IX.Uzasadnienie i podejmowanie decyzji
Wprowadzenie
Rozumowanie i podejmowanie decyzji sḟ podstawowymi elementami podej¶cia AI do reprezentacji wiedzy i rozumowania (KR&R). KR&R zajmuje siê projektowaniem, analizḟ i wdraṡaniem algorytmów wnioskowania i struktur danych. Praca w KR&R ma gġêbokie korzenie w rzeczywisto¶ci: problemy z rozumowaniem powstajḟ naturalnie w wielu aplikacjach, które wchodzḟ w interakcje ze ¶wiatem - rozsḟdne odpowiedzi na zapytania, diagnoza rozwiḟzywania problemów, planowanie, rozumowanie wiedzy naukowej, przetwarzanie jêzyka naturalnego i kontrola wielu agentów, wymieniæ kilka. Oprócz oczywistego znaczenia praktycznego, algorytmy wnioskowania i reprezentacje wiedzy stanowiḟ podstawê teoretycznych badañ AI na poziomie ludzkim. Rozumowanie to podpola KR&R po¶wiêcona odpowiadaniu na pytania z róṡnych danych bez interwencji czġowieka lub pomocy. Zazwyczaj dane sḟ podawane w jakim¶ formalnym systemie, którego semantyka jest jasna. We wczesnych dekadach skoncentrowanych badañ nad automatycznym rozumowaniem i udzielaniem odpowiedzi na pytania (od lat 50. XX wieku) dane byġy w wiêkszo¶ci podobne do wiedzy lub naszych intuicji na ten temat. Niedawno (od lat 80.) ludzie zakġadajḟ, ṡe dane zwiḟzane z rozumowaniem sḟ mieszankḟ prostych danych i bardziej zġoṡonych danych. Te pierwsze wymagajḟ niskiego stopnia zġoṡono¶ci obliczeniowej i sḟ przedmiotem badañ duṡych baz danych (np. relacyjnych baz danych, takich jak te rejestrujḟce transakcje sprzedaṡy w firmach, oprogramowanie ksiêgowe dla osób fizycznych oraz ewidencja przedmiotów w sklepach). Te ostatnie sḟ podane w bardziej wyrazistym jêzyku, zajmujḟc mniej miejsca do przedstawienia, i odpowiadajḟ zarówno uogólnieniu, jak i drobniejszej informacji. Podejmowanie decyzji jest formḟ rozumowania, która koncentruje siê na odpowiadaniu na pytania dotyczḟce preferencji miêdzy czynno¶ciami, na przykġad w kontek¶cie autonomicznego agenta próbujḟcego wykonaæ zadanie dla czġowieka. Czêsto podejmowanie decyzji odbywa siê w dynamicznej dziedzinie, która zmienia siê wraz z wykonywaniem dziaġañ i upġywem czasu. W takich domenach wcze¶niejsze dziaġania wpġywajḟ na póỳniejsze decyzje, a zadaniem rozumowania jest znalezienie sekwencji dziaġañ lub uniwersalnego planu (polityki) reagowania na sytuacje lub wkġad sensoryczny. Podejmowane tam decyzje obejmujḟ osiḟgniêcie celów lub optymalizacjê niektórych kryteriów, takich jak dġugo¶æ planu, koszt dziaġañ lub oczekiwana nagromadzona nagroda w przyszġo¶ci. Badania nad dwoma tematami rozumowania i podejmowania decyzji sḟ czêsto przeprowadzane w oderwaniu, przy uṡyciu róṡnych metod i róṡnych teoretycznych ustaleñ dla tych dwóch tematów, a ten rozdziaġ przeglḟdowy podzielony jest wedġug podobnych linii. W rozdziale tym wyróṡniono równieṡ badania wedġug linii reprezentacji, ze szczególnym naciskiem na reprezentacje oparte na logice i prawdopodobieñstwie. Jednak badania nad tymi dwoma tematami majḟ równieṡ znaczḟcy wpġyw na wzajemne nawoṡenie i transfer najwaṡniejszych wyników, technik i pomysġów, a przeglḟd ten ma szerszḟ perspektywê, ṡe oba problemy sḟ zasadniczo takie same. Ten rozdziaġ ma na celu zarówno przeglḟd bieṡḟcych badañ, jak i omówienie aktualnych i pojawiajḟcych siê pytañ w tej dziedzinie. Obie perspektywy zostaġy przedstawione razem, starajḟc siê zapewniæ im równy nacisk. Oczywi¶cie obie perspektywy sḟ powaṡnie ograniczone. Istnieje ponad 100 000 artykuġów i ksiḟṡek na temat rozumowania i podejmowania decyzji, a ponad 3000 artykuġów jest publikowanych kaṡdego roku i nieuchronnie wiele szczegóġów technicznych i duṡe wysiġki badawcze nie mogḟ byæ tutaj uwzglêdnione.
Reprezentacja wiedzy i rozumowanie
Od samego poczḟtku pola sztucznej inteligencji jednym z dominujḟcych poglḟdów na ¶cieṡkê rozwiḟzania problemu sztucznej inteligencji byġo poszukiwanie wyraỳnej reprezentacji dla wiedzy o danym systemie i uzasadnienia na jego temat. Lata 60. przyniosġy wiele sukcesów w tym podej¶ciu, znanym póỳniej jako KR&R. Znaczna czê¶æ wysiġków zostaġa po¶wiêcona logice pierwszego rzêdu (FOL) jako ogólnemu jêzykowi reprezentacji wiedzy oraz dowodom twierdzeñ FOL jako generatorów inteligentnego zachowania. W latach 70. podniecenie ustḟpiġo po odkryciu kilku przeszkód. Te przeszkody obejmowaġy zġoṡono¶æ rozumowania z FOL, krucho¶æ systemów eksperckich, trudno¶æ w reprezentowaniu codziennej wiedzy opartej na zdrowym rozsḟdku oraz problemy FOL w reprezentowaniu przeskakiwania do wniosków lub rozumowanie z domy¶lnymi. Lata 80. XX w. Dodatkowo uwypukliġy lukê miêdzy KR&R a badaniami nad uczeniem maszynowym, teoriḟ sterowania i teoriḟ decyzji. Kolejne badania w KR&R miaġy na celu rozwiḟzanie tych problemów na dwa sposoby: zrozumienie, jak przezwyciêṡyæ trudno¶ci obliczeniowe z FOL oraz zrozumienie, w jaki sposób budowaæ uṡyteczne reprezentacje zjawisk w ¶wiecie rzeczywistym. FOL jest obliczeniowo równowaṡny maszynie Turinga, a zatem jest w stanie reprezentowaæ wszystko, co obecne komputery mogḟ obliczyæ. Ta ekspresja reprezentacji jest równieṡ powodem, dla którego obliczenia sḟ trudne, poniewaṡ FOL musi dġugo obliczaæ wiele zapytañ i moṡe nigdy nie zakoñczyæ obliczeñ dla innych. Badania nad jêzykami reprezentacyjnymi, które pozwalajḟ na ġatwe odpowiedzi na zapytania, przyniosġy wyspecjalizowane jêzyki z duṡḟ ilo¶ciḟ aplikacji. W tej sekcji opisano pracê wzdġuṡ tych ¶cieṡek badawczych, koncentrujḟc siê na logicznym rozumowaniu, probabilistycznym i zdrowym rozsḟdku.
