie ustawiamy estetykę osi x na kolumnę DateOccurred, ponieważ jest to częstotliwość, którą chcemy zbadać. W przypadku ggplot2 zawsze musimy pracować z ramkami danych, a pierwszym argumentem do utworzenia obiektu ggplot musi być zawsze ramka danych. ggplot2 to implementacja R gramatyki grafiki Lelanda Wilkinsona. Oznacza to, że pakiet jest zgodny z tą szczególną filozofią wizualizacji danych, a wszystkie wizualizacje zostaną zbudowane jako seria warstw. Dla tego histogramu, pokazanego na poniższym rysunku, początkową warstwą są dane osi x, a mianowicie daty obserwacji UFO.
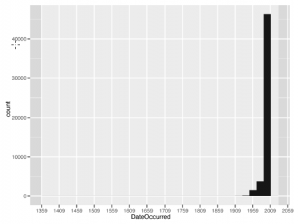
Następnie dodajemy warstwę histogramu z funkcją geom_histogram. W takim przypadku użyjemy domyślnych ustawień tej funkcji, ale jak zobaczymy później, to domyślne ustawienie często nie jest dobrym wyborem. Wreszcie, ponieważ dane te obejmują tak długi okres czasu, przeskalujemy etykiety osi X, aby pojawiały się co 50 lat za pomocą funkcji scale_x_date. Po zbudowaniu obiektu ggplot używamy funkcji ggsave do wyświetlania wizualizacji w pliku. Możemy również użyć> print (quick.hist), aby wydrukować wizualizację na ekranie. Zwróć uwagę na komunikat ostrzegawczy, który jest drukowany podczas rysowania wizualizacji. Istnieje wiele sposobów binowania danych na histogramie, a omówimy to szczegółowo w następnym rozdziale, ale to ostrzeżenie jest dostarczone, aby poinformować dokładnie, jak ggplot2 domyślnie binninguje. Jesteśmy teraz gotowi eksplorować dane dzięki tej wizualizacji. Wyniki tej analizy są surowe. Zdecydowana większość danych pochodzi z 1960 r i 2010, przy czym większość obserwacji UFO miała miejsce w ciągu ostatnich dwóch dekad. Dlatego dla naszych celów skupimy się tylko na tych obserwacjach, które miały miejsce w latach 1990–2010. Pozwoli nam to wykluczyć wartości odstające i porównać względnie podobne jednostki podczas analizy. Tak jak poprzednio, użyjemy funkcji podzestawu, aby utworzyć nową ramkę danych spełniająca te kryteria:
ufo.us <-subset (ufo.us, DateOccurred> = as.Date (“1990-01-01”))
nrow (ufo.us)
# [1] 46347
Chociaż usuwa to o wiele więcej wpisów, niż wyeliminowaliśmy podczas czyszczenia danych, nadal pozostaje nam ponad 46 000 obserwacji do analizy. Aby zobaczyć różnicę, ponownie generujemy histogram danych podzbioru na rysunku
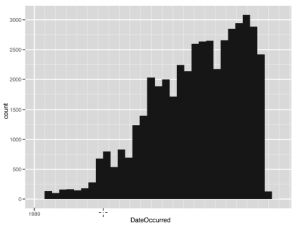
Widzimy, że w tej próbce jest znacznie więcej zmian. Następnie musimy zacząć organizować dane w taki sposób, aby można je było wykorzystać do odpowiedzi na nasze zasadnicze pytanie: co, jeśli w ogóle, istnieje sezonowa zmienność dla obserwacji UFO w stanach USA? Aby rozwiązać ten problem, musimy najpierw zapytać: co rozumiemy przez „sezonowość”? Istnieje wiele sposobów agregowania danych szeregów czasowych w odniesieniu do pór roku: według tygodnia, miesiąca, kwartału, roku itp. Ale jaki sposób agregowania naszych danych jest najbardziej odpowiedni tutaj? Kolumna DateOccurred zawiera informacje o obserwacji UFO z dnia na dzień, ale występuje znaczna niespójność pod względem zasięgu w całym zestawie. Musimy agregować dane w sposób, który umieszcza ilość danych dla każdego stanu na płaszczyznach względnie poziomych. W takim przypadku najlepszym rozwiązaniem jest robienie tego z miesiąca na miesiąc. Ta agregacja najlepiej odpowiada również na sedno naszego pytania, ponieważ agregacja miesięczna da dobry wgląd w zmiany sezonowe. Musimy policzyć liczbę obserwacji UFO, które miały miejsce w każdym stanie przez wszystkie kombinacje miesięczne w latach 1990–2010. Najpierw będziemy musieli utworzyć nową kolumnę w danych, która odpowiada obecnym latom i miesiącom. Użyjemy funkcji strftime do konwersji obiektów Date na ciąg formatu „RRRR-MM”. Tak jak poprzednio, odpowiednio ustawimy parametr formatu, aby uzyskać ciągi znaków:
ufo.us $ YearMonth <-strftime (ufo.us $ DateOccurred, format = “% Y-% m”)
Zauważ, że w tym przypadku nie użyliśmy funkcji transformacji, aby dodać nową kolumnę do ramki danych. Po prostu odwołaliśmy się do nazwy kolumny, która nie istniała, i R automatycznie ją dodał. Przydatne są obie metody dodawania nowych kolumn do ramki danych, a my przełączamy się między nimi w zależności od konkretnego zadania. Następnie chcemy policzyć, ile razy każda kombinacja stanu i rok-miesiąc występuje w danych. Po raz pierwszy użyjemy funkcji ddply, która jest częścią niezwykle użytecznej biblioteki plyr do manipulowania danymi. Rodzina funkcji plyr działa trochę jak narzędzia do agregacji danych w stylu zmniejszania mapy, które zyskały na popularności w ciągu ostatnich kilku lat. Próbują pogrupować dane w określony sposób, który był istotny dla wszystkich obserwacji, a następnie wykonać obliczenia dla każdej z tych grup i zwrócić wyniki. W tym zadaniu chcemy pogrupować dane według skrótów stanu i utworzonej właśnie kolumny rok-miesiąc. Po zgrupowaniu danych jako takich liczymy liczbę wpisów w każdej grupie i zwracamy to jako nową kolumnę. Tutaj po prostu użyjemy funkcji nrow, aby zmniejszyć dane o liczbę wierszy w każdej grupie:
sightings.counts<-ddply(ufo.us,.(USState,YearMonth), nrow)
head(sightings.counts)
USState YearMonth V1
1 ak 1990-01 1
2 ak 1990-03 1
3 ak 1990-05 1
4 ak 1993-11 1
5 ak 1994-11 1
6 ak 1995-01 1
Mamy teraz liczbę obserwacji UFO dla każdego stanu według roku i miesiąca. Jednak z połączenia głównego w tym przykładzie możemy zauważyć, że może być problem z użyciem danych, ponieważ zawiera wiele brakujących wartości. Przykładowo, widzimy, że na Alasce miało miejsce jedno obserwowanie UFO w styczniu, marcu i maju 1990 r., Ale nie ma wpisów dotyczących lutego i kwietnia. Przypuszczalnie w tych miesiącach nie było obserwacji UFO, ale dane nie zawierają wpisów dotyczących niewiedzy, więc musimy cofnąć się i dodać je jako zera. Potrzebujemy wektora lat i miesięcy obejmującego cały zestaw danych. Na tej podstawie możemy sprawdzić, czy są już w danych, a jeśli nie, dodaj je jako zera. Aby to zrobić, utworzymy sekwencję dat za pomocą funkcji seq.Date, a następnie sformatujemy je, aby pasowały do danych w naszej ramce danych:
date.range<-seq.Date(from=as.Date(min(ufo.us$DateOccurred)),
to=as.Date(max(ufo.us$DateOccurred)), by=”month”)
date.strings<-strftime(date.range, “%Y-%m”)
Dzięki nowemu wektorowi date.strings musimy utworzyć nową ramkę danych, która ma wszystkie miesiące i stany roku. Wykorzystamy to do wykonania dopasowania z danymi obserwacji UFO. Tak jak poprzednio, użyjemy funkcji lapply do utworzenia kolumn, a funkcji do.call do przekształcenia tego w macierz, a następnie w ramkę danych:
states.dates<-data.frame(do.call(rbind, states.dates), stringsAsFactors=FALSE)
head(states.dates)
s date.strings
1 ak 1990-01
2 ak 1990-02
3 ak 1990-03
4 ak 1990-04
5 ak 1990-05
6 ak 1990-06
Ramka danych States.dates zawiera teraz wpisy dla każdego roku, miesiąca i kombinacji stanów możliwych w danych. Pamiętaj, że dla Alaski są teraz wpisy z lutego i marca 1990 r. Aby dodać brakujące zera do danych obserwacji UFO, musimy połączyć te dane z naszą oryginalną ramką danych. W tym celu wykorzystamy funkcję scalania, która pobiera dwie uporządkowane ramki danych i próbuje scalić je według wspólnych kolumn. W naszym przypadku mamy dwie ramki danych uporządkowane alfabetycznie według skrótów państwowych w USA i chronologicznie według roku i miesiąca. Musimy powiedzieć funkcji, przez które kolumny scalić te ramki danych. Ustawimy parametry by.xi by.y zgodnie z pasującymi nazwami kolumn w każdej ramce danych. Na koniec ustawiamy parametr all na PRAWDA, który instruuje funkcję, aby zawierała wpisy, które nie pasują i wypełniała je NA. Wpisami w kolumnie V1 będą wpisy stanu, roku i miesiąca, dla których nie zaobserwowano UFO:
all.sightings<-merge(states.dates,sightings.counts,by.x=c(“s”,”date.strings”),
by.y=c(“USState”,”YearMonth”),all=TRUE)
head(all.sightings)
s date.strings V1
1 ak 1990-01 1
2 ak 1990-02 NA
3 ak 1990-03 1
4 ak 1990-04 NA
5 ak 1990-05 1
6 ak 1990-06 NA
Ostatnimi krokami agregacji danych są proste porządki. Najpierw ustawimy nazwy kolumn w nowej ramce danych all.sightings na coś znaczącego. Odbywa się to dokładnie tak samo, jak na początku. Następnie przekonwertujemy wpisy NA na zera, ponownie za pomocą funkcji is.na. Na koniec przekonwertujemy kolumny YearMonth i State na odpowiednie typy. Używając wektora date.range, który utworzyliśmy w poprzednim kroku i funkcji rep, aby utworzyć nowy wektor, który powtarza dany wektor, zastępujemy ciągi roku i miesiąca odpowiednim obiektem Date. Ponownie lepiej jest przechowywać daty jako obiekty Date niż ciągi, ponieważ możemy matematycznie porównywać obiekty Date, ale nie możemy tego łatwo zrobić z ciągami. Podobnie skróty stanu są lepiej reprezentowane jako zmienne kategorialne niż łańcuchy, więc konwertujemy je na typy czynników.
names(all.sightings)<-c(“State”,”YearMonth”,”Sightings”)
all.sightings$Sightings[is.na(all.sightings$Sightings)]<-0
all.sightings$YearMonth<-as.Date(rep(date.range,length(us.states)))
all.sightings$State<-as.factor(toupper(all.sightings$State))
Jesteśmy teraz gotowi do wizualnej analizy danych!