Logika i kombinatoryka
Logika matematyczna (odtḟd logika) sġuṡy jako formalna podstawa wielu zastosowañ w ¶wiecie rzeczywistym: komputerów i teorii obliczeniowej, naszego systemu prawnego i argumentacji, a takṡe rozwoju teoretycznego i dowodów w nauce i inṡynierii. Wspóġczesna logika zrodziġa siê z wysiġków przedstawiania codziennych argumentów i rozumowania w sposób kompletny i niepodwaṡalny. Wysiġki KR&R koncentrowaġy siê na rozszerzeniu tej wizji na wykonalny automatyczny program komputerowy. W tej wizji rozumujḟcy reprezentuje swojḟ wiedzê o ¶wiecie w logice, a powody tej wiedzy za pomocḟ ogólnych algorytmów wnioskowania. Szczegóġy tego programu okazaġy siê trudne w kilku formach. Po pierwsze, niektóre rodzaje wiedzy (np. Wiedza przestrzenna, czasowa i niepewna) okazujḟ siê trudne do przedstawienia w jêzyku sentymentalnym. Po drugie, nie jest ġatwo skompilowaæ potrzebnḟ wiedzê dla duṡych aplikacji, ani nie jest ġatwo nauczyæ siê wiedzy w ekspresyjnym logicznym jêzyku. Wreszcie nie jest wykonalne obliczeniowo ani ġatwe do uzasadnienia za pomocḟ ekspresyjnych jêzyków, które wydajḟ siê potrzebne, nawet je¶li moṡna pokonaæ dwie pierwsze trudno¶ci (Tseitin 1970). Trzy krytyczne toczḟce siê debaty na ten temat to: Po pierwsze, twierdzenie, ṡe logika nie moṡe reprezentowaæ wielu rzeczy, takich jak analogia, przestrzeñ, ksztaġt, niepewno¶æ, a zatem nie naleṡy braæ ich pod uwagê za aktywnḟ rolê w budowaniu peġnej skali sztucznej inteligencji na poziomie ludzkim system. Kontrargument sugeruje, ṡe logika moṡe sġuṡyæ jako jedno z kilku narzêdzi. Obecnie kombinacja siġy reprezentacji, elastyczno¶ci i przejrzysto¶ci nie jest porównywana z ṡadnḟ innḟ metodḟ lub systemem. Druga krytyczna debata dotyczy twierdzenia, ṡe logika jest zbyt wolna, aby wnioskowaæ, i tak teṡ bêdzie ,ṡe nigdy nie gra roli we wdroṡonym systemie. Roszczenie wzajemne jest takie, ṡe istniejḟ sposoby przybliṡenia wnioskowania za pomocḟ logiki, tak aby byġa ona zgodna z ograniczeniami czasowymi, a postêpy w przyspieszaniu wnioskowania logicznego. Wreszcie, niektórzy twierdzḟ, ṡe bardzo trudno jest stworzyæ systemy logicznych aksjomatów dla znacznych rzeczywistych aplikacji. Ci, którzy wierzḟ inaczej, rozwijajḟ strumieñ aktywnych badañ nad technikami uczenia siê logicznych aksjomatów z tekstu w jêzyku naturalnym i autorów w sieci WWW . Istniejḟ róṡne rodzaje logiki; rozwaṡymy niektóre z najwaṡniejszych, w tym logikê zdañ, logikê pierwszego rzêdu, logikê modalnḟ i logikê niemonotonicznḟ. Logika zdañ jest bardzo prostym i powszechnym jêzykiem formalnej reprezentacji. Reprezentacja wiedzy odbywa siê za pomocḟ symboli zdañ (szczególny przypadek zmiennych boolowskich) 1 i ġḟczników zdañ, takich jak ∧ (i), ∨ (lub) i ¬ (nie). Na przykġad formuġa Φ = ¬rain ∨ chmury stwierdza, ṡe je¶li jest deszcz, muszḟ istnieæ chmury. Istniejḟ cztery typowe zadania wnioskowania z logicznḟ wiedzḟ zdañ:
(1) Satysfakcja: Czy istnieje model dla Φ? (model dla formuġy jest przypisaniem do wszystkich zmiennych, tak ṡe formuġa ma warto¶æ PRAWDA); (2) Entailment: Czy Q logicznie wynika z ?? (napisane Φ |= Q dla danej formuġy Q);
(3) Liczenie modeli: ile modeli ma Φ ?, i
(4) Ilo¶ciowe formuġy boolowskie (QBF): zapytania, które przeplatajḟ warunki uwarunkowania niektórych zmiennych i zadowalalno¶æ innych zmiennych.
Gġównḟ koncepcjḟ w logice klasycznej jest koncepcja pociḟgania za sobḟ lub wnioskowania. Relacja skġadniowa |- oznacza zdolno¶æ do mechanicznego wyprowadzania zapytania z zestawu aksjomatów Φ poprzez zastosowanie szeregu kombinacji syntaktycznych i manipulacji formuġami zgodnymi z danym zbiorem reguġ. Natomiast relacja semantyczna ? (uwikġanie logiczne) dostarcza nam definicji znaczenia uwikġania. Biorḟc pod uwagê semantycznḟ relacjê miêdzy strukturami formalnymi (modelami) a zdaniami logicznymi, definicje uwarunkowañ zwykle mówiḟ, ṡe zbiór zdañ logicznych pociḟga za sobḟ inne zdanie, je¶li wszystkie modele speġniajḟce kaṡde zdanie tego pierwszego speġniajḟ równieṡ to drugie. Na przykġad, je¶li wszystkie modele "deszczu" speġniajḟ "rain ∨ clouds", wówczas mówimy, ṡe "rain" logicznie oznacza "rain ∨ clouds". Logika zazwyczaj ma definicje zarówno relacji, jak i twierdzenia o "kompletno¶ci", ustanawiajḟce równowaṡno¶æ miêdzy tymi dwiema relacjami. Razem umoṡliwiajḟ obliczenia, czy Φ jest zwiḟzany z zestawem przesġanek T QBF to formuġy zdañ z kwantyfikatorami. Reprezentujḟ takie stwierdzenia, jak: "istnieje plan (sekwencja dziaġañ), który osiḟgnie cel niezaleṡnie od stanu poczḟtkowego", który moṡna zapisaæ jako QBF ∃plan ∀s0 cel(do(plan,s0)) , gdzie plan i s0 sḟ reprezentowane jako zestawy zdañ logicznych zdania, do jest kodowaniem zdañ (z wiêkszḟ liczbḟ zmiennych zdañ) wykonania sekwencji planu dziaġañ zaczynajḟcego siê od s0, a celem jest formuġa zdañ na koñcowych zmiennych do (plan, s0). Satysfakcja z ograniczeñ jest uogólnieniem logiki zdañ na zmienne, które nie sḟ logiczne i mogḟ przyjmowaæ warto¶ci w skoñczonej dziedzinie. Bieṡḟce badania nad logikḟ zdañ i satysfakcjḟ z ograniczeñ koncentrujḟ siê na znalezieniu skutecznych rozwiḟzañ dla tych zadañ, przy opracowywaniu heurystyki i teoretycznych rozwiḟzañ dla róṡnych rozkġadów problemów. Logika pierwszego rzêdu (FOL) rozszerza logikê zdañ i skġada siê z jêzyka, teorii dowodu i semantyki. Przykġad powinien wyja¶niæ róṡnicê:
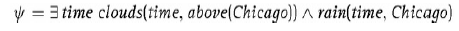
to formuġa w FOL, która mówi, ṡe sḟ czasy (∃czas), w których nad Chicago sḟ chmury, ale nie ma deszczu. Tutaj chmury i deszcz sḟ predykatami, to znaczy symbolami oznaczajḟcymi relacje, czas jest zmiennḟ wzglêdem bytów (moṡliwych czasów), Chicago jest staġym symbolem majḟcym odnosiæ siê do miasta Chicago, USA, a powyṡej (x) to symbol funkcji, który ma odnosiæ siê do obszaru powyṡej x. Formalnie jêzyk FOL ma zestaw symboli staġych obiektowych, zestaw symboli predykatów relacji, zestaw symboli funkcji i zestaw ġḟczników (OR (∨), AND (∧), NOT (¬)), kwantyfikatory (ISTNIEJE (∃), DLA WSZYSTKICH (∀)) i nawiasy jako operatory budynku. Razem wybrany zestaw symboli predykatów, staġych i funkcji nazywany jest sygnaturḟ jêzyka. Na przykġad powyṡszy wzór Ψ ma sygnaturê < Chicago; chmury, deszcz;> . FOL ma bogatszḟ interpretacjê niṡ logika zdañ. Interpretacja to para M =
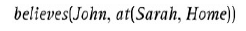
ma operator modalny believe, który jako argument przyjmuje staġy symbol John i FOL w (Sarah, Home). W tym przykġadzie operator modalny uwaṡa, ṡe lekcewaṡy warto¶æ prawdy w (Sarah, Home). Byæ moṡe Sarah nie ma w domu, ale John w to wierzy. Wiele operatorów modalnych uṡywanych w AI oznacza odpowiednio wiedzê i przekonania, K i B. Unikalnḟ moṡliwo¶ciḟ takich jêzyków jest moṡliwo¶æ omawiania przekonañ na temat przekonañ na temat przekonañ i tak dalej. Na przykġad moṡna wyraziæ (i uzasadniæ) przekonanie Sary, ṡe John zna poġḟczenie z sejfem:
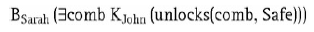
Podobnie, biorḟc pod uwagê grupê agentów, moṡna przedstawiæ i uzasadniæ przekonania grupy (np. Kaṡdy wie, ṡe John zna poġḟczenie z sejfem) oraz o powszechnej wiedzy (tj. Kaṡdy wie, ṡe kaṡdy wie …). Wreszcie, innym waṡnym zastosowaniem logiki modalnej jest zdolno¶æ do reprezentowania wymagañ i wiedzy w miarê upġywu czasu, na przykġad w ostateczno¶ci. Jest to szczególnie przydatne w formalnej weryfikacji i innych podej¶ciach do zapewnienia poprawno¶ci obwodów cyfrowych, protokoġów i oprogramowania. Wszystkie omówione powyṡej logiki sḟ monotoniczne, to znaczy dodanie wiedzy nigdy nie powoduje, ṡe wyciḟgamy wnioski. Formalnie, dla wzorów A, B, C, je¶li A |= C, to takṡe A ∧ B |= C, niezaleṡnie od tego, czym jest B. Ta monotoniczno¶æ nie ma miejsca w sytuacjach, w których dochodzi siê do wniosków bez uprzedzenia, dlatego w ciḟgu ostatnich trzydziestu do czterdziestu lat pojawiġa siê dziedzina skupiajḟca siê na wytwarzaniu systemów, które zapewniajḟ wġa¶ciwe ramy rozumowania w niemonotonicznych formach dotyczḟcych sytuacji ¶wiata rzeczywistego. Przykġadem takiej niemonotonicznej logiki jest opis, który jest metodḟ rozumowania niemonotonicznego, która przyjmuje zaġoṡenia dotyczḟce minimalizacji niektórych predykatów, je¶li zaġoṡenia te sḟ zgodne z resztḟ wiedzy. Na przykġad,
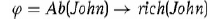
mówi, ṡe John nie jest bogaty, chyba ṡe jest nienormalny. Minimalizowanie predykatu Ab w Φ, tak aby dotyczyġo tylko tych rzeczy, o których wiadomo, ṡe sḟ nienormalne, oznacza, ṡe Jan nie jest bogaty. Je¶li dowiemy siê teraz, ṡe John zainwestowaġ w Google przed uruchomieniem gieġdy, Ab rozszerzy siê o Johna i wycofamy ostatni wniosek. Niemonotoniczna linia rozumowania poszerzyġa siê od czasu swojego debiutu i obecnie istnieje kilka podrêczników, które dajḟ rzetelny obraz i jej zastosowañ. W badaniu róṡnych reguġ wnioskowania i aksjomatów relacja wnioskowania jest zadowalajḟca, rozwaṡa siê relacjê wnioskowania jako relacjê miêdzy zbiorem zdañ a zdaniem w jêzyku formalnym - zazwyczaj albo w zdaniu, albo w pierwszym rzêdzie. Kraus, Lehmann i Magidor (1990) i dalsze prace badajḟ warunki, jakie powinna speġniaæ ta relacja powiḟzania, z pewnymi praktycznymi implikacjami. Wiêkszo¶æ prac na ten temat dotyczyġa konkretnych scenariuszy, w szczególno¶ci rewizji przekonañ . Obecnie gġównymi zastosowaniami niemonotonicznych systemów wnioskowania sḟ formalizowanie róṡnych aspektów rozumowania zdrowego rozsḟdku i szybka implementacja metod rozumowania w ograniczonych zestawach niemonotonicznych problemów wnioskowania. Tematy aplikacji wykorzystujḟce te techniki obejmujḟ robotykê kognitywnḟ, planowanie, uczenie siê i reprezentowanie preferencji oraz szybkie rozwiḟzania dla ekspresyjnych rozszerzeñ logiki zdañ.
Reprezentacje probabilistyczne i rozumowanie
Wiedzê o zjawiskach stochastycznych oraz niepewno¶æ dotyczḟcḟ wiedzy i przekonañ moṡna uchwyciæ za pomocḟ narzêdzi z teorii prawdopodobieñstwa i statystyki. Narzêdzia te uġatwiajḟ dyskusjê i automatyczne rozumowanie na temat prawdopodobieñstwa zdarzeñ, przekonañ, które moṡemy utrzymywaæ, zmian w tych przekonaniach podczas dokonywania obserwacji oraz naszego stopnia pewno¶ci w tych przekonaniach. Badania nad tym paradygmatem staġy siê popularne w ostatnich latach. Badania koncentrujḟ siê na reprezentacji róṡnych rodzajów niepewno¶ci i niepewnej wiedzy, rozumowaniu z tymi rodzajami wiedzy i uczeniu siê ich. Jest równieṡ ¶ci¶le zwiḟzany ze statystycznym podej¶ciem do uczenia maszynowego i teorii sterowania, uġatwiajḟc w ten sposób rozwój stosowanych systemów o znaczeniu praktycznym, takich jak zastosowania w diagnostyce medycznej, sterowanie robotami, widzenie maszynowe i przetwarzanie jêzyka naturalnego. W tej sekcji omówiono gġówne podej¶cia i problemy dotyczḟce tego pola badañ. Dotyczy to gġównie modeli graficznych rozkġadów prawdopodobieñstwa i opisuje niektóre podstawowe zaġoṡenia ich wykorzystania. Te modele graficzne sḟ konstrukcjami matematycznymi opisujḟcymi fragmenty rzeczywisto¶ci, z pewnymi zaġoṡeniami strukturalnymi i parametrami liczbowymi. W tej sekcji omówiono równieṡ podej¶cia do wnioskowania na podstawie tych modeli oraz uczenia siê ich parametrów i struktur na podstawie danych. Teoria prawdopodobieñstwa opiera siê na pojêciu eksperymentu losowego, a mianowicie eksperymentu, którego wynik moṡna przewidzieæ z ograniczonḟ pewno¶ciḟ. Zazwyczaj zakġadamy, ṡe eksperyment moṡna powtórzyæ w identycznych okoliczno¶ciach z identycznymi wġa¶ciwo¶ciami statystycznymi dla wyniku. Zaġoṡenia te pozwalajḟ na dyskusjê, opis i rozumowanie na temat niepewnej wiedzy (np. Uwaṡam, ṡe akcje Facebooka jutro wzrosnḟ z pewno¶ciḟ 0,5) i wiedzy statystycznej (np. 50% dni, kiedy akcje Facebooka zyskujḟ na warto¶ci). Wġa¶ciwo¶ci losowego eksperymentu sḟ rejestrowane przy uṡyciu zmiennych losowych i rozkġadu prawdopodobieñstwa. Kaṡda zmienna losowa X jest abstrakcjḟ, która odnosi siê do (nieznanego z góry) wyniku (warto¶ci) x losowego eksperymentu. Na przykġad zmienna losowa UpFacebook moṡe mieæ warto¶ci PRAWDA lub FA£SZ. Rozkġad prawdopodobieñstwa P odwzorowuje warto¶ci, które zmienna losowa moṡe przyjmowaæ do segmentu liczb rzeczywistych [0, 1]. W powyṡszym przykġadzie P (UpFacebook = TRUE) = 0,5 wychwytuje oba pojêcia niepewnej wiedzy i wiedzy statystycznej, tylko z róṡnymi podstawowymi zaġoṡeniami dotyczḟcymi znaczenia losowego eksperymentu. Wiele przypadków interesujḟcych spoġeczno¶æ AI dotyczy domen, które sḟ zbyt duṡe, aby moṡna byġo je bezpo¶rednio sprecyzowaæ i uzasadniæ. Na przykġad, gdy nasza przestrzeñ próbki ? dla powyṡszego przykġadu ma n zapasów, Ω ma 2 warto¶ci n. Prosta reprezentacja rozkġadu tych warto¶ci ma postaæ tabeli, w której kaṡdy wiersz jest moṡliwḟ kombinacjḟ warto¶ci dla kaṡdego stanu zapasów (np. UpFacebook = True, UpGoogle = False itp.). Tak wiêc ta tabela miaġaby 2n wierszy, a zatem byġaby zbyt duṡa, aby pomie¶ciæ jḟ w pamiêci komputera dla skromnego n = 50. Z tego powodu, od lat 90. badania koncentrowaġy siê na podej¶ciach do kodowania rozkġadów prawdopodobieñstwa w tak duṡych domenach razem z metodami wnioskowania za pomocḟ tych kodowañ. Graficzne modele probabilistyczne (inaczej modele graficzne) sḟ jednym z najpopularniejszych podej¶æ do reprezentowania rozkġadów prawdopodobieñstwa w takich domenach ¶wiata rzeczywistego. Popularna wersja tego podej¶cia, sieci bayesowskie kodujḟ rozkġady prawdopodobieñstwa za pomocḟ ukierunkowanych wykresów, takich jak na rysunku
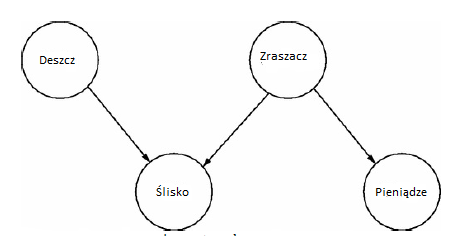
Kierowany wykres to zestaw wêzġów (kóġ na tym schemacie) i ġḟczḟce je strzaġki. Kaṡdy wêzeġ odpowiada losowej zmiennej i zawiera tabelê prawdopodobieñstwa warunkowego (CPT) prawdopodobieñstwa tej zmiennej losowej, biorḟc pod uwagê warto¶ci jej rodziców (wêzġy wskazujḟce strzaġki w kierunku tej zmiennej). Bayesowska reprezentacja sieci rozkġadu prawdopodobieñstwa P (X 1, …, X n) reprezentuje go jako iloczyn prawdopodobieñstw warunkowych. Zawiera ukierunkowany wykres bez ukierunkowanych cykli, a prawdopodobieñstwa warunkowe w produkcie to P (Xi | pai, gdzie pa i sḟ rodzicami Xi. Wynikowa reprezentacja jest znacznie bardziej zwarta niṡ prosta, poniewaṡ liczba rodziców zmiennej jest zwykle mniejsza (np. dwa lub trzy) niṡ caġkowita liczba zmiennych, n, co powoduje maġe warunkowe tabele prawdopodobieñstwa. Czasami sieci bayesowskie sḟ postrzegane jako kodujḟce zwiḟzek przyczynowy miêdzy funkcjami domeny, na przykġad gdy akcje Facebooka
wpġywajḟ na stan innej akcji. Przyczynowo¶æ ma niewiele wspólnego z matematycznḟ reprezentacjḟ sieci bayesowskich, ale intuicja przyczynowo¶ci wielokrotnie mówi o kierunkach pokazanych w sieci bayesowskiej i jest uṡytecznḟ heurystḟ w budowaniu tych reprezentacji sieci. Istnieje kilka rodzajów zadañ zwiḟzanych z wnioskami z informacjami probabilistycznymi. Typowe zadania to ocena prawdopodobieñstwa krañcowego lub warunkowego, znalezienie najbardziej prawdopodobnego przypisania do zmiennych przy danych obserwacjach i generowanie próbek z rozkġadu. W przypadku wspólnego rozkġadu P (X, Y) marginalna P (X) jest zdefiniowana jako P (X) = ΣY P (X,Y), gdzie X i Y sḟ zestawami zmiennych, a symbol sumowania z indeksem Y oznacza sumowanie wszystkich warto¶ci, które Y moṡe przyjḟæ. Prawdopodobieñstwo krañcowe jest zatem pierwotnym prawdopodobieñstwem zastosowanym tylko do podzbioru zmiennych. Na przykġad P (wysoki, gruby) jest wspólnym prawdopodobieñstwem, ṡe kto¶ jest jednocze¶nie wysoki i gruby, podczas gdy P
(wysoki) jest marginalnym pierwszym, gdy interesuje nas tylko wysoki. Zazwyczaj jeste¶my zainteresowani znalezieniem krañcowego prawdopodobieñstwa, ṡe X przyjmie pewnḟ warto¶æ x. Polega to na zsumowaniu wszystkich warto¶ci, które Y moṡe przyjḟæ. Na przykġad, je¶li chcemy znaleỳæ prawdopodobieñstwo, ṡe akcje Facebooka wzrosnḟ, UpFacebook, i mamy wspólny rozkġad losowych zmiennych dla wszystkich akcji, musimy zmarginalizowaæ (zsumowaæ) wszystkie zmienne, które nie sḟ Up Facebook. . Pod wzglêdem koncepcyjnym obliczanie marginesów jest proste z jego definicji. W praktyce marginalizacja nie jest prosta w przypadku duṡych modeli, poniewaṡ sumowanie moṡe potrwaæ wykġadniczo w liczbie zmiennych, które siê sumuje. Z tego powodu wiele badañ jest inwestowanych w efektywne obliczanie marginesów. Te badania mogḟ równieṡ sġuṡyæ do ġatwego obliczania innych zadañ zwiḟzanych z rozumowaniem, takich jak znajdowanie najbardziej prawdopodobnych diagnoz medycznych i lokalizowanie robotów. W przypadku sieci
bayesowskich obowiḟzuje jeden prosty sposób obliczania marginesów i sumowanie zmiennych w sposób ostroṡny wzdġuṡ struktury wykresu. Najpierw podsumowuje zmienne, które majḟ bardzo niewielu rodziców lub dzieci, najlepiej bez rodziców lub bez dzieci. To podsumowanie tworzy nowy wykres sieci bayesowskiej bez tego wêzġa, prawdopodobnie tworzḟc nowe poġḟczenia miêdzy rodzicami i dzieæmi usuniêtego wêzġa. W ten sposób eliminujemy wêzġy z wykresu, dopóki nie zostanie nam tylko nasza losowa zmienna zainteresowania na wykresie. Podczas tego iteracyjnego procesu aktualizujemy reprezentacjê wykresu i CPT w sposób, który nie wymaga wiêcej niṡ lokalne obliczenia na przetwarzanie li¶cia (li¶æ jest wêzġem bez dzieci). Je¶li struktura grafu sieci bayesowskiej jest wystarczajḟco prosta, obliczenia te wymagajḟ czasu, który jest liniowo proporcjonalny do liczby wierzchoġków na wykresie (liczba zmiennych w rozkġadzie), a takṡe liniowo proporcjonalny do wielko¶ci CPT. Wiêkszo¶æ praktycznych zastosowañ wymaga modeli
probabilistycznych, które sḟ zbyt skomplikowane dla precyzyjnych metod. W takich przypadkach ludzie zwracajḟ siê do atrakcyjnego przybliṡenia metody rozumowania. Takie metody zapewniajḟ wyniki zwiḟzane z prawidġowym rozumowaniem, ale z ograniczonymi gwarancjami. Rodzaj przybliṡenia rozumowania zaleṡy od zadania i rodziny metod, które stosujemy. Wczesne badania miaġy na celu znalezienie metod, które zwracajḟ wyniki wnioskowania, które sḟ nieprecyzyjne co najwyṡej przez staġy czynnik. Niestety wyniki wykazaġy, ṡe takie przybliṡenie nie jest teoretycznie moṡliwe, chyba ṡe fundamentalne pytanie w informatyce zostanie rozwiḟzane pozytywnie. Pytanie brzmi, czy znalezienie zadowalajḟcego przypisania w logice zdaniowej moṡe byæ wykonane w czasie wielomianowym w wielko¶ci problemu wej¶ciowego. Poniewaṡ uwaṡa siê, ṡe nawet przybliṡenie wnioskowania probabilistycznego jest twarde, przypieczêtowaġo to dḟṡenie do praktycznych sposobów przybliṡenia rozumowania z gwarancjami precyzji. Obecne przybliṡone probabilistyczne
techniki wnioskowania sḟ podzielone na dwa gġówne paradygmaty. Pierwsze przybliṡenie wariacyjne próbuje przybliṡyæ model probabilistyczny z modelem ġatwiejszym do obliczenia. Najpopularniejsza technika wykorzystuje formê przekazywania wiadomo¶ci, to znaczy przetwarzania dowodów i obserwacji na wykresie oraz wysyġania wiadomo¶ci miêdzy wêzġami na wykresie. Takie komunikaty pomagajḟ zaktualizowaæ lokalne oszacowania marginesów w kaṡdym wierzchoġku, a konsekwencje sḟ wykorzystywane do dostarczenia przybliṡonych rozwiḟzañ dla tych marginesów. Komunikaty mogḟ przechodziæ na wykresie bez okre¶lonej kolejno¶ci, choæ czasami niektóre zamówienia gwarantujḟ szybszḟ konwergencjê. Drugi paradygmat przybliṡonego wnioskowania, techniki Monte Carlo, koncentruje siê na zapewnieniu zestawu odpowiedzi na zapytanie, które moṡna wykorzystaæ do przybliṡenia pierwotnego zapytania. Obejmuje to pobieranie próbek. Staramy siê generowaæ próbki z podanego rozkġadu prawdopodobieñstwa i wykorzystujemy je do odpowiedzi na nasze
zapytania. Na przykġad w powyṡszej historii na Facebooku próbkowanie wygeneruje m przykġadów (m zaleṡy od czasu, jaki mamy na obliczenia), z których kaṡdy przypisuje warto¶ci do wszystkich zmiennych w modelu - to znaczy kaṡdy przykġad okre¶la, czy kaṡdy z n akcji w naszej historii idzie w górê. Bierzemy pod uwagê, ile z tych m próbek odpowiada pozytywnie na nasze zapytanie, i uṡywamy go do zwrócenia przybliṡonej odpowiedzi. Uczenie maszynowe to podpola sztucznej inteligencji zwiḟzana z komputerowym automatycznym uczeniem siê z danych wzorców. Celem uczenia maszynowego jest wykorzystanie niektórych danych szkoleniowych do wykrywania wzorców, a nastêpnie wykorzystanie tych wyuczonych wzorców do automatycznego odpowiadania na pytania oraz samodzielnego podejmowania i wykonywania decyzji. Przykġadami uczenia maszynowego sḟ modele wyuczone przez komputery w celu przewidywania preferencji uṡytkowników dotyczḟcych ksiḟṡek, programów telewizyjnych i decyzji zakupowych w sklepach spoṡywczych. Tam dane szkoleniowe
to ksiḟṡki, które ludzie wybrali w przeszġo¶ci oraz cechy tych ksiḟṡek i osób, które je wybraġy. Modele wyuczone z tych danych szkoleniowych sḟ nastêpnie wykorzystywane do przewidywania innych ksiḟṡek, które ludzie prawdopodobnie kupiliby. Modele probabilistyczne sḟ zbliṡone do statystycznego uczenia maszynowego i sġuṡḟ jako medium miêdzy uczeniem maszynowym a automatycznym wnioskowaniem. Uczenie maszynowe modeli probabilistycznych dzieli siê na dwa podstawowe zadania: uczenie siê CPT po podaniu wykresu i uczenie siê samego wykresu. Biorḟc pod uwagê przykġady szkolenia, uczenie maszynowe CPT jest stosunkowo ġatwe i sprowadza siê do zliczenia liczby przypadków, gdy zmienna losowa otrzymuje pewnḟ warto¶æ z czasów, gdy rodzice otrzymali odpowiednie warto¶ci. Ta metoda nazywana jest szacowaniem parametrów wedġug maksymalnego prawdopodobieñstwa. Nauka struktury graficznej modelu jest trudniejsza i odbywa siê poprzez ulepszanie modelu krok po kroku. Typowe metody stosujḟ algorytm zwany maksymalizacjḟ oczekiwañ (EM), który mierzy prawdopodobieñstwo, ṡe obecny hipotetyczny model wyja¶nia dane (tj. Ÿe ten model jest w rzeczywisto¶ci poprawny i ṡe wygenerowaġ dane treningowe). EM proponuje alternatywne zmiany w modelu i wybiera ten, który najlepiej poprawia obja¶nienie danych treningowych. Obecne badania dotyczḟce reprezentacji probabilistycznej, uczenia siê i wnioskowania koncentrujḟ siê na zagadnieniach obejmujḟcych duṡḟ liczbê zmiennych (duṡa tutaj jest wiêksza niṡ, powiedzmy, 100 zmiennych). £ḟczne rozkġady ponad 100 zmiennych mogḟ byæ bardzo róṡne, gdy w rzeczywisto¶ci (z ludzkiej perspektywy) wydajḟ siê niemal identyczne (np. Rozkġad cech ulic jednego bloku miasta moṡe byæ bardzo róṡny od drugiego, ale mogḟ wyglḟdaæ to samo dotyczy niewytrenowanego oka). Ludzie przyjmujḟ takie zaġoṡenia, jak niezaleṡno¶æ zmiennych losowych, które nie sḟ prawdziwe, co prowadzi do nieprawidġowego postrzegania podobieñstwa sytuacji.
Zautomatyzowane podejmowanie decyzji
Podejmowanie decyzji dotyczy podejmowania decyzji, które nastêpnie sḟ wykonywane na ¶wiecie przez niezaleṡnego agenta lub przez osobê zasiêgajḟcḟ porady od decydenta. Na przykġad agenci gier, autonomiczne roboty, agenci WWW i agenci konwersacji podejmujḟ decyzje, co robiæ. Czêsto decyzje te uwzglêdniajḟ dynamikê ¶wiata, na przykġad gdy komputerowy gracz wybiera akcjê opartḟ na przyszġych moṡliwych dziaġaniach przeciwnika. Innym razem decyzje sḟ podejmowane bez wyraỳnej ¶cieṡki na przyszġo¶æ, na przykġad kiedy decydujemy siê na wynajem mieszkania w okre¶lonej cenie i lokalizacji. Podejmowanie decyzji jako obszar badañ obejmuje dyscypliny ekonomiczne, psychologiczne, informatyczne i praktycznie wszystkie dyscypliny inṡynierskie. W szczególno¶ci w informatyce i sztucznej inteligencji badania nad podejmowaniem decyzji koncentrujḟ siê na zautomatyzowanych sposobach i wġa¶ciwo¶ciach obliczeniowych procesu decyzyjnego. Oczywi¶cie badania nad podejmowaniem decyzji przez ludzi wpġywajḟ na sposób zautomatyzowania procesu decyzyjnego, ale ten aspekt jest poza zakresem sztucznej inteligencji i tego badania. Automatyczne podejmowanie decyzji moṡna podzieliæ na kilka osi, które moṡna sformuġowaæ jako pytania: (1) Czy dziedzina ma charakter dynamiczny, w którym potrzebna jest sekwencja decyzji, lub o charakterze bardziej statycznym, w którym podejmowana jest jedna lub zestaw równolegġych decyzji ? Je¶li to pierwsze, czy staramy siê optymalizowaæ decyzje dla ograniczonego (maġego) zestawu kroków czasowych, czy podejmowaæ (bliskie) optymalne decyzje, które uwzglêdniajḟ (zasadniczo) nieskoñczonḟ przyszġḟ sekwencjê zdarzeñ? (2) Czy dziedzina o charakterze deterministycznym, niedeterministycznym czy stochastycznym? Na przykġad, czy nasze dziaġania wpġywajḟ na ¶wiat w sposób deterministyczny (zawsze taki sam, je¶li jest wykonywany w tych samych warunkach) lub stochastyczny (np. W poġowie przypadków, gdy nasze dziaġania zawodzḟ)? (3) Czy próbujemy zoptymalizowaæ narzêdzie, czy tylko staramy siê osiḟgnḟæ cel? (4) Czy dziedzina jest w peġni obserwowana przez caġy czas (np. Caġy czas widzimy peġny stan szachownicy), czy czê¶ciowo obserwowana (np. Nie widzimy czy ¶wiatġo jest wġḟczone w pokoju, chyba ṡe jeste¶my w tym pokoju)? Pozostaġa czê¶æ dotyczy podej¶æ do autonomicznego podejmowania decyzji opracowanych w ciḟgu ostatnich piêædziesiêciu lat. Te techniki zostaġy opracowane aby byæ praktyczne, dlatego sḟ wynikiem uproszczenia zaġoṡeñ i decyzji projektowych, których poprawno¶æ jest wḟtpliwa. Zaġoṡenia te obejmujḟ: wybrane reprezentacje dziaġañ deterministycznych (dziaġania majḟ warunki wstêpne i skutki okre¶lone przez formuġy logiczne); istnienie naprawdê deterministycznych dziaġañ w praktyce; poprawna i peġna znajomo¶æ modelu ¶wiata przez dziaġajḟcego agenta; oraz istnienie wyraỳnej funkcji nagrody lub uṡyteczno¶ci, która charakteryzuje nasze wybory. Jednak siġḟ napêdowḟ tych formuġ problemów i technik jest czêsto zestaw zastosowañ docelowych, wiêc skuteczno¶æ tych zaġoṡeñ jest testowana i sprawdzana w udanych zastosowaniach. Dyskusja dzieli siê na podejmowanie decyzji w obszarach logicznych, zazwyczaj deterministycznych i podejmowanie decyzji w domenach o charakterze stochastycznym. Te pierwsze sḟ prostsze, wiêc moṡna do nich skutecznie podej¶æ pomimo czasami zġoṡonych struktur kombinatorycznych i zazwyczaj moṡna je rozwiḟzaæ w przypadku wiêkszych domen. Te ostatnie sḟ bardziej skomplikowane w podejmowaniu decyzji, dlatego wymagajḟ wielu zaġoṡeñ, ale sḟ równieṡ bardziej skuteczne i lepiej modelujḟ problemy, je¶li majḟ zastosowanie w praktyce. Póỳniej przyjrzymy siê pracy, która ma na celu poġḟczenie dwóch podej¶æ i mocnych stron ich metod.
Decyzje w logicznych przestrzeniach kombinatorycznych
Logiczne problemy decyzyjne to te, które majḟ charakter niestochastyczny. W tej czê¶ci omówiono dwa gġówne ustawienia takich problemów decyzyjnych: planowanie (jeden aktor lub wspóġpraca) i kontradyktoryjne (gġównie gry dwuosobowe). W obu ustawieniach dyskusja zakġada, ṡe mamy peġnḟ informacjê o poczḟtkowych i po¶rednich stanach ¶wiata, ṡe dziaġania majḟ jedynie deterministyczne, znane efekty i ṡe istnieje okre¶lony warunek celu (np. wygrana w grze lub pakiet bêdḟcy w okre¶lony pokój). Oba rodzaje problemów dotyczḟ aktualnych aplikacji w ¶wiecie rzeczywistym, takich jak misje kosmiczne NASA, sterowanie robotami, logistyka, oprogramowanie do gier i ¶wiata wirtualnego, zġoṡone zachowania w sieci WWW, weryfikacja oprogramowania oraz bezpieczeñstwo komputera i sieci. Ogólnie rzecz biorḟc, problem planowania obejmuje sytuacjê poczḟtkowḟ, warunek celu oraz zestaw dozwolonych dziaġañ lub przej¶æ miêdzy stanami. Wynikiem procesu planowania jest sekwencja lub zestaw dziaġañ, których prawidġowe wykonanie prowadzi wykonawcê ze stanu poczḟtkowego do stanu speġniajḟcego warunek celu. Rozwaṡmy scenariusz, w którym trzy bloki oznaczone A, B, C znajdujḟ siê na stole, a chwytak robota musi je podnie¶æ w odpowiedniej kolejno¶ci i odġoṡyæ tak, aby A byġ na B, a B na C. Prosta reprezentacja dla tego scenariusza nazywa siê STRIPS i skġada siê z listy warunków wstêpnych, Pre, listy usuwania, Del i listy dodawania, Add, dla kaṡdej akcji robota. Reprezentuje stan z zestawem faktów, które sḟ prawdziwe, i moṡliwymi dziaġaniami z takimi listami Pre, Add, Del. PASKI mogḟ reprezentowaæ scenariusz ¶wiata bloków za pomocḟ akcji pickUp (x, y) i putDown (x, y), gdzie x, y to bloki A, B, C lub Tabela. Na przykġad pickUp (x, y) moṡe mieæ Pre = on (x, y) ?handEmpty, Add = inHand (x) i Del = on (x, y), handEmpty. Intencjḟ tych operatorów i list jest scharakteryzowanie warunków wstêpnych i skutków tych dziaġañ. Efekt zmienia obecny stan poprzez dodanie i usuniêcie go. Kiedy stan ¶wiata to {on (A, Table), on (B, Table), on (C, Table) i Puste}, robot podnosi A ze stoġu, a nastêpnie A nie jest juṡ na stole, rêka robota nie jest juṡ pusta, a robot trzyma teraz blok A. W zwiḟzku z tym algorytm planowania aktualizuje stan za pomocḟ tej akcji, usuwajḟc (A, Tabela), usuwajḟc handEmpty i dodajḟc rêcznie (A) do opisu stanu . Stany i dziaġania okre¶lajḟ razem przestrzeñ wyszukiwania, w której naleṡy znaleỳæ plan. Plan w tej przestrzeni jest sekwencjḟ dziaġañ, która prowadzi ze stanu poczḟtkowego (w peġni okre¶lony) do stanu, który speġnia warunek celu. Planista (proces podejmowania decyzji) otrzymuje takḟ reprezentacjê dla problemu planowania i ma za zadanie znaleỳæ plan. W tym celu wykorzystuje róṡne metody wyszukiwania, które mogḟ siê róṡniæ w zaleṡno¶ci od domeny, i mogḟ obejmowaæ heurystykê ogólnego przeznaczenia, strategie wybiegania w przyszġo¶æ i wiedzê w dziedzinie. Planowanie jest trudne obliczeniowo nawet w przypadku prostych jêzyków specyfikacji problemów, takich jak powyṡszy. Poszukiwanie planu nie moṡe w praktyce reprezentowaæ ani przechodziæ przez caġy wykres przestrzeni stanu, poniewaṡ jest on wykġadniczo duṡy pod wzglêdem liczby cech stanu definiujḟcych domenê (np. Odpowiadajḟcych liczbie bloków w naszym przykġadzie powyṡej). Dlatego techniki wyszukiwania muszḟ tworzyæ czê¶ciowe ¶cieṡki w nadziei na osiḟgniêcie celu. Poszukiwanie takich planów polega na wycofaniu siê, gdy planista zdecyduje, ṡe nie ma sensu dalej rozszerzaæ planu i ṡe wcze¶niejsze kroki w planie muszḟ zostaæ zmienione, aby umoṡliwiæ osiḟgniêcie celu. Badania nad planowaniem koncentrujḟ siê na opracowaniu nowych metod wyszukiwania, nowych reprezentacji dziaġañ i stanów, które uġatwiajḟ planowanie oraz bardziej ekspresyjnych jêzyków i metod specyfikacji problemów planowania. Na przykġad wiele algorytmów planowania wykorzystuje zaġoṡenia niezaleṡno¶ci lub luỳne interakcje miêdzy komponentami w dziedzinie planowania, aby efektywniej wyszukiwaæ plany. Hierarchiczni plani¶ci dzielḟ cel na podzadania (operatory wysokiego poziomu), wykorzystujḟc rozkġad domeny na luỳno oddziaġujḟce czê¶ci. Planowanie odbywa siê na kaṡdym poziomie osobno, a nastêpnie plany podrzêdne sḟ skġadane razem, aby zbudowaæ prawidġowy plan. Podejmowanie decyzji, gdy istniejḟ siġy, które próbujḟ negatywnie wpġynḟæ na nasz wynik, jest tematem teorii gier. Tutaj zadaniem decydenta jest maksymalizacja zysku lub szans na sukces przy jednoczesnym zminimalizowaniu negatywnego efektu decyzji podejmowanych przez innych. Sytuacja ta jest typowa dla gier planszowych dla dwóch graczy (np. Szachy, go itd.), A takṡe jest istotna dla minimalizacji wad w projektach (np. Oprogramowania i sprzêtu) oraz dla bezpieczeñstwa (np. komputerów i sieci). Minimax jest prostym modelem do podejmowania takich decyzji w sytuacjach dwuosobowych. Decydent wykorzystuje informacje heurystyczne o warto¶ci stanów (wedġug ich przyszġych wyników), aby oszacowaæ warto¶æ decyzji w obecnym stanie. Na przykġad w szachach poruszamy pionek szachowy, drugi gracz przesuwa kawaġek wġasny i dochodzimy do nowego stanu gry, który wymaga kolejnej decyzji. Kaṡda nasza decyzja prowadzi do jednego z kilku stanów, podobnie jak decyzja przeciwnika. Moṡemy nakre¶liæ wszystkie moṡliwe przyszġe stany kolejnych kroków, patrzḟc na te stany osiḟgalne z naszego obecnego stanu poprzez szereg moṡliwych wyborów przez nas i naszego przeciwnika. Wygodnie jest umie¶ciæ te poszczególne stany w drzewie, przy czym stan obecny jest korzeniem tego drzewa (najwyṡszy wêzeġ w drzewie), a li¶cie drzewa sḟ najniṡszymi wêzġami w drzewie. (Mówiḟc bardziej ogólnie, gaġêzie drzewa mogḟ siê ġḟczyæ, ale ignorujemy to, aby upro¶ciæ dyskusjê.) W minimax obliczamy warto¶ci wyṡszych wêzġów zgodnie z tym drzewem w sposób min-max. Poziom drzewa wynosi min (minimalizacja), je¶li przeciwnik podejmie decyzjê w tych stanach, poniewaṡ jego celem jest doprowadzenie do stanów, które minimalizujḟ nasz wynik. Poziom drzewa jest maksymalny (maksymalny), je¶li to my podejmujemy decyzjê w tych stanach, poniewaṡ naszym celem jest doprowadzenie do stanów, które maksymalizujḟ nasz wynik. Ilustruje to rysunek
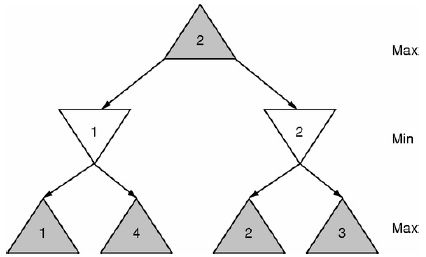
Na tym rysunku liczby u doġu drzewa oznaczajḟ warto¶ci, które gracze oszacowaliby za bycie w tym stanie (na przykġad za pomocḟ heurystycznego function), a kaṡdy gracz wybiera dziaġania, które minimalizujḟ lub maksymalizujḟ warto¶ci otrzymane od doġu. Prawdopodobnie poprawne metody usuwajḟ gaġêzie z drzewa minimax, je¶li nie ma szansy, ṡe przyczyniḟ siê do rozwiḟzania (tj. Preferencji w¶ród wyṡszych gaġêzi). Najnowsze badania próbujḟ oszacowaæ warto¶æ stanu poprzez próbkowanie sub-drzew tego drzewo min - maks. Wyzwaniem dla przeciwnych decyzji jest wywaṡenie uczenia siê i decyzji. Gdy przeciwnik próbuje zablokowaæ nasze próby, nauka domeny podczas podejmowania decyzji (np. Poprzez naukê wzmacniajḟcḟ) jest trudna, poniewaṡ eksploracja w celu uczenia siê moṡe doprowadziæ nas do bardzo zġych wyników. Musimy zrównowaṡyæ prawdopodobieñstwo pozyskania cennych informacji z eksploracji z ryzykiem cofniêcia siê przez naszych przeciwników. Jednak unikanie eksploracji z pewno¶ciḟ przyniesie nieoptymalne wyniki, które mogḟ byæ bardzo dalekie od poṡḟdanych lub akceptowalnych.
Domeny stochastyczne
Wiele domen ¶wiata rzeczywistego ma dynamikê, która ewoluuje stochastycznie, to znaczy z pewnymi nietrywialnymi wġa¶ciwo¶ciami statystycznymi. Na przykġad moṡemy rozwaṡyæ zakup samochodu, który ma wġa¶ciwo¶ci, które nie sḟ nam znane i wpġywajḟ na jego warto¶æ. Te zaleṡno¶ci wpġywajḟ na naszḟ decyzjê i musimy oceniæ naszḟ uṡyteczno¶æ, biorḟc pod uwagê wszystkie ryzyka i niepewno¶ci. Domeny stochastyczne sḟ trudniejsze w podejmowaniu decyzji w praktyce, ale sḟ takṡe bardziej tolerancyjne dla przybliṡeñ niṡ domeny deterministyczne. Uproszczenie zaġoṡeñ, które zostaġy poczynione w praktyce, pozwala na automatyczne podejmowanie decyzji. Istnieje kilka sformuġowañ problemów, które wychwytujḟ róṡne aspekty i przypadki podejmowania decyzji w domenach stochastycznych. Najwaṡniejsze z nich to sieci decyzyjne i procesy decyzyjne Markowa (MDP). Sieci decyzyjne sḟ podobne do sieci bayesowskich tylko z trzema typami wêzġów: (1) zmienne losowe (jak w sieci bayesowskiej), (2) wêzġy decyzyjne i (3) wêzġy uṡyteczno¶ci. Wêzġy decyzyjne wymagajḟ przypisania decyzji co do ich warto¶ci i nie majḟ rzḟdzḟcego nimi rozkġadu prawdopodobieñstwa (warto¶ci dla innych wêzġów mogḟ zaleṡeæ stochastycznie od warto¶ci przypisanej do wêzġów decyzyjnych). Wêzġy uṡytkowe oznaczajḟ ilo¶ci, które chcemy zmaksymalizowaæ (w oczekiwaniu). MDP sḟ najbardziej popularnym formalizmem do modelowania zadañ decyzyjnych w dynamicznych ¶rodowiskach stochastycznych. Ich celem jest modelowanie sytuacji, w których dziaġania majḟ efekty stochastyczne, a ich cel nie jest konkretnym celem, ale raczej maksymalizuje uṡyteczno¶æ w czasie. Rozwiḟzania MDP to zasady, które wybierajḟ akcjê dla kaṡdego stanu, tak aby caġkowity koszt oczekiwanych dziaġañ zostaġ zminimalizowany, a ġḟczna suma lub dodatnie korzy¶ci zostaġy zmaksymalizowane.
Zagadnienia przekrojowe
Rozumowanie oparte na zdrowym rozsḟdku
Terminy "rozumowanie zdrowego rozsḟdku" i "wiedza zdrowego rozsḟdku" odnoszḟ siê do szerokiego zestawu umiejêtno¶ci, które ludzie wnoszḟ w podejmowanie decyzji i my¶lenie. Jednym z przykġadów jest umiejêtno¶æ rozumowania o bardzo duṡej liczbie przedmiotów, wġa¶ciwo¶ci, ludzi i relacji w naszym codziennym ṡyciu. Moṡemy stwierdziæ, ṡe kubek moṡe utrzymaæ swojḟ zawarto¶æ, ale tylko wtedy, gdy kubek jest skierowany do góry lub zawarto¶æ jest bezpiecznie poġḟczona z kubkiem. Moṡemy wykorzystaæ ten fakt przy podejmowaniu decyzji o sposobach transportu kubka z jednego miejsca do drugiego. Badania nad zdrowym rozsḟdkiem starajḟ siê wyposaṡyæ aplikacje i komputery w tê zdolno¶æ do generalizowania, uczenia siê i korzystania z bardzo szerokiego zestawu wiedzy na temat codziennego ṡycia. Obecnie praktyczne zastosowania omijajḟ wiele problemów zwiḟzanych z rozsḟdnym rozumowaniem. Robiḟ to, starannie opracowujḟc potrzebne informacje i modele, ograniczajḟc zestaw tematów i zmiennych podczas uczenia siê i opracowywania tylko tych aplikacji, które nie wymagajḟ tak zdrowego rozsḟdku. Badania nad rozumowaniem opartym na zdrowym rozsḟdku sḟ podzielone na trzy gġówne nurty: teoria logiczna, duṡe podstawy wiedzy o zdrowym rozsḟdku i techniki rozumowania zwykġego ad hoc. Logiczna formalizacja i teoria rozumowania opartego na zdrowym rozsḟdku próbuje wykorzystywaæ i modyfikowaæ logikê do reprezentowania i rozumowania za pomocḟ wiedzy opartej na zdrowym rozsḟdku w sposób zgodny z naszymi intuicjami na temat takiego rozumowania. Na przykġad wiele ludzkich rozumowañ na temat ¶wiata uṡywa pojêcia domy¶lnych - zaġoṡeñ, które sḟ uṡyteczne, ale mogḟ nie byæ prawdziwe. Mówimy, ṡe ptaki latajḟ (niektóre nie); zakġadamy, ṡe nasz komputer dziaġa poprawnie (moṡe nie byæ); i postêpujemy zgodnie z zaleceniami lekarzy (mogḟ byæ niepoprawni). Takie niepewno¶ci i niewykonanie zobowiḟzañ nie sḟ tak samo wychwytywane przez logikê. Rozumowanie niemonotoniczne próbuje uogólniæ je na formê uṡytecznego rozumowania opartego na zdrowym rozsḟdku. Takie logiki wychwytujḟ jednḟ wġa¶ciwo¶æ potrzebnḟ do rozsḟdnego rozumowania, a mianowicie zdolno¶æ do reprezentowania warto¶ci domy¶lnych i rozumowania ich. Pozostaje jednak wiele do zrobienia: w jaki sposób moṡemy zdobyæ wiedzê, w jaki sposób skalujemy techniki reprezentacji i wnioskowania do duṡego zestawu wiedzy, który wydaje siê potrzebny, i w jaki sposób wykorzystujemy tê wiedzê w aplikacjach, które jej potrzebujḟ? Wysiġki na rzecz budowania duṡych baz wiedzy i wykorzystywania informacji w nowy sposób starajḟ siê przezwyciêṡyæ ograniczenia logicznego rozumowania opartego na zdrowym rozsḟdku. Na przykġad Cyc, najbardziej znana obecnie duṡa baza wiedzy opartej na zdrowym rozsḟdku, jest wynikiem ponad dwudziestu piêciu lat rozwoju i utrzymania przez ekspertów. Zawiera ponad 1 000 000 faktów i zdañ logicznych na temat ponad 100 000 obiektów, relacji, typów i funkcji. Jego semantyka nie jest tak prosta i przejrzysta, jak sugerowana w literaturze dotyczḟcej formuġ logicznych, ale wydaje siê, ṡe w rezultacie jest bardziej uṡyteczna (poczḟtkowe zastosowania istniejḟ w przetwarzaniu jêzyka naturalnego i podejmowaniu decyzji). Inne wysiġki podejmowane sḟ w celu automatycznego tworzenia wiedzy na podstawie autorów i mas informacji dostêpnych w Internecie. Celem jest ġatwiejsze tworzenie systemów o szerokiej wiedzy, ale z moṡliwie luỳniejszḟ semantykḟ. Podej¶cia te unikajḟ rozwaṡania pytañ dotyczḟcych znaczenia posiadanej wiedzy i wydajḟ siê obiecujḟce dla aplikacji wymagajḟcych szerokiej wiedzy (np. Autonomiczne roboty rzeczywiste i wirtualne).
Poġḟczenie logiki i prawdopodobieñstwa
Wiele aplikacji ma zarówno elementy stochastyczne, jak i niestochastyczne. Na przykġad sterowanie robotem moṡe obejmowaæ specyfikacje wysokiego poziomu w logice i probabilistyczny model wykrywania niṡszego poziomu. Ponadto przetwarzanie jêzyka naturalnego ma na celu zastosowanie wiedzy wysokiego poziomu w logice z niṡszymi modelami probabilistycznymi sygnaġów tekstowych i mówionych. Wreszcie, wiele baz danych jest opartych na logice, podczas gdy relacje miêdzy tymi bazami danych a najnowszymi rozszerzeniami do baz danych sḟ probabilistyczne (np. Wpis John, Mary jest niepewnym wpisem w bazie danych uwielbia z prawdopodobieñstwem 0,7 albo dlatego, ṡe John jest niepewny, albo dlatego, ṡe posiadacze bazy danych nie sḟ pewni). Od 1990 r. W ¶rodowisku sztucznej inteligencji i spoġeczno¶ci baz danych jest wiele pracy nad poġḟczeniem ekspresji logicznej i probabilistycznej. W pracy przedstawiono jêzyki, które mogḟ wyraṡaæ rozkġady prawdopodobieñstwa wraz z wyraỳnymi odniesieniami do obiektów, funkcji i relacji, jak w logice pierwszego rzêdu. Te jêzyki stanowiḟ przydatne ramy dla wielu aplikacji uczenia maszynowego, a ostatnie prace pokazujḟ równieṡ, ṡe sḟ przydatne dla wydajno¶ci obliczeniowej wnioskowania. Trwajḟ badania nad kombinacjḟ logiki i prawdopodobieñstwa. Obecne wyzwania obejmujḟ (1) zastosowanie struktury relacyjnej w celu przyspieszenia wnioskowania i leczenia modeli probabilistycznych na wielu obiektach, (2) poġḟczenie baz wiedzy, które sḟ juṡ podane w postaci probabilistycznej lub logicznej, oraz (3) rozszerzenie jêzyków reprezentacji o funkcje i równo¶æ obiekty w dỳwiêku i proste sposoby.
Czê¶ciowa obserwowalno¶æ
Agenci dziaġajḟcy w wielu rzeczywistych domenach nie znajḟ dokġadnego stanu ¶wiata w ṡadnym momencie. Domeny te sḟ czê¶ciowo obserwowalne, poniewaṡ agenci nie mogḟ obserwowaæ wszystkich cech ¶wiata, które mogḟ byæ dla nich istotne. Na przykġad agent przeglḟdajḟcy strony WWW moṡe nacisnḟæ przycisk na stronie, ale moṡe nie zobaczyæ natychmiastowego efektu jego dziaġania (ale moṡe go zobaczyæ, je¶li obejrzaġ innḟ stronê). Problemy zwiḟzane z czê¶ciowḟ obserwowalno¶ciḟ sḟ szczególnie trudne, i ograniczone zazwyczaj do bardzo maġych domen (np. 100 stanów lub 8 funkcji domenowych). Wynika to z faktu, ṡe kaṡdy wybór dziaġania zaleṡy od stanu wiedzy agenta i odbieranych przez niego spostrzeṡeñ, co prowadzi do obliczeñ nadwykġadniczych w liczbie kroków i funkcji w domenie. Dziaġanie w czê¶ciowo obserwowalnych, czê¶ciowo znanych domenach jest szczególnie trudne, a jednak najbliṡsze prawdziwemu ṡyciu. Gġówne podej¶cia obejmujḟ co najmniej wyczerpujḟce badanie domeny lub porady na temat obiecujḟcych trajektorii. Podej¶cia, które gwarantujḟ zbieṡno¶æ z rozwiḟzaniem, robiḟ to tylko w nieskoñczonej liczbie kroków. Co najwaṡniejsze, je¶li zmieni siê cel systemu, proces musi zostaæ zrestartowany, a wiedza zgromadzona w poprzednich uruchomieniach jest maġo wykorzystywana. Najnowsze podej¶cia identyfikujḟ waṡne moṡliwe do prze¶ladowania przypadki o szczególnym znaczeniu - na przykġad dziedziny, w których dziaġania sḟ znane jako deterministyczne i pozbawione efektów warunkowych (np. Dziaġania STRIPS. Takie algorytmy przeplatajḟ planowanie i wykonanie oraz zapewniajḟ pewne gwarancje osiḟgniêcia celu w ramach niemal optymalnej liczby kroków.
Aplikacje nie programujḟ
Dominujḟcy poglḟd w badaniach naukowych sugeruje, ṡe rzeczywiste zastosowania sḟ prostymi implementacjami teorii i badañ podstawowych. Sztuczna inteligencja i podejmowanie decyzji w szczególno¶ci sḟ sprzeczne z tym poglḟdem. Przetwarzanie jêzyka naturalnego, widzenie maszynowe i wykrywanie oszustw to tylko niektóre aplikacje, które moṡna postrzegaæ w sposób abstrakcyjny jako aplikacje badañ podstawowych. Mimo to te tematy wymagaġy i otrzymywaġy (i nadal otrzymujḟ) duṡḟ specjalistycznḟ uwagê, zanim mogġy zostaæ wprowadzone w ṡycie. Mówiḟc bardziej ogólnie, teoretycznie naleṡy umieæ przedstawiæ wszystko, co jest potrzebne do inteligentnego zachowania w FOL. Wynika to z faktu, ṡe FOL odpowiada mocy reprezentacyjnej maszynom Turinga2 (dominujḟcy abstrakcyjny model obliczeñ). Podczas gdy sztuczna inteligencja na poziomie ludzkim w FOL jest teoretycznie moṡliwa (poniewaṡ je¶li dowolny komputer moṡe to zrobiæ, to FOL moṡe), w praktyce niewiele moṡna zyskaæ unikajḟc problemu, jak faktycznie reprezentowaæ wiedzê lub rozum w FOL lub innym jêzyku. Problemów zwiḟzanych z faktycznym budowaniem potrzebnej wiedzy i wykorzystywaniem jej w praktyce nie da siê uniknḟæ, je¶li chcemy osiḟgnḟæ praktyczne inteligentne aplikacje na poziomie czġowieka. Diabeġ tkwi w szczegóġach i bez zwracania uwagi na te szczegóġy badania przyniosḟ niewielkie postêpy, co zaobserwowano w licznych gaġêziach AI, które rozwijaġy siê w czasie (Formalna Weryfikacja i Bazy Danych to dwie dziedziny, które rozgaġêziġy siê na AI).
Wnioski
Od poġowy lat 90. w KR&R nastḟpiġa znaczna zmiana orientacji z narzêdzi matematyczno-logicznych na narzêdzia teorii prawdopodobieñstwa i z teorii na zastosowania. Ta zmiana byġa gwaġtowna, co doprowadziġo do podziaġu badañ na pracê opartḟ na logice i prawdopodobieñstwie. Logika jest wygodniejsza do reprezentowania wiedzy sentymentalnej (szczególnie relacyjnej, opartej na obiektach) i jest dobrze dostosowana do problemów i struktur kombinatorycznych (niewypukġych), takich jak wyszukiwanie w labiryncie lub rozwiḟzywanie zagadek, podczas gdy podej¶cia oparte na prawdopodobieñstwie (w szczególno¶ci , graficzne modele probabilistyczne) lepiej przedstawiajḟ niepewnḟ wiedzê, lepiej nadajḟ siê do uczenia siê w obecno¶ci haġasu i majḟ wiele rzeczywistych zastosowañ (zgodnie z zasadḟ 80-20 - wykonuj 20% pracy dla ġatwiejszego 80% Praca). Rozumowanie i podejmowanie decyzji przy kaṡdym przedstawicielstwie jest ġatwiejsze lub trudniejsze w róṡnych sytuacjach i zazwyczaj ich zalety wydajḟ siê komplementarne (np. rozwiḟzywanie problemów logicznej satysfakcji jest czêsto szybkie, podczas gdy rozumowanie probabilistyczne jest ġatwe do przybliṡenia). Wielu badaczy zgadza siê, ṡe oba narzêdzia (logika i prawdopodobieñstwo) sḟ niezbêdne do skalowania systemów do rzeczywistych aplikacji, ale sposób ġḟczenia ich mocnych stron pozostaje niejasny. Ponadto badania dotyczḟce uczenia maszynowego i wnioskowania osiḟgnêġy punkt gdzie ma wiele praktycznych zastosowañ. Obecne badania sḟ bardziej zorientowane na aplikacje, a trend ten rejestruje lepsze ukierunkowanie i sukcesy w ¶wiecie rzeczywistym. Pojawienie siê W WW i udanych wyszukiwarek dostarczyġo innego rodzaju siġy decyzyjnej, gdzie siġa kolektywu pomaga uniknḟæ trudnych problemów teoretycznych. Zmiany te tworzḟ odmienne ¶rodowisko badawcze i kierunki uzasadnienia i podejmowania decyzji. Te nowe kierunki bêdḟ oddziaġywaæ z rozwojem teorii gier, neurobiologii i innych dziedzin naukowych, których tu nie poruszono